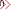1.統計文本中漢字的頻數,為後續的文本分類做基礎。對於漢字的統計,需要判斷讀取的是否為漢字。源代碼如下:
[C++ code]
[cpp]
/*
*@author:鄭海波 http://blog.csdn.net/NUPTboyZHB
*參考:實驗室小熊
*注:有刪改
*/
#pragma warning(disable:4786)
#include <iostream>
#include <vector>
#include <fstream>
#include <string>
#include <map>
#include <queue>
#include <ctime>
using namespace std;
void topK(const int &K)
{
double t=clock();
ifstream infile("test.txt");
if (!infile)
cout<<"can not open file"<<endl;
string s="";
map<string,int>wordcount;
unsigned char temp[2];
while(true)//國標2312
{
infile>>temp[0];
if(infile.eof()) break;
if (temp[0]>=0xB0)//GB2312下的漢字,最小是0XB0
{
s+=temp[0];
infile>>temp[1];
s+=temp[1];
}
else//非漢字字符不統計
{
s="";
continue;
}
wordcount[s]++;
s="";
}
cout<<"單詞種類:"<<wordcount.size()<<endl;
//優先隊列使用小頂堆,排在前面的數量少,使用">";
priority_queue< pair< int,string >,vector< pair< int,string > >,greater< pair< int,string> > > queueK;
for (map<string,int>::iterator iter=wordcount.begin(); iter!=wordcount.end(); iter++)
{
queueK.push(make_pair(iter->second,iter->first));
if(queueK.size()>K)
queueK.pop();
}
pair<int,string>tmp;
//將排在後面的數量少,排在前面的數量多
priority_queue< pair< int,string >,vector< pair< int,string > >,less< pair< int,string> > > queueKless;
while (!queueK.empty())
{
tmp=queueK.top();
queueK.pop();
queueKless.push(tmp);
}
while(!queueKless.empty())
{
tmp=queueKless.top();
queueKless.pop();
cout<<tmp.second<<"\t"<<tmp.first<<endl;
}
cout<<"< Elapsed Time: "<<(clock()-t)/CLOCKS_PER_SEC<<" s>"<<endl;
}
int main()
{
int k=0;
cout<<"http://blog.csdn.net/NUPTboyZHB\n";
while (true)
{
cout<<"查看前K個頻率最高的漢字,K=";
cin>>k;
if(k<=0)break;
topK(k);
}
return 0;
}
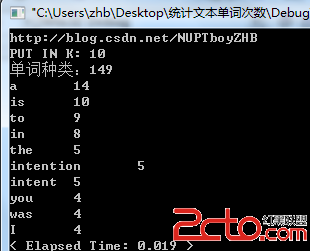
[圖1]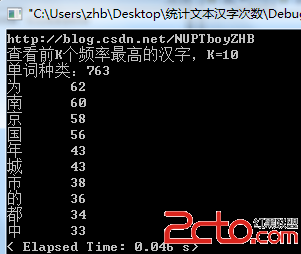 2.統計英文單詞的出現頻率。這比統計漢字更加的容易,因為單詞和單詞之間是用空格分開的,所以,直接將單詞保存到string中即可。
[c++ code]
[cpp]
/*
*@author:鄭海波 http://blog.csdn.net/NUPTboyZHB
*參考:實驗室小熊
*注:有刪改
*/
#pragma warning(disable:4786)
#include <iostream>
#include <vector>
#include <fstream>
#include <string>
#include <map>
#include <queue>
#include <ctime>
using namespace std;
void topK(const int &K)
{
double t=clock();
ifstream infile;
infile.open("test.txt");
if (!infile)
cout<<"can not open file"<<endl;
string s;
map<string,int>wordcount;
while(true)
{
infile>>s;
if(infile.eof()) break;
wordcount[s]++;
}
cout<<"單詞種類:"<<wordcount.size()<<endl;
//優先隊列使用小頂堆,排在前面的數量少,使用">";
priority_queue< pair< int,string >,vector< pair< int,string > >,greater< pair< int,string> > > queueK;
for (map<string,int>::iterator iter=wordcount.begin(); iter!=wordcount.end(); iter++)
{
queueK.push(make_pair(iter->second,iter->first));
if(queueK.size()>K)
queueK.pop();
}
pair<int,string>tmp;
priority_queue< pair< int,string >,vector< pair< int,string > >,less< pair< int,string> > > queueKless;
while (!queueK.empty())
{
tmp=queueK.top();
queueK.pop();
queueKless.push(tmp);
}
while(!queueKless.empty())
{
tmp=queueKless.top();
queueKless.pop();
cout<<tmp.second<<"\t"<<tmp.first<<endl;
}
cout<<"< Elapsed Time: "<<(clock()-t)/CLOCKS_PER_SEC<<" >"<<endl;
}
int main()
{
int k=0;
cout<<"http://blog.csdn.net/NUPTboyZHB\n";
while (true)
{
cout<<"PUT IN K: ";
cin>>k;
if(k<=0)break;
topK(k);
}
return 0;
}
[圖2]
2.統計英文單詞的出現頻率。這比統計漢字更加的容易,因為單詞和單詞之間是用空格分開的,所以,直接將單詞保存到string中即可。
[c++ code]
[cpp]
/*
*@author:鄭海波 http://blog.csdn.net/NUPTboyZHB
*參考:實驗室小熊
*注:有刪改
*/
#pragma warning(disable:4786)
#include <iostream>
#include <vector>
#include <fstream>
#include <string>
#include <map>
#include <queue>
#include <ctime>
using namespace std;
void topK(const int &K)
{
double t=clock();
ifstream infile;
infile.open("test.txt");
if (!infile)
cout<<"can not open file"<<endl;
string s;
map<string,int>wordcount;
while(true)
{
infile>>s;
if(infile.eof()) break;
wordcount[s]++;
}
cout<<"單詞種類:"<<wordcount.size()<<endl;
//優先隊列使用小頂堆,排在前面的數量少,使用">";
priority_queue< pair< int,string >,vector< pair< int,string > >,greater< pair< int,string> > > queueK;
for (map<string,int>::iterator iter=wordcount.begin(); iter!=wordcount.end(); iter++)
{
queueK.push(make_pair(iter->second,iter->first));
if(queueK.size()>K)
queueK.pop();
}
pair<int,string>tmp;
priority_queue< pair< int,string >,vector< pair< int,string > >,less< pair< int,string> > > queueKless;
while (!queueK.empty())
{
tmp=queueK.top();
queueK.pop();
queueKless.push(tmp);
}
while(!queueKless.empty())
{
tmp=queueKless.top();
queueKless.pop();
cout<<tmp.second<<"\t"<<tmp.first<<endl;
}
cout<<"< Elapsed Time: "<<(clock()-t)/CLOCKS_PER_SEC<<" >"<<endl;
}
int main()
{
int k=0;
cout<<"http://blog.csdn.net/NUPTboyZHB\n";
while (true)
{
cout<<"PUT IN K: ";
cin>>k;
if(k<=0)break;
topK(k);
}
return 0;
}
[圖2]