_T("")是一個宏,他的作用是讓你的程序支持Unicode編碼
因為Windows使用兩種字符集ANSI和UNICODE,
前者就是通常使用的單字節方式,
但這種方式處理象中文這樣的雙字節字符不方便,
容易出現半個漢字的情況。
而後者是雙字節方式,方便處理雙字節字符。
Windows NT的所有與字符有關的函數都提供兩種方式的版本,而Windows 9x只支持ANSI方式。
如果你編譯一個程序為ANSI方式,
_T實際不起任何作用。
而如果編譯一個程序為UNICODE方式,則編譯器會把"Hello"字符串以UNICODE方式保存。_T和_L的區別在於,_L不管你是以什麼方式編譯,一律以UNICODE方式保存。
size_t,__T,_T,TEXT,_TEXT等一些特殊宏的理解
Unicode解決方案
對於wchar_t在WCHAR.h中是這樣定義的:
#define unsigned short wchar_t
那麼現在你該理解它了吧。
因此,wchar_t數據型態與無符號短整數型態相同,都是16位寬。
要定義包含一個寬字符的變量,可使用下面的語句:
wchar_t c = 'A' ;
變量c是一個雙字節值0x0041,是Unicode表示的字母A。(然而,因為Intel微處理器從最小的字節開始儲存多字節數值,該字節實際上是以0x41、0x00的順序保存在內存中。如果檢查Unicode文字的計算機儲存應注意這一點。)
您還可定義指向寬字符串的指針:
wchar_t * p = L"Hello!" ;
注意緊接在第一個引號前面的大寫字母L(代表「long」)。這將告訴編譯器該字符串按寬字符保存-即每個字符占用2個字節。通常,指針變量p要占用4個字節,而字符串變量需要14個字節-每個字符需要2個字節,末尾的0還需要2個字節。
同樣,您還可以用下面的語句定義寬字符數組:
static wchar_t a[] = L"Hello!" ;
該字符串也需要14個字節的儲存空間,sizeof (a) 將返回14。索引數組a可得到單獨的字符。a[1] 的值是寬字符「e」,或者0x0065。
雖然看上去更像一個印刷符號,但第一個引號前面的L非常重要,並且在兩個符號之間必須沒有空格。只有帶有L,編譯器才知道您需要將字符串存為每個字符2字節。稍後,當我們看到使用寬字符串而不是變量定義時,您還會遇到第一個引號前面的L。幸運的是,如果忘記了包含L,C編譯器通常會給提出警告或錯誤信息。
您還可在單個字符文字前面使用L前綴,來表示它們應解釋為寬字符。如下所示:
wchar_t c = L'A' ;
但通常這是不必要的,C編譯器會對該字符進行擴充,使它成為寬字符。
寬字符鏈接庫函數
我們都知道如何獲得字符串的長度。例如,如果我們已經像下面這樣定義了一個字符串指針:
char * pc = "Hello!" ;
我們可以呼叫
iLength = strlen (pc) ;
這時變量iLength將等於6,也就是字符串中的字符數。
太好了!現在讓我們試著定義一個指向寬字符的指針:
wchar_t * pw = L"Hello!" ;
再次呼叫strlen :
iLength = strlen (pw) ;
現在麻煩來了。首先,C編譯器會顯示一條警告消息,可能是這樣的內容:
'function' : incompatible types - from 'unsigned short *' to 'const char *'
這條消息的意思是:聲明strlen函數時,該函數應接收char類型的指標,但它現在卻接收了一個unsigned short類型的指標。您仍然可編譯並執行該程序,但您會發現iLength等於1。為什麼?
