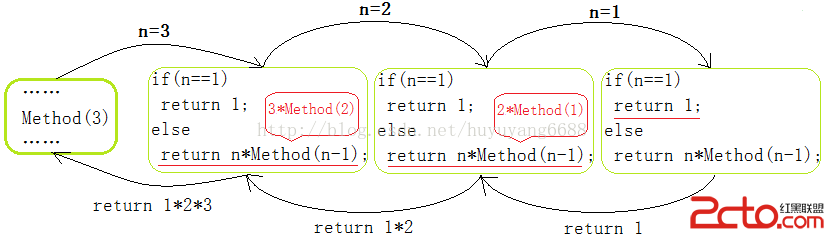
內部數據類型的處理如下: 全局變量和數組是在main函數執行前,分配在了數據段,程序結束後內存由系統收回; 局部靜態變量和數組是在程序第一次運行至此時分配在數據段,程序結束後內存由系統收回; 由malloc生成的數據分配在堆,如果需要釋放,必須手動調用free,沒有進行釋放的,程序結束後內存由系統收回; 對於內部數據類型,數組和普通變量沒有區別。 但是對於類對象,除了分配和釋放相應內存外,還需要調用構造函數和析構函數,那麼類對象就不能完全和內部數據類型處理一樣。 下面將對幾種情況進行分別說明,注意,這些lei都至少有構造函數或者析構函數或者兩者都有,否則,分配類對象和分配內部數據類型變量一樣。 局部對象 1. 局部對象像內部數據類型變量一樣,先在棧上分配內存; 2. 至少在使用該對象之前,調用對象的構造函數進行構造; 3. 在函數所有離開的地方(即return之前)調用對象的析構函數; 所以,如果在函數的開頭定義類對象的話,可能會有多個地方調用析構函數,這樣會增加代碼量。所以,和C程序一般將變量定義在開頭不同,建議C++程序將類對象定義在使用的附近,這樣可能會減少調用析構的次數。 全局對象 1. 全局對象的內存會在main之前分配到數據段; 2. 每個對象都對應一個_sti()函數,該函數調用構造函數,然後所有全局對象的_sti()函數都會在main函數最開始位置被執行一遍,這個叫做靜態初始化; 3. 相應的,每個_std()函數,該函數調用析構函數,所有的_std()函數會在main()最後的位置執行。 局部靜態對象 該對象最大的難度是只能被構造一次,即構造函數只能執行一次。我們很自然得想到可以為每個局部靜態對象設定一個全局的標示符,如果標示符符合什麼條件,表示沒有還沒有構造,如果標示符符合什麼條件,就表示已經構造了。該標識位可以是bool、也可以是指向靜態對象的指針(未構造時,指針為NULL,構造後,是地址)。 不過這樣的作法,玩意標示符被外界修改成了false或者NULL怎麼辦。 對象數組 需要對數組的每個元素都要執行一次構造,編譯器會生成一個vec_new函數或者它的變體對這些元素進行構造,函數可能如下: void* vec_new( void* array, size_t elem_size, int elem_count, void (*constructor)(void *), void (*destructor)(void *) )。 當然,當類無構造函數和析構函數時,vec_new不會被調用。 如果數組是全局的,那麼會在main函數最前面執行,如果local的,則會在分配內存時調用,如果local static,會在第一次調用時被調用。 但是,由於對象如果要聲明為數組,必須保證對象無constructor或者有default construtor或者有參數都是默認值的constructor,所以,假設constructor是帶有默認值參數的,那麼這些參數是如何在調用constructor進行賦值的呢?顯然vec_new無法做到。所以,根據這種情況,編譯器又生成了一個函數,叫做stub constructor,假定類名為class1結構如下: class1::class1(){ class1(默認參數列表); } 這和C++語法是相違背的,你可以試試寫一個無參數的構造函數和帶有參數都是默認參數的構造函數,是無法編譯通過的。我們要記住,這是一個特例。 new對象 new作為C++的運算符,在編譯的時候會被處理為類似以下邏輯的代碼,如: Class1* p = new Class1(); 被處理為: p = _new(sizeof(Class1)); if(p != NULL) p = Class1::Class1(p); 先通過_new在堆上分配內存,然後如果分配成功的話,再調用構造函數。 還記得,為什麼一個空類的大小也是1嗎?因為要保證兩個空類的對象地址不一樣,所以,當sizeof(Class1)為0時,_new函數會分配1字節的內存給p。 同理,delete p 會被處理為如下: if(p != NULL) _delete(p); _new和_delete是如何實現的呢? 雖然沒有硬性規定,但是一般情況下,總是以標准的malloc和free函數實現。 new數組對象 對於數組對象,最主要的難點在於delete數組時,是如何知道數組一共有多少對象。我們還是來看看new []都干了什麼。 new []首先會分配內存,然後和對象數組一樣調用vec_new函數為每個元素進行構造,不同的是,new []調用的vec_new函數第一個參數是0,告訴系統要在堆上進行分配。和對象數組其實就這個區別。難點就在於delete []和delete區別比較大。 如何讓在delete數組對象時,知道數組的維數呢?我目前知道兩種方式: 方式1. 增加一個word內存記錄,這個在effective C++上有說明,在數組最前面增加這個記錄; 方式2. 額外維護一個“聯合數組”用來保存進程中所有的數組的地址和數組的維數,有些編譯器可能還會增加其他信息,如destructor的地址。 如果為了節省內存,不維護destructor的地址,那麼在delete時就要明白destructor的地址。這個destructor地址是通過delete p的p對象的類型來確定的,但是有種情況就會出現錯誤 當base* p = new derived[10],時,delete [] p時,調用的destructor將是base的destructor,所以,為了能夠保證調用正確的derived 的 destructor,p指針指向的類型最好不要更改。 我的疑問 1. 知道元素的個數很難嗎 在c編程時,我們分配和釋放內存,是malloc和free,malloc會指定要分配的內存長度,但是free時,只要給定正確的內存起始地址就可以釋放掉正確長度的內存。這顯然利用了操作系統對內存的管理機制。 那麼,new []實際底層也是調用malloc進行分配,delete時調用free,應該很容易知道new []時分配的內存長度,長度除以一個對象的size,就可以得到對象的數目。 所以,這個問題還需要進一步的研究,肯定有些機制沒弄明白,元素個數不會這麼容易知道的。 placement new對象 在已有的一塊內存上重新分配一個對象。所以我們自然要求這塊內存能夠放得下這個對象。placement new共有兩個步驟 1. 改變內存的類型 Class1 * p = new(existting_mem) Class1; 2. 執行構造函數; 常見問題 1. 如果連續兩次執行 p = new(existting_mem) Class1,第二次執行時,應該執行一次class1的析構函數,對於這樣的問題,只能交由程序員自己避免這樣的問題,C++並沒有提供一個萬全之策; 2. Base b; new(&b)Derived; 假設Base和Derived類都聲明了virtual f(),那麼b.f()執行的是Base的還是Derived,很遺憾,編譯器一般都會去調用Base::f(); 對於placement new用法比較少,也比較簡單,所以使用的時候一定注意即可。 臨時性對象 如:www.2cto.com Class1 A, B; if(A+B){ //do something; } A+B就會產生一個臨時對象,if再判斷臨時對象。 至於這個臨時對象如何被釋放,C++標准並沒有給出明白的規定。 臨時對象,程序員一般看不到,它編譯器自動生成的,這可能會產生效率上的問題,至於如何避免效率上的問題,靠時間慢慢體會吧。