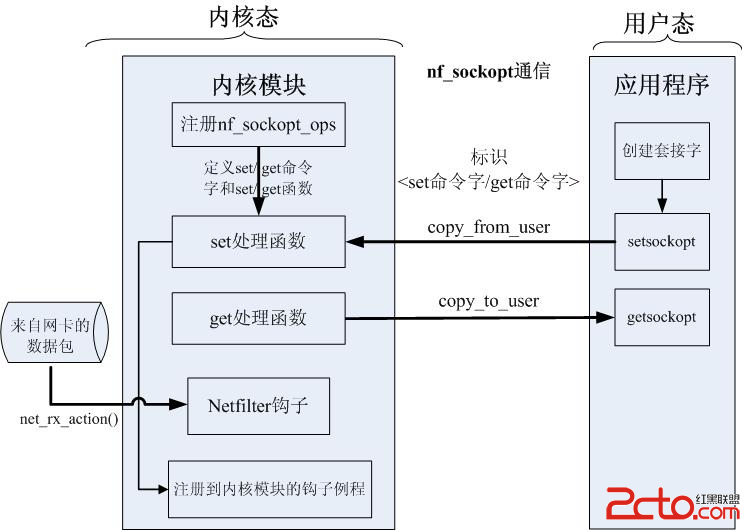
簡單易懂,上代碼: [cpp] #include <iostream> #include <cstring> #include <string> #include <cstdlib> #include <vector> using namespace std; class str{ char *c; typedef struct { int start; bool isChinese; } counter; int cLen; vector<counter> cs; void calculate(){ cLen = sizeof("你") - 1; int size = 0; for(int i = 0; i < getlen();){ counter ic; ic.start = i; //根據第一個字符是否為負數判斷是否為中文。。這個不知道是不是萬金油,但是大多數情況應該可以應付。 if(c[i] < 0){ ic.isChinese = true; i += cLen; }else{ ic.isChinese = false; i++; } cs.push_back(ic); } } public: str(const char *cc){ cout<<"構造"<<endl; c = new char[strlen(cc) + 1]; strcpy(c, cc); calculate(); } str(const str& s){//copy cout<<"copy"<<endl; c = new char[s.getlen() + 1]; strcpy(c, s.getstr()); calculate(); } const str& operator =(const str& s){ cout<<"= operator"<<endl; if(&s == this) return s; cs.clear(); delete []c; c = new char[s.getlen() +1]; strcpy(c, s.getstr()); calculate(); return *this; } //獲取源字符串 const char *getstr() const{return c;} //源字符串 字節數,不包括'\0' int getlen() const{ return strlen(c); } //真正字符個數,包括中英文。不包括'\0' int getsize() const{ return cs.size(); } //獲取第i個字符,可以為中文或英文。 const char* get(int i) const{ if(i > getsize()){ cout<<"error in get "<<endl; return NULL; } const counter &cc = cs[i]; char *r = NULL; int len = 0; if(cc.isChinese){ r = new char[cLen + 1]; len = cLen; }else{ r = new char[2]; len = 1; } memcpy(r, c + cc.start, len); r[len] = '\0'; string rs = r; delete[]r; return rs.c_str(); } void printBytes(const char *start, const char *end) const{//debug int i = 0; do{ cout<<(int)*(start+i)<<"\t"; }while(start+(++i) < end); cout<<endl; } //遍歷 void traversal() const {//debug for(int i = 0; i < getsize(); i++){ cout<<get(i)<<" "; //printBytes(get(i), get(i) + strlen(get(i))); } cout<<endl; } virtual ~str(){ delete []c; } }; int main(){ //construct str s("13,4?!你好。~!sda"); s.traversal(); str s1 = s;//copy cout<<s1.getlen()<<endl; s1.traversal(); s1 = s;//oeprator = cout<<s1.getlen()<<endl; s1.traversal(); return 0; }