今天在網上看到了一篇寫得非常好的文章,是有關c++類繼承內存布局的。看了之後獲益良多,現在轉在我自己的博客裡面,作為以後復習之用。
——談VC++對象模型
(美)簡.格雷
程化 譯
譯者前言
一個C++程序員,想要進一步提升技術水平的話,應該多了解一些語言的語意細節。對於使用VC++的程序員來說,還應該了解一些VC++對於C++的诠釋。 Inside the C++ Object Model雖然是一本好書,然而,書的篇幅多一些,又和具體的VC++關系小一些。因此,從篇幅和內容來看,譯者認為本文是深入理解C++對象模型比較好的一個出發點。
這篇文章以前看到時就覺得很好,舊文重讀,感覺理解得更多一些了,於是產生了翻譯出來,與大家共享的想法。雖然文章不長,但時間有限,又若干次在翻譯時打盹睡著,拖拖拉拉用了小一個月。
一方面因本人水平所限,另一方面因翻譯時經常打盹,錯誤之處恐怕不少,歡迎大家批評指正。
本文原文出處為MSDN。如果你安裝了MSDN,可以搜索到C++ Under the Hood。否則也可在網站上找到http://msdn.microsoft.com/archive/default.asp?url=/archive/en-us/dnarvc/html/jangrayhood.asp。
1 前言
了解你所使用的編程語言究竟是如何實現的,對於C++程序員可能特別有意義。首先,它可以去除我們對於所使用語言的神秘感,使我們不至於對於編譯器干的活感到完全不可思議;尤其重要的是,它使我們在Debug和使用語言高級特性的時候,有更多的把握。當需要提高代碼效率的時候,這些知識也能夠很好地幫助我們。
本文著重回答這樣一些問題:
1* 類如何布局?
2* 成員變量如何訪問?
3* 成員函數如何訪問?
4* 所謂的“調整塊”(adjuster thunk)是怎麼回事?
5* 使用如下機制時,開銷如何:
* 單繼承、多重繼承、虛繼承
* 虛函數調用
* 強制轉換到基類,或者強制轉換到虛基類
* 異常處理
首先,我們順次考察C兼容的結構(struct)的布局,單繼承,多重繼承,以及虛繼承;
接著,我們講成員變量和成員函數的訪問,當然,這裡面包含虛函數的情況;
再接下來,我們考察構造函數,析構函數,以及特殊的賦值操作符成員函數是如何工作的,數組是如何動態構造和銷毀的;
最後,簡單地介紹對異常處理的支持。
對每個語言特性,我們將簡要介紹該特性背後的動機,該特性自身的語意(當然,本文決不是“C++入門”,大家對此要有充分認識),以及該特性在微軟的 VC++中是如何實現的。這裡要注意區分抽象的C++語言語意與其特定實現。微軟之外的其他C++廠商可能提供一個完全不同的實現,我們偶爾也會將 VC++的實現與其他實現進行比較。
2 類布局
本節討論不同的繼承方式造成的不同內存布局。
2.1 C結構(struct)
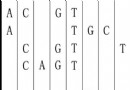
由於C++基於C,所以C++也“基本上”兼容C。特別地,C++規范在“結構”上使用了和C相同的,簡單的內存布局原則:成員變量按其被聲明的順序排列,按具體實現所規定的對齊原則在內存地址上對齊。所有的C/C++廠商都保證他們的C/C++編譯器對於有效的C結構采用完全相同的布局。這裡,A是一個簡單的C結構,其成員布局和對齊方式都一目了然

[cpp] view plaincopy
譯者注:從上圖可見,A在內存中占有8個字節,按照聲明成員的順序,前4個字節包含一個字符(實際占用1個字節,3個字節空著,補對齊),後4個字節包含一個整數。A的指針就指向字符開始字節處。
2.2 有C++特征的C結構
當然了,C++不是復雜的C,C++本質上是面向對象的語言:包含 繼承、封裝,以及多態 。原始的C結構經過改造,成了面向對象世界的基石——類。除了成員變量外,C++類還可以封裝成員函數和其他東西。然而,有趣的是,除非 為了實現虛函數和虛繼承引入的隱藏成員變量外,C++類實例的大小完全取決於一個類及其基類的成員變量!成員函數基本上不影響類實例的大小。
這裡提供的B是一個C結構,然而,該結構有一些C++特征:控制成員可見性的“public/protected/private”關鍵字、成員函數、靜態成員,以及嵌套的類型聲明。雖然看著琳琅滿目,實際上,只有成員變量才占用類實例的空間。要注意的是,C++標准委員會不限制由“public/protected/private”關鍵字分開的各段在實現時的先後順序,因此,不同的編譯器實現的內存布局可能並不相同。( 在VC++中,成員變量總是按照聲明時的順序排列)。
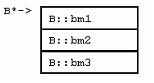
譯者注:B中,為何static int bsm不占用內存空間?因為它是靜態成員,該數據存放在程序的數據段中,不在類實例中。
2.3 單繼承
C++ 提供繼承的目的是在不同的類型之間提取共性。比如,科學家對物種進行分類,從而有種、屬、綱等說法。有了這種層次結構,我們才可能將某些具備特定性質的東西歸入到最合適的分類層次上,如“懷孩子的是哺乳動物”。由於這些屬性可以被子類繼承,所以,我們只要知道“鯨魚、人”是哺乳動物,就可以方便地指出“鯨魚、人都可以懷孩子”。那些特例,如鴨嘴獸(生蛋的哺乳動物),則要求我們對缺省的屬性或行為進行覆蓋。
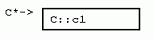
C++中的繼承語法很簡單,在子類後加上“:base”就可以了。下面的D繼承自基類C。
[cpp] view plaincopy
既然派生類要保留基類的所有屬性和行為,自然地,每個派生類的實例都包含了一份完整的基類實例數據。在D中,並不是說基類C的數據一定要放在D的數據之前,只不過這樣放的話,能夠保證D中的C對象地址,恰好是D對象地址的第一個字節。這種安排之下,有了派生類D的指針,要獲得基類C的指針,就不必要計算偏移量 了。幾乎所有知名的C++廠商都采用這種內存安排(基類成員在前)。在單繼承類層