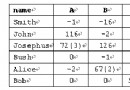
Binary search is simple in concept but quite error-prone in implementation. Better keep one for later use. My version may look like, [cpp] static int BinarySearch(TListRef list, int start, int count, const T &item, const IComparer<T> &comparer) { int low = start; int high = start + count; int mid; while (low < high) { mid = (low + high)/2; const T & v = list[mid]; int comp = comparer.Compare(item, v); if (comp < 0) { high = mid; } else if(comp > 0) { low = mid + 1; } else { return mid; // found, returning the position } } return -(low + 1); // not found, returning minus the position to insert minus one } Another two subroutines that can be useful and related to binary search are the two that find the boundaries of a chunk of items that are identical in the sorted list from the point that's returned by the binary search. The first one is the FindLeftMostMatch() which returns the index to the first item in the chunk which by definition should always exist. 'start' is the starting point of the subsequence in question from the list. If the whole list is to be processed, then it should be 0. Both it and the one after use a incremental step strategy which can be proven with time complexity O(log(n)) where n is the distance between the original position and the boundary. (The proof of which might need a bit of mathematics) [cpp] static int FindLeftmostMatch(TListRef list, int start, int index, const T &item, const IComparer<T> &comparer) { if (index == start) { return index; } int step = 1; int lastIndex = index; for (index -= step; index >= start; step += step, index -= step) { int comp = comparer.Compare(list[index], item); if (comp < 0) break; lastIndex = index; } if (index < start) { index = start; } // 'index' points to an item that's not identical to (actually less than) 'item' // 'lastIndex' points to an item that's within the chunk and thus identical to 'item' // it recursively calls itself to accomplish the task // it can be proven the time complexity is log(N) where N is the distance // between the initial point and the end of the chunk return FindLeftmostMatch(list, index, lastIndex, item, comparer); } The other one is named FindFirstSuccessor() which returns the index to the first item after the chunk; if the chunk sits at the end of the sequence, then it returns the length of the chunk. Likewise, if the whole list is considered, 'end' should be the length of the list. [cpp] static int FindFirstSuccessor(TListRef list, int end, int index, const T &item, const IComparer<T> &comparer) { if (index == end - 1) { return index; } int step = 1; int lastIndex = index; for (index += step; index < end; step += step, index += step) { int comp = comparer.Compare(item, list[index]); if (comp < 0) break; lastIndex = index; } if (index >= end) { index = end; } // 'index' points to an item that's not identical to (actually greater than) 'item' // 'lastIndex' points to an item that's within the chunk and thus identical to 'item' // it recursively calls itself to accomplish the task // it can be proven the time complexity is log(N) where N is the distance // between the initial point and the end of the chunk return FindRightmostMatch(list, lastIndex, index, item, comparer); } The binary search subroutine has been reasonably tested. The other two haven't undergone proper test thereby may subject to revision.