看此文,務必需要先了解本文討論的背景,不多說,給出鏈接:
探討C++ 變量生命周期、棧分配方式、類內存布局、Debug和Release程序的區別(一)
本文會以此問題作為討論的實例,來具體討論以下四個問題:
(1) C++變量生命周期
(2) C++變量在棧中分配方式
(3) C++類的內存布局
(4) Debug和Release程序的區別
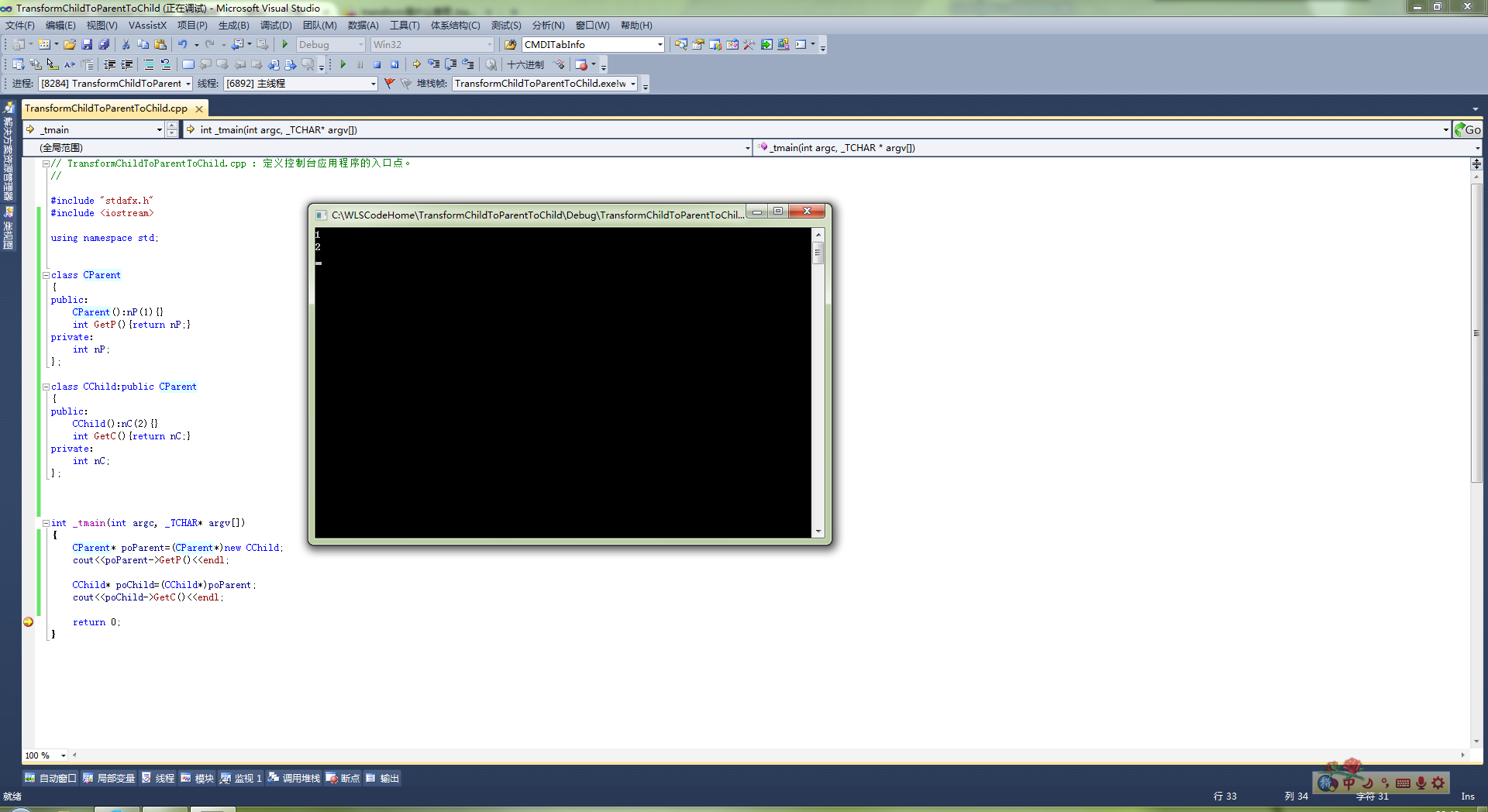
1、Debug版本輸出現象解析
先來說說Debug版本的輸出,前5次輸出,交替輸出,後5次輸出,交替輸出,但是,前5次和後5次的地址是不一樣的。
我們來看看反匯編:
T1 r(
01363A0F
01363A12
p[i]=&*],ecx
關鍵是看對象r的地址是如何分配的,但是,反匯編中似乎沒有明顯的信息,只有一句:lea ecx,[r],這條語句是什麼意思呢?將對象r的地址取到通用寄存器ecx中。
我們知道,程序在編譯鏈接的時候,變量相對於棧頂的位置就確定了,稱為相對地址確定。所以,此時程序在運行了,根據所在環境,變量的絕對地址也就確定了。
通過lea指令取得對象地址,調用對象的構造函數來進行構造,即語句call T1::T1 (1361172h). 構造完之後,對象所在地址的值才被正確填充。
好了,我們知道了這些局部變量相對於棧的相對地址,其實在編譯鏈接的時候就確定了,那麼,這個策略是什麼樣的呢?就是說,編譯器是如何來決定這些局部變量的地址的呢?
一般來說,對於不同的變量,編譯器都會分配不同的地址,一般是按照順序分配的。但是,對於那些局部變量,而且非常明顯的生命周期已經結束了,同一個地址,也會分配給不同的變量。
舉個例子,地址0X00001110,被編譯器用來存放變量A,同時也可能被編譯器用來存放變量B,如果A和B的大小相等,並且肯定不會同時存在。
編譯器在判斷一個地址是否能夠被多個變量同時使用的時候,這個判斷策略取決於編譯器本身,不同的編譯器判斷策略不同。
微軟的編譯器,就是根據代碼的自身邏輯來判斷的。當編譯器檢測到以下代碼的時候:
( i=;i<;i++(i%===&<<&r<<=&<<&r<<