在高效C++編程中看到一個不錯的內存池實現方案,這裡共享下,大家看看有什麼不足。
代碼很簡單,如下:
template<typename T>
class CMemoryPool
{
public:
enum { EXPANSION_SIZE = 32};
CMemoryPool(unsigned int nItemCount = EXPANSION_SIZE)
{
ExpandFreeList(nItemCount);
}
~CMemoryPool()
{
//free all memory in the list
CMemoryPool<T>* pNext = NULL;
for(pNext = m_pFreeList; pNext != NULL; pNext = m_pFreeList)
{
m_pFreeList = m_pFreeList->m_pFreeList;
delete [](char*)pNext;
}
}
void* Alloc(unsigned int /*size*/)
{
if(m_pFreeList == NULL)
{
ExpandFreeList();
}
//get free memory from head
CMemoryPool<T>* pHead = m_pFreeList;
m_pFreeList = m_pFreeList->m_pFreeList;
return pHead;
}
void Free(void* p)
{
//push the free memory back to list
CMemoryPool<T>* pHead = static_cast<CMemoryPool<T>*>(p);
pHead->m_pFreeList = m_pFreeList;
m_pFreeList = pHead;
}
protected:
//allocate memory and push to the list
void ExpandFreeList(unsigned nItemCount = EXPANSION_SIZE)
{
unsigned int nSize = sizeof(T) > sizeof(CMemoryPool<T>*) ? sizeof(T) : sizeof(CMemoryPool<T>*);
CMemoryPool<T>* pLastItem = static_cast<CMemoryPool<T>*>(static_cast<void*>(new char[nSize]));
m_pFreeList = pLastItem;
for(int i=0; i<nItemCount-1; ++i)
{
pLastItem->m_pFreeList = static_cast<CMemoryPool<T>*>(static_cast<void*>(new char[nSize]));
pLastItem = pLastItem->m_pFreeList;
}
pLastItem->m_pFreeList = NULL;
}
private:
CMemoryPool<T>* m_pFreeList;
};
它的實現思想就是每次從List的頭上取內存, 如果取不到則重新分配一定數量; 用完後把內存放回List頭部,這樣的話效率很高,因為每次List上可以取到的話,肯定是空閒的內存。
當然上面的代碼只是針對單線程的,要支持多線程的話也很簡單,外面加一層就可以了,
代碼如下:
class CCriticalSection
{
public:
CCriticalSection()
{
InitializeCriticalSection(&m_cs);
}
~CCriticalSection()
{
DeleteCriticalSection(&m_cs);
}
void Lock()
{
EnterCriticalSection(&m_cs);
}
void Unlock()
{
LeaveCriticalSection(&m_cs);
}
protected:
CRITICAL_SECTION m_cs;
};
template<typename POOLTYPE, typename LOCKTYPE>
class CMTMemoryPool
{
public:
void* Alloc(unsigned int size)
{
void* p = NULL;
m_lock.Lock();
p = m_pool.Alloc(size);
m_lock.Unlock();
return p;
}
void Free(void* p)
{
m_lock.Lock();
m_pool.Free(p);
m_lock.Unlock();
}
private:
POOLTYPE m_pool;
LOCKTYPE m_lock;
};
這是我的測試代碼:
#include <iostream>
#include <windows.h>
using namespace std;
#include "MemoryPool.h"
#include "MTMemoryPool.h"
class CTest
{
public:
int m_n;
int m_n1;
void* operator new(size_t size)
{
void* p = s_pool->Alloc(size);
return p;
}
void operator delete(void* p, size_t size)
{
s_pool->Free(p);
}
static void NewPool()
{
//s_pool = new CMemoryPool<CTest>;
s_pool = new CMTMemoryPool<CMemoryPool<CTest>, CCriticalSection>;
}
static void DeletePool()
{
delete s_pool;
s_pool = NULL;
}
//static CMemoryPool<CTest>* s_pool;
static CMTMemoryPool<CMemoryPool<CTest>, CCriticalSection>* s_pool;
};
//CMemoryPool<CTest>* CTest::s_pool = NULL;
CMTMemoryPool<CMemoryPool<CTest>, CCriticalSection>* CTest::s_pool = NULL;
void testFun()
{
int i;
const int nLoop = 10;
const int nCount = 10000;
for(int j = 0; j<nLoop; ++j)
{
typedef CTest* LPTest;
LPTest arData[nCount];
for(i=0;i <nCount; ++i)
{
arData[i] = new CTest;
}
for(i=0;i <nCount; ++i)
{
delete arData[i];
}
}
}
int main(int argc, char* argv[])
{
{
unsigned int dwStartTickCount = GetTickCount();
CTest::NewPool();
testFun();
CTest::DeletePool();
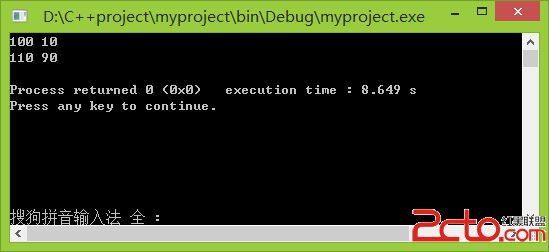
cout << "total cost" << GetTickCount() - dwStartTickCount << endl;
}
system("pause");
return 0;
}
在我機器上測試結果比系統默認的CRT實現高效N倍。
摘自 厚積薄發