字符串「Hello!」中的6個字符占用16位:
0x0048 0x0065 0x006C 0x006C 0x006F 0x0021
Intel處理器在內存中將其存為:
48 00 65 00 6C 00 6C 00 6F 00 21 00
假定strlen函數正試圖得到一個字符串的長度,並把第1個字節作為字符開始計數,但接著假定如果下一個字節是0,則表示字符串結束。
這個小練習清楚地說明了C語言本身和執行時期鏈接庫函數之間的區別。編譯器將字符串L"Hello!" 解釋為一組16位短整數型態數據,並將其保存在wchar_t數組中。編譯器還處理數組索引和sizeof操作符,因此這些都能正常工作,但在連結時才添加執行時期鏈接庫函數,例如strlen。這些函數認為字符串由單字節字符組成。遇到寬字符串時,函數就不像我們所希望那樣執行了。
您可能要說:「噢,太麻煩了!」現在每個C語言鏈接庫函數都必須重寫以接受寬字符。但事實上並不是每個C語言鏈接庫函數都需要重寫,只是那些有字符串參數的函數才需要重寫,而且也不用由您來完成。它們已經重寫完了。
strlen函數的寬字符版是wcslen(wide-character string length:寬字符串長度),並且在STRING.H(其中也說明了strlen)和WCHAR.H中均有說明。strlen函數說明如下:
size_t __cdecl strlen (const char *) ;
而wcslen函數則說明如下:
size_t __cdecl wcslen (const wchar_t *) ;
這時我們知道,要得到寬字符串的長度可以呼叫
iLength = wcslen (pw) ;
函數將返回字符串中的字符數6。請記住,改成寬字節後,字符串的字符長度不改變,只是位組長度改變了。
您熟悉的所有帶有字符串參數的C執行時期鏈接庫函數都有寬字符版。例如,wprintf是printf的寬字符版。這些函數在WCHAR.H和含有標准函數說明的表頭文件中說明。
維護單一原始碼
當然,使用Unicode也有缺點。第一點也是最主要的一點是,程序中的每個字符串都將占用兩倍的儲存空間。此外,您將發現寬字符執行時期鏈接庫中的函數比常規的函數大。出於這個原因,您也許想建立兩個版本的程序-一個處理ASCII字符串,另一個處理Unicode字符串。最好的解決辦法是維護既能按ASCII編譯又能按Unicode編譯的單一原始碼文件。
雖然只是一小段程序,但由於執行時期鏈接庫函數有不同的名稱,您也要定義不同的字符,這將在處理前面有L的字符串文字時遇到麻煩。
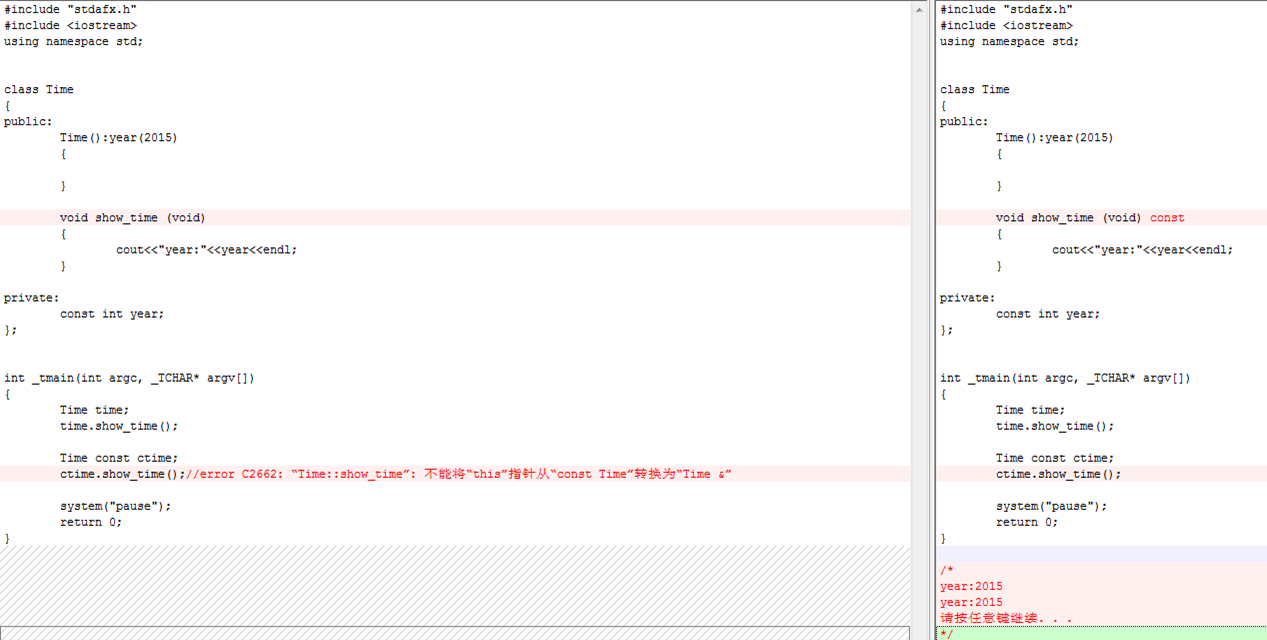
一個辦法是使用Microsoft Visual C++包含的TCHAR.H表頭文件。該表頭文件不是ANSI C標准的一部分,因此那裡定義的每個函數和宏定義的前面都有一條底線。TCHAR.H為需要字符串參數的標准執行時期鏈接庫函數提供了一系列的替代名稱(例如,_tprintf和_tcslen)。有時這些名稱也稱為「通用」函數名稱,因為它們既可以指向函數的Unicode版也可以指向非Unicode版。
如果定義了名為_UNICODE的標識符,並且程序中包含了TCHAR.H表頭文件,那麼_tcslen就定義為wcslen:
#define _tcslen wcslen
如果沒有定義UNICODE,則_tcslen定義為strlen:
#define _tcslen strlen
等等。TCHAR.H還用一個新的數據型態TCHAR來解決兩種字符數據型態的問題。如果定義了_UNICODE標識符,那麼TCHAR就是wchar_t:
typedef wchar_t TCHAR ;
否則,TCHAR就是Char:
typedef char TCHAR ;
現在開始討論字符串文字中的L問題。如果定義了_UNICODE標識符,那麼一個稱作__T的宏就定義如下:
#define __T(x) L##x
這是相當晦澀的語法,但合乎ANSI C標准的前置處理器規范。那一對井字號稱為「粘貼符號(token paste)」,它將字母L添加到宏參數上。因此,如果宏參數是"Hello!",則L##x就是L"Hello!"。
如果沒有定義_UNICODE標識符,則__T宏只簡單地定義如下:
#define __T(x) x
此外,還有兩個宏與__T定義相同:
