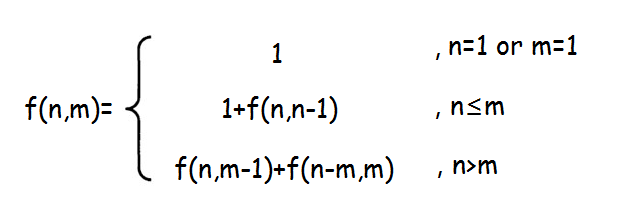字典樹的基本功能是用來查詢某個單詞(前綴)在所有單詞中出現次數的一種數據結構,它的插入和查詢復雜度都為O(len),Len為單詞(前綴)長度,但是它的空間復雜度卻非常高,如果字符集是26個字母,那每個節點的度就有26個,典型的以空間換時間結構。
 統計難題
Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131070/65535 K (Java/Others)
Total Submission(s): 11732 Accepted Submission(s): 4943
Problem Description
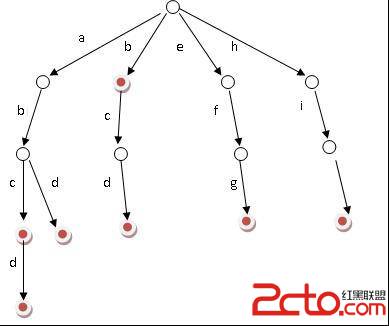
Ignatius最近遇到一個難題,老師交給他很多單詞(只有小寫字母組成,不會有重復的單詞出現),現在老師要他統計出以某個字符串為前綴的單詞數量(單詞本身也是自己的前綴).
Input
輸入數據的第一部分是一張單詞表,每行一個單詞,單詞的長度不超過10,它們代表的是老師交給Ignatius統計的單詞,一個空行代表單詞表的結束.第二部分是一連串的提問,每行一個提問,每個提問都是一個字符串.
注意:本題只有一組測試數據,處理到文件結束.
Output www.2cto.com
對於每個提問,給出以該字符串為前綴的單詞的數量.
Sample Input
banana
band
bee
absolute
acm
ba
b
band
abc
Sample Output
2
3
1
0
[cpp]
#include <stdio.h>
#define MAX_NODE 1000000
typedef struct NODE
{
int iCount;
struct NODE *pNext[26]; /* 26個孩子,26個字符 */
}NODE,*PNODE;
NODE node[MAX_NODE];
int ix_node = 0;
void Init(PNODE *pRoot);
PNODE CreateNode(); /* 創建新結點 */
void Insert(PNODE *pRoot,char *s); /* 插入 */
int Search(PNODE *pRoot,char *s); /* 查找 */
int main()
{
PNODE pRoot = NULL;
Init(&pRoot);
char list[20];
char input[20];
while(gets(list) && list[0])
Insert(&pRoot,list);
while(gets(input))
printf("%d\n",Search(&pRoot,input));
return 0;
}
int Search(PNODE *pRoot,char *s)
{
int i,k;
PNODE p = *pRoot;
if(!p)
return 0;
i = 0;
while(s[i])
{
k = s[i++] - 'a';
if(!p->pNext[k]) /* 沒有出現過 */
return 0;
p = p->pNext[k];
}
return p->iCount;
}
void Insert(PNODE *pRoot,char *s)
{
PNODE p = *pRoot;
int i,k;
if(!p)
p = *pRoot = CreateNode();
i = 0;
while(s[i])
{
/* 找到相應的分支 */
k = s[i++] - 'a';
if(p->pNext[k]) /* 如果此孩子非空 */
{
p->pNext[k]->iCount++;
}
else /* 如果此孩子為空,則創建 */
{
p->pNext[k] = CreateNode();
}
p = p->pNext[k];
}
}
PNODE CreateNode()
{
PNODE p;
int i;
/* 從數組中取出根結點 */
p = &node[ix_node++];
p->iCount = 1;
/* 孩子設為空 */
for(i = 0 ; i < 26 ; ++i)
p->pNext[i] = NULL;
return p;
}
void Init(PNODE *pRoot)
{
(*pRoot) = NULL;
}
統計難題
Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131070/65535 K (Java/Others)
Total Submission(s): 11732 Accepted Submission(s): 4943
Problem Description
Ignatius最近遇到一個難題,老師交給他很多單詞(只有小寫字母組成,不會有重復的單詞出現),現在老師要他統計出以某個字符串為前綴的單詞數量(單詞本身也是自己的前綴).
Input
輸入數據的第一部分是一張單詞表,每行一個單詞,單詞的長度不超過10,它們代表的是老師交給Ignatius統計的單詞,一個空行代表單詞表的結束.第二部分是一連串的提問,每行一個提問,每個提問都是一個字符串.
注意:本題只有一組測試數據,處理到文件結束.
Output www.2cto.com
對於每個提問,給出以該字符串為前綴的單詞的數量.
Sample Input
banana
band
bee
absolute
acm
ba
b
band
abc
Sample Output
2
3
1
0
[cpp]
#include <stdio.h>
#define MAX_NODE 1000000
typedef struct NODE
{
int iCount;
struct NODE *pNext[26]; /* 26個孩子,26個字符 */
}NODE,*PNODE;
NODE node[MAX_NODE];
int ix_node = 0;
void Init(PNODE *pRoot);
PNODE CreateNode(); /* 創建新結點 */
void Insert(PNODE *pRoot,char *s); /* 插入 */
int Search(PNODE *pRoot,char *s); /* 查找 */
int main()
{
PNODE pRoot = NULL;
Init(&pRoot);
char list[20];
char input[20];
while(gets(list) && list[0])
Insert(&pRoot,list);
while(gets(input))
printf("%d\n",Search(&pRoot,input));
return 0;
}
int Search(PNODE *pRoot,char *s)
{
int i,k;
PNODE p = *pRoot;
if(!p)
return 0;
i = 0;
while(s[i])
{
k = s[i++] - 'a';
if(!p->pNext[k]) /* 沒有出現過 */
return 0;
p = p->pNext[k];
}
return p->iCount;
}
void Insert(PNODE *pRoot,char *s)
{
PNODE p = *pRoot;
int i,k;
if(!p)
p = *pRoot = CreateNode();
i = 0;
while(s[i])
{
/* 找到相應的分支 */
k = s[i++] - 'a';
if(p->pNext[k]) /* 如果此孩子非空 */
{
p->pNext[k]->iCount++;
}
else /* 如果此孩子為空,則創建 */
{
p->pNext[k] = CreateNode();
}
p = p->pNext[k];
}
}
PNODE CreateNode()
{
PNODE p;
int i;
/* 從數組中取出根結點 */
p = &node[ix_node++];
p->iCount = 1;
/* 孩子設為空 */
for(i = 0 ; i < 26 ; ++i)
p->pNext[i] = NULL;
return p;
}
void Init(PNODE *pRoot)
{
(*pRoot) = NULL;
}