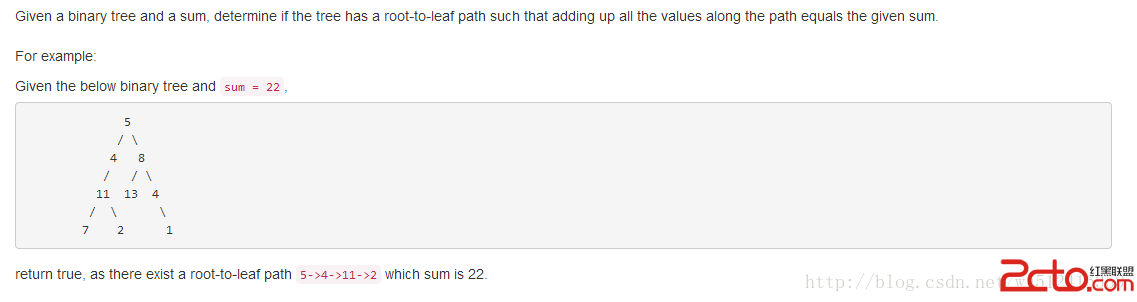
廢話不多說,上代碼:
[cpp]
#include <iostream>
#include <string>
#include <windows.h>
using namespace std;
class CEncodeString
{
public:
CEncodeString();
~CEncodeString();
void LoadString(char *,int =ansi);
void LoadString(WCHAR *);
enum{ansi,unicode,utf8};
wstring ToUnicode();
string ToAnsi();
string ToUtf8();
string GetUnicodeHeader();
string GetUtf8Header();
private:
string m_str;
};
CEncodeString::CEncodeString()
{
}
CEncodeString::~CEncodeString()
{
}
void CEncodeString::LoadString(char *str,int mode/* =ansi */)
{
if(mode==ansi)
{
string strTemp;
strTemp+=str[0];
strTemp+=str[1];
if(strTemp==GetUnicodeHeader())
{
LoadString((WCHAR*)(str+2));
return;
}
strTemp+=str[2];
if(strTemp==GetUtf8Header())
{
str+=3;
mode=utf8;
}
else
{
m_str=str;
}
}
if(mode==utf8)
{
int wcsLen = ::MultiByteToWideChar(CP_UTF8, NULL, str, strlen(str), NULL, 0);
wchar_t* wszString = new wchar_t[wcsLen + 1];
::MultiByteToWideChar(CP_UTF8, NULL, str, strlen(str), wszString, wcsLen);
wszString[wcsLen] = '\0';
int ansiLen = ::WideCharToMultiByte(CP_ACP, NULL, wszString, wcslen(wszString), NULL, 0, NULL, NULL);
char* szAnsi = new char[ansiLen + 1];
::WideCharToMultiByte(CP_ACP, NULL, wszString, wcslen(wszString), szAnsi, ansiLen, NULL, NULL);
szAnsi[ansiLen] = '\0';
m_str=szAnsi;
delete[] wszString;
delete[] szAnsi;
}
}
void CEncodeString::LoadString(WCHAR *wStr)
{
int ansiLen = ::WideCharToMultiByte(CP_ACP, NULL, wStr, wcslen(wStr), NULL, 0, NULL, NULL);
char* szAnsi = new char[ansiLen + 1];
::WideCharToMultiByte(CP_ACP, NULL, wStr, wcslen(wStr), szAnsi, ansiLen, NULL, NULL);
szAnsi[ansiLen] = '\0';
m_str=szAnsi;
delete[] szAnsi;
}
wstring CEncodeString::ToUnicode()
{
char* szAnsi =(char*)m_str.data();
int wcsLen = ::MultiByteToWideChar(CP_ACP, NULL, szAnsi, strlen(szAnsi), NULL, 0);
wchar_t* wszString = new wchar_t[wcsLen + 1];
::MultiByteToWideChar(CP_ACP, NULL, szAnsi, strlen(szAnsi), wszString, wcsLen);
wszString[wcsLen] = '\0';
wstring wStr=wszString;
delete[] wszString;
return wStr;
}
string CEncodeString::ToAnsi()
{
return m_str;
}
string CEncodeString::ToUtf8()
{
wstring wStr=ToUnicode();
wchar_t* wszString =(wchar_t*) wStr.data();
int u8Len = ::WideCharToMultiByte(CP_UTF8, NULL, wszString, wcslen(wszString), NULL, 0, NULL, NULL);
char* szU8 = new char[u8Len + 1];
::WideCharToMultiByte(CP_UTF8, NULL, wszString, wcslen(wszString), szU8, u8Len, NULL, NULL);
szU8[u8Len] = '\0';
string strUtf8=szU8;
delete[] szU8;
return strUtf8;
}
string CEncodeString::GetUnicodeHeader()
{
return "\xff\xfe";
}
string CEncodeString::GetUtf8Header()
{
return "\xef\xbb\xbf";
}
main()
{
setlocale(LC_CTYPE, "");
FILE *f=fopen("d:\\json.txt","rb");
char buf[100]={0};
fread(buf,1,100,f);
fclose(f);
CEncodeString encode;
encode.LoadString(buf);
cout<<encode.ToAnsi()<<endl;
}
這個類會自動解析字符串的頭信息,判斷是否為unicode還是utf8還是ansi,然後會做相應的處理,當然字符串在類中的儲存方式都是ansi的。
本文由不足之處,還望大家多多指正。