上篇講述了內存中的封裝模型,下篇我們講述一下繼承和多態。
二、繼承與多態情況下的內存布局
由於繼承下的內存布局以及構造過程很多書籍都講得比較詳細,所以這裡不細講。重點講多態。
繼承有以下這幾種情況:
1.單一繼承
2.多重繼承
3.重復繼承
4.虛擬繼承
1.單一繼承的場合
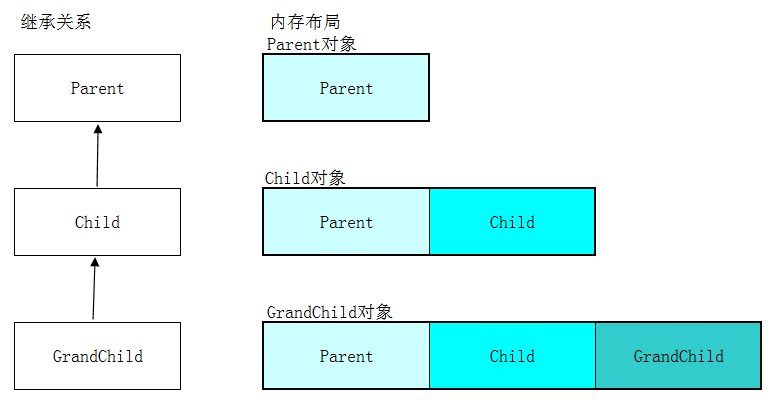
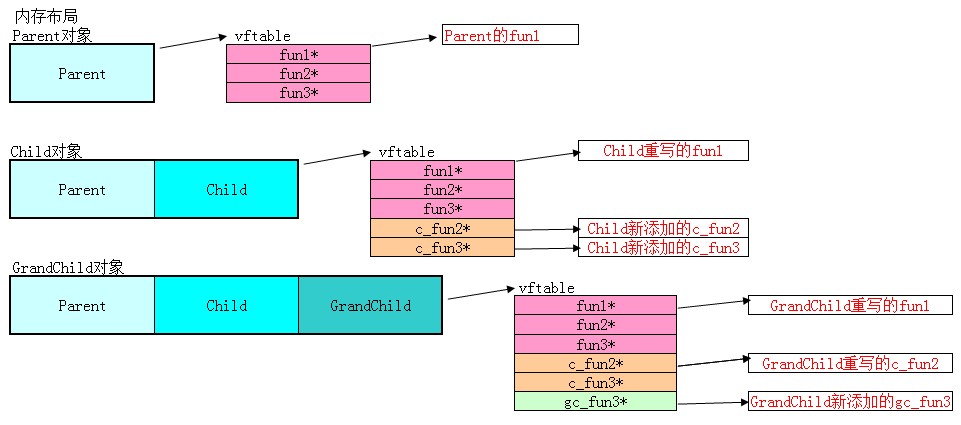
假設有以下繼承關系,那麼大致的內存布局如下
代碼
Child: GrandChild:
對象布局:

成員變量的布局很好理解,那麼在有虛函數的場合,虛函數表到底又是怎麼樣的呢?