#define _T(x)__T(x)
#define _TEXT(x)__T(x)
在Win32 console程序中使用哪個宏,取決於您喜歡簡潔還是詳細。基本地,必須按下述方法在_T或_TEXT宏內定義字符串文字:
_TEXT ("Hello!")
這樣做的話,如果定義了_UNICODE,那麼該串將解釋為寬字符的組合,否則解釋為8位的字符字符串。
寬字符和 Windows
Windows NT從底層支援Unicode。這意味著Windows NT內部使用由16位字符組成的字符串。因為世界上其它許多地方還不使用16位字符串,所以Windows NT必須經常將字符串在操作系統內轉換。Windows NT可執行為ASCII、Unicode或者ASCII和Unicode混合編寫的程序。即,Windows NT支持不同的API函數呼叫,這些函數接受8位或16位的字符串(我們將馬上看到這是如何動作的。)
相對於Windows NT,Windows 98對Unicode的支持要少得多。只有很少的Windows 98函數呼叫支持寬字符串(這些函數列在《Microsoft Knowledge Base article Q125671》中;它們包括MessageBox)。如果要發行的程序中只有一個.EXE文件要求在Windows NT和Windows 98下都能執行,那麼就不應該使用Unicode,否則就不能在Windows 98下執行;尤其程序不能呼叫Unicode版的Windows函數。這樣,將來發行Unicode版的程序時會處於更有利的位置,您應試著編寫既為ASCII又為Unicode編譯的原始碼。這就是本書中所有程序的編寫方式。
Windows表頭文件類型
正如您在第一章所看到的那樣,一個Windows程序包括表頭文件WINDOWS.H。該文件包括許多其它表頭文件,包括WINDEF.H,該文件中有許多在Windows中使用的基本型態定義,而且它本身也包括WINNT.H。WINNT.H處理基本的Unicode支持。
WINNT.H的前面包含C的表頭文件CTYPE.H,這是C的眾多表頭文件之一,包括wchar_t的定義。WINNT.H定義了新的數據型態,稱作CHAR和WCHAR:
typedef char CHAR ;
typedef wchar_t WCHAR ; // wc
當您需要定義8位字符或者16位字符時,推薦您在Windows程序中使用的數據型態是CHAR和WCHAR。WCHAR定義後面的注釋是匈牙利標記法的建議:一個基於WCHAR數據型態的變量可在前面附加上字母wc以說明一個寬字符。
WINNT.H表頭文件進而定義了可用做8位字符串指針的六種數據型態和四個可用做const 8位字符串指針的數據型態。這裡精選了表頭文件中一些實用的說明數據型態語句:
typedef CHAR * PCHAR, * LPCH, * PCH, * NPSTR, * LPSTR, * PSTR ;
typedef CONST CHAR * LPCCH, * PCCH, * LPCSTR, * PCSTR ;
前綴N和L表示「near」和「long」,指的是16位Windows中兩種大小不同的指標。在Win32中near和long指標沒有區別。
類似地,WINNT.H定義了六種可作為16位字符串指針的數據型態和四種可作為const 16位字符串指針的數據型態:
typedef WCHAR * PWCHAR, * LPWCH, * PWCH, * NWPSTR, * LPWSTR, * PWSTR ;
typedef CONST WCHAR * LPCWCH, * PCWCH, * LPCWSTR, * PCWSTR ;
至此,我們有了數據型態CHAR(一個8位的char)和WCHAR(一個16位的wchar_t),以及指向CHAR和WCHAR的指標。與TCHAR.H一樣,WINNT.H將TCHAR定義為一般的字符類型。如果定義了標識符UNICODE(沒有底線),則TCHAR和指向TCHAR的指標就分別定義為WCHAR和指向WCHAR的指標;如果沒有定義標識符UNICODE,則TCHAR和指向TCHAR的指標就分別定義為char和指向char的指標:
#ifdef UNICODE
typedef WCHAR TCHAR, * PTCHAR ;
typedef LPWSTR LPTCH, PTCH, PTSTR, LPTSTR ;
