我一開始就直接復制了其中的Python代碼,正如我評論那篇文章的那樣
這個Pytrhon代碼不知道起源在在哪?P.S.網上的有太多的信息冗余,以及copied轉載得文章。但是作者在轉載的時候,沒有check文章中的代碼是否正確。 www.2cto.com
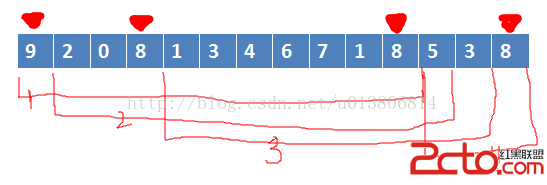
distance_matrix 沒有初始化正確。
應該初始化為:
0,1,2,3,4
1,
2,
3,
====================================================================================================
因為要使用編輯距離,且不是Python代碼中。使用的方式,可能是在shell中每次計算都要調用python xx.py string1 string2。
這樣每次計算都要執行一天python命令,調用大概18000次,就需要5分鐘左右。效率無法忍受。
一開始以為是計算的過程耗時,采用動態規劃但是時間復雜度還是string1.length * string2.length,空間復雜度也相同。
後來采用一個簡單的處理方式,就是不計算 編輯距離,而是計算common_prefix,結果發現跑18000次python命令的時間還是5分鐘很長。(有時間需要研究一下,運行python xx.py的過程以及耗時)
所以,就考慮使用C++寫代碼。(還沒有測試效率怎樣)
然後,就有了上篇關於gcc 和VS 2010中分別有 sizeof(wchar_t) ==4 和 sizeof(wchar_t) == 2,使用 setlocle也沒有作用。
下面就是C++處理中文的編輯距離,和common_prefix
[cpp]
#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <string>
#include <cstring>
#include <wchar.h>
#include <typeinfo>
using namespace std;
inline wchar_t* MBCS2Unicode(wchar_t* buff,const char * str)
{
wchar_t * wp = buff;
const char * p = str;
while(*p)
{
*wp = (wchar_t) 0x0;
if(*p & 0x80)
{
//因為sizeof(wchar_t) 在linux為4
//所以需要trick處理一下
char temp[sizeof(wchar_t)];
temp[0] = *p;
p++;
temp[1] = *p;
for(int i = 2; i < sizeof(wchar_t); i++)
temp[i] = 0x0;
*wp = *(wchar_t *)temp;
}
else{
*wp = (wchar_t) *p;
}
wp++;
p++;
}
*wp = 0x00000000;
return buff;
}
inline wstring str2wstr(char* str)
{
size_t len = strlen(str);
wchar_t* b = (wchar_t *)malloc((len+1)*sizeof(wchar_t));
MBCS2Unicode(b, str);
wstring r(b);
free(b);
return r;
}
int common_prefix(const wstring& s1, const wstring& s2) {
int common_prefix = 0;
for(int i = 0, j = 0; i < s1.length() && j < s2.length() ; i++, j++) {
if(s1[i] == s2[j]) {
common_prefix++;
}
else {
break;
}
}
return common_prefix;
}
//''' 【編輯距離算法】 【levenshtein distance】 【字符串相似度算法】 '''
int levenshtein(const wstring& s1, const wstring& s2) {
if(s1.length() == 0 ) {
return s2.length();
}
if(s2.length() == 0 ) {
return s1.length();
}
int** distance_matrix = new int*[s1.length() + 1];
for(int row = 0; row <= s1.length() ; row++ ) {
distance_matrix[row] = new int[s2.length() + 1];
distance_matrix[row][0] = row;
}
for(int col = 0; col <= s2.length() ; col++ ) {
distance_matrix[0][col] = col;
}
for(int i = 1; i <= s1.length() ; i++ ) {
for(int j = 1; j <= s2.length() ; j++ ) {
int deletion = distance_matrix[i-1][j] + 1;
int insertion = distance_matrix[i][j-1] + 1;
int substitution = distance_matrix[i-1][j-1] + (s1[i - 1] == s2[j - 1]? 0:1);
distance_matrix[i][j] = min(insertion, min(deletion, substitution));
}
}
for(int row = 0; row < s1.length() ; row++ ) {
delete[] distance_matrix[row];
}
delete[] distance_matrix;
return distance_matrix[s1.length()][s2.length()];
}
int main(int argc, char* argv[]) {
setlocale(LC_ALL,"Chinese-simplified");
if( argc != 3 ) {
cout << "Usage: ./common_prefix string1 string2" << endl;
return -1;
}
wstring s1 = str2wstr(argv[1]);
wstring s2 = str2wstr(argv[2]);
cout << common_prefix(s1, s2) << endl;
cout << levenshtein(s1, s2) << endl;
return 0;
}