為了解決這個問題我完善上面的代碼。
fun1(){ cout<<<< fun2(){ cout<<<< fun3(){ cout<<<< Child: fun1() { cout<<<< c_fun2(){ cout<<<< c_fun3(){ cout<<<< GrandChild: fun1() { cout<<<< c_fun2(){ cout<<<< gc_fun3(){ cout<<<<
我們先使用調試窗口查看一下虛函數表
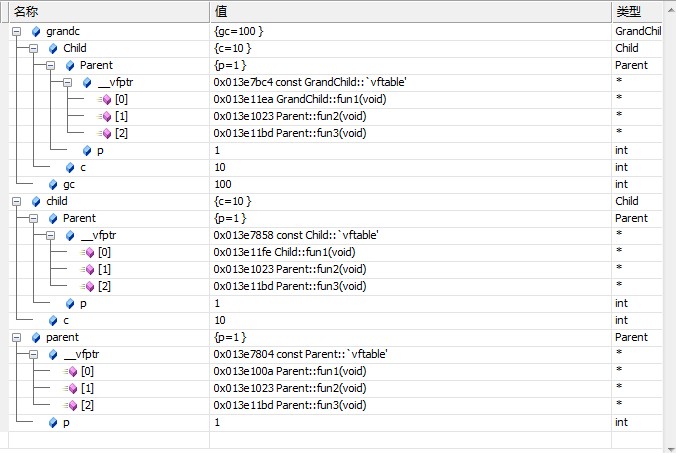
可以看到三張表是不同的,可以看到fun1函數被改寫了兩次。
比較蛋疼的是grandc只能看到三個函數,君不見c_fun2和gc_fun3,還得自己動手來。
繼上篇的內容,我們使用pf這個函數指針:
(*PF)();
PF pf = NULL;
在主函數裡我們寫下代碼:
* vtab = (*)*(*)& (; *vtab != NULL; vtab++= (PF)** member = (*)&<<*++member<<<<*++member<<<<*++member<<endl;
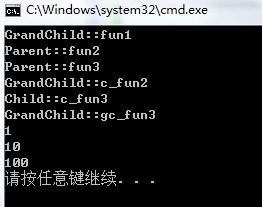
成員變量輸出結果與我們上篇的結論一致,咱們主要來看一下虛函數部分。
並且前三個函數同調試窗口的顯示結果。
我們依據以上結果可以得到這麼幾個結論:
1.單一繼承時,不同的類維護不同的虛函數表(only one),並且虛函數表初始情況是父類的樣子。
2.當發生overwrite時,例如fun1和c_fun2都會沖刷掉父類的虛函數,代替之。
3.沒有發生overwrite時,直接添加到虛函數表中。
圖示:
截止到這裡,結合上篇的內容,就能很容易理解為什麼使用父類指針能產生多態的效果了。
2.多重繼承的場合
假設有以下繼承關系,那麼大致的內存布局如下
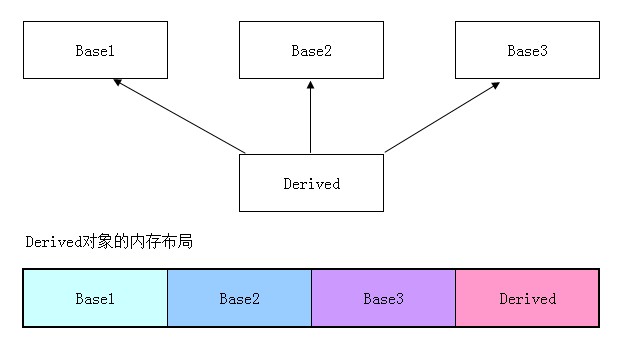
由於是多繼承,根據1的觀點,單一繼承時一個類維護一個虛函數表。多繼承時怎麼辦呢?
那只能是繼承幾個類,就有幾張虛函數表了。
實例代碼如下:
fun1(){ cout<<<< fun2(){ cout<<<< fun3(){ cout<<<< fun1(){ cout<<<< fun2(){ cout<<<< fun3(){ cout<<<< fun1(){ cout<<<< fun2(){ cout<<<< fun3(){ cout<<<< Derived: Base1, Base2, fun1(){ cout<<<< d_fun(){ cout<<<<
通過調試窗口查看一下虛函數表:
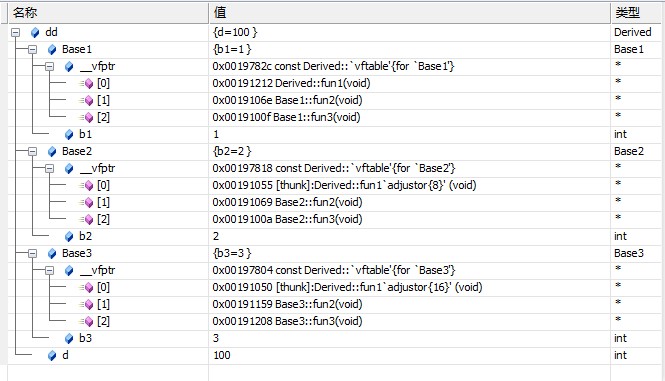
可以明確的看到標注了for base,源自哪個基類的虛函數表。
並且可以看到fun1在三個表中全部被重寫了,那麼我們關心的d_fun到底會放在哪個表呢?