typedef LPCWSTR LPCTSTR ;
#else
typedef char TCHAR, * PTCHAR ;
typedef LPSTR LPTCH, PTCH, PTSTR, LPTSTR ;
typedef LPCSTR LPCTSTR ;
#endif
如果已經在某個表頭文件或者其它表頭文件中定義了TCHAR數據型態,那麼WINNT.H和WCHAR.H表頭文件都能防止其重復定義。不過,無論何時在程序中使用其它表頭文件時,都應在所有其它表頭文件之前包含WINDOWS.H。
WINNT.H表頭文件還定義了一個宏,該宏將L添加到字符串的第一個引號前。如果定義了UNICODE標識符,則一個稱作 __TEXT的宏定義如下:
#define __TEXT(quote) L##quote
如果沒有定義標識符UNICODE,則像這樣定義__TEXT宏:
#define __TEXT(quote) quote
此外, TEXT宏可這樣定義:
#define TEXT(quote) __TEXT(quote)
這與TCHAR.H中定義_TEXT宏的方法一樣,只是不必操心底線。我將在本書中使用這個宏的TEXT版本。
這些定義可使您在同一程序中混合使用ASCII和Unicode字符串,或者編寫一個可被ASCII或Unicode編譯的程序。如果您希望明確定義8位字符變量和字符串,請使用CHAR、PCHAR(或者其它),以及帶引號的字符串。為明確地使用16位字符變量和字符串,請使用WCHAR、PWCHAR,並將L添加到引號前面。對於是8位還是16位取決於UNICODE標識符的定義的變量或字符串,要使用TCHAR、PTCHAR和TEXT宏。
-----------------------維護單一原始碼
使用Unicode最主要缺點是,程序中的每個字串都將占用兩倍的儲存空間。此外,寬字符執行時期程序庫中的函數比常規的函數大。 因此,就有必要建立兩個版本的程序——一個處理ASCII字串,另一個處理Unicode字串。最好的解決辦法是維護既能按ASCII編譯又能按Unicode編譯的單一原始碼檔案。 一個辦法是使用Microsoft Visual C++包含的TCHAR.H頭文件。(該頭文件不是ANSI C標准的一部分,因此其中定義的每個函數和巨集定義的前面都有一條下橫線。) TCHAR.H為需要字串參數的標准執行時期程序庫函數提供了一系列的替代名稱(例如,_tprintf和_tcslen)。有時這些名稱也稱為「通用」函數名稱,因為它們既可以指向函數的Unicode版也可以指向非Unicode版。 如果定義了名為_UNICODE的識別字,並且程序中包含了TCHAR.H頭文件,那麼_tcslen就定義為wcslen: #define _tcslen wcslen 如果沒有定義UNICODE,則_tcslen定義為strlen: #define _tcslen strlen 等等。 TCHAR.H還用一個新的數據類型TCHAR來解決兩種字符數據類型的問題。如果定義了 _UNICODE識別字,那麼TCHAR就是wchar_t: typedef wchar_t TCHAR ; 否則,TCHAR就是char: typedef char TCHAR ; 現在開始討論字串文字中的L問題。如果定義了_UNICODE識別字,那麼一個稱作__T的巨集就定義如下: #define __T(x) L##x 這是相當晦澀的語法,但合乎ANSI C標准的前置處理器規范。那一對井字號稱為「粘貼符號(token paste)」,它將字母L添加到巨集引數上。因此,如果巨集引數是"Hello!",則L##x就是L"Hello!"。 如果沒有定義_UNICODE識別字,則__T巨集只簡單地定義如下: #define __T(x) x 此外,還有兩個巨集與__T定義相同: #define _T(x) __T(x) #define _TEXT(x) __T(x) 在Win32 console程序中使用哪個巨集,取決於您喜歡簡潔還是詳細。基本地,必須按下述方法在_T或_TEXT巨集內定義字串文字: _TEXT ("Hello!") 這樣做的話,如果定義了_UNICODE,那麼該串將解釋為寬字符的組合,否則解釋為8位元的字符字串。 (轉自:http://wwboss.blog.sohu.com/14019890.html)