我們使用相同的辦法:
(*PF)();
PF pf = NULL;
* vtab1 = (*)*(*)& (; *vtab1 != NULL; vtab1++= (PF)** member1 = (*)&<<*++member1<<
* vtab2 = (*)*((*)&dd + (Base1)/ (; *vtab2 != NULL; vtab2++= (PF)** member2 = (*)((*)&dd + (Base1)/<<*++member2<<
* vtab3 = (*)*((*)&dd + ((Base1)+(Base2))/ (; *vtab3 != NULL; vtab3++= (PF)** member3 = (*)((*)&dd + ((Base1)+(Base2))/<<*++member3<<endl;
偷了點懶,因為使用的是int型,所以沒有存在字節對齊的情況,直接使用的sizeof/4,使用這種偏移量來訪問不同的base區域。
以下是輸出結果:
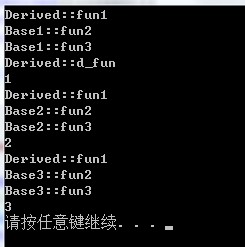
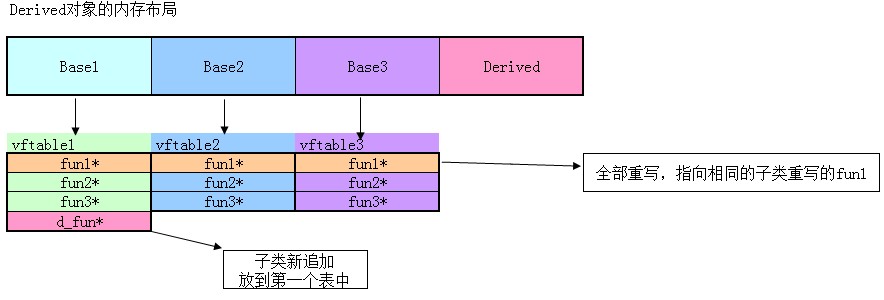
我們可以看到d_fun被放到了第一個函數表中去了(聲明的次序的第一個,實例代碼是base1的部分)。
結論:
1.多重繼承的場合,overwirte時,父類的函數在三個表中會全部被重寫。
2.子類新添加的虛函數被放到第一個虛函數表中。
圖示:
3.重復繼承的場合
其實重復繼承只是多重繼承的特例,一切的規則依然按照多重繼承的規則實行。只是特殊在祖父類生成了兩個拷貝鏡像,形成數據重復,並且造成二義性。
無論從設計的的角度還是維護的角度,這都是一個失敗的選擇。
所以我們不重點討論,直接跳到虛擬繼承。
4.虛擬繼承的場合
關於虛擬繼承的對象模型,其實有多種方法,本文使用的的環境是vs2008,屬於微軟想的招兒。《深入C++對象模型》一書中明確指出了
虛擬繼承的場合,對象模型的構建方式沒有固定的標准,主要的思路是拆分成不變局部和共享局部。當然只有更好的方法,也都是為了達到更高的存取效率。
所以本文描述的內存布局或許只在微軟編譯器的場合成立,正因為如此,我們把重點放在虛擬繼承的要達到的效果上。
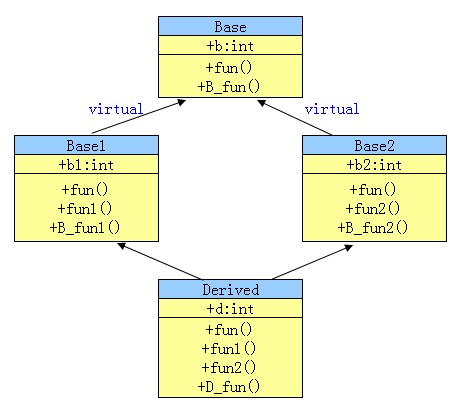
假設有以下繼承關系:
實例代碼:
fun(){ cout<<<< B_fun(){ cout<<<< Base1: fun(){ cout<<<< fun1(){ cout<<<< B_fun1(){ cout<<<< Base2: fun(){ cout<<<< fun2(){ cout<<<< B_fun2(){ cout<<<< Derived: Base1, fun(){ cout<<<< fun1(){ cout<<<< fun2(){ cout<<<< D_fun(){ cout<<<<
先來討論單一虛擬繼承的情況,看一下Base1的布局:
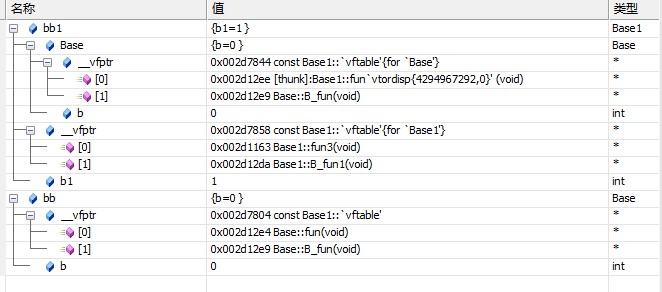
bb是Base的對象,bb1是Base1的對象。
明顯可以看到與普通單一繼承不同,使用了兩個虛函數指針,一個指向了虛基類Base的表,以及自己再生成一個表。
而指向虛基類Base的表的虛函數fun明顯被重寫了。
使用代碼讀取:
* vtab = (*)*(*)& (; *vtab != NULL; vtab++= (PF)*
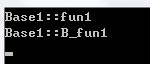
這個循環運行會中斷,原因是vtab訪問了一個神奇的數字-4,這個是用來隔開的,不小心訪問了。(陳皓老師的一篇博文《C++對象的內存布局》也遇到了相同的問題,而GCC卻沒有)
足以證明,這裡的不變局部是Derived自己後來添加的函數。而共享局部fun跑到虛基類包含的虛函數表上去了。
我們使用二級指針來解決中斷的問題。
** pVtab = (**)&
pf = (PF)pVtab[][
= (PF)pVtab[][
cout << pVtab[][] << endl;
<< ()*((*)(&bb1)+) <<endl;
<<<<(*)*((*)(&bb1)+) <<endl;
pf = (PF)pVtab[][= (PF)pVtab[][<< pVtab[][] << endl;
<< ()*((*)(&bb1)+) <<endl;
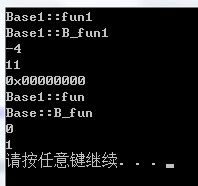
可以看出內存布局:
1.不變布局(子類)放在對象模型的前端,共享布局(虛基類)放在尾端。
2.其中子類部分,虛函數表使用了-4作為分隔結尾。接下來是子類成員變量值
3.虛基類屬於共享局部,是一個正常的虛函數表布局,並且重寫了fun函數。
圖示:
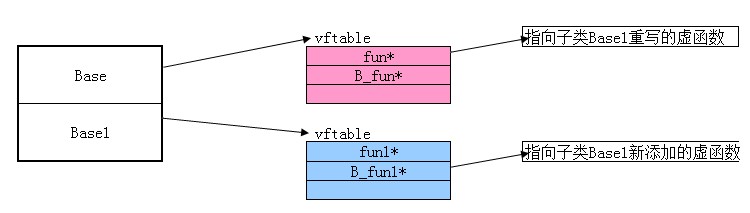
這樣是能夠保證共享部分處於虛基類中(包括虛函數表),不變部分處於子類中。
接下來看完整的繼承結構,解析Derived的布局。
使用代碼:
** pVtab = (**)&
pf = (PF)pVtab[][= (PF)pVtab[][<< pVtab[][] << endl;
<< ()*((*)(&dd)+) <<endl;
pf = (PF)pVtab[][= (PF)pVtab[][<< pVtab[][] << endl;
cout << ()*((*)(&dd)+) <<endl;
cout << ()*((*)(&dd)+) <<endl;
cout << <<(*)*((*)(&dd)+) <<= (PF)pVtab[][= (PF)pVtab[][<< ()*((*)(&dd)+) <<endl;
運行結果:
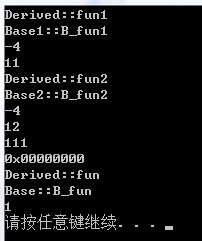
與單一虛擬繼承類似:
1.按照聲明的次序,不變布局(父類)依次放在對象模型的前端,共享布局(虛基類)放在最尾端。
2.其中不變布局部分,虛函數表使用了-4作為分隔結尾。接下來是子類成員變量值
3.虛基類屬於共享局部,是一個正常的虛函數表布局,並且重寫了fun函數。
圖就不畫了,與單一虛擬繼承的情況類似。
引用《深入C++對象模型》一書的描述:
要在編譯器中支持虛擬繼承,困難度頗高。
難度在於,要找到一個足夠有效的辦法,將Base1和Base2各自維護的Base部分,折疊成為一個由Derived單一維護的Base部分,並且還可以保持base class和Derived class的指針之間的多態操作。
這也整是虛擬繼承要達到的效果。
至此,全篇差不多講完了。
主要參考書籍《深入C++對象模型》以及上文提到的陳皓老師的博文,內容稍長,難免有纰漏,望大家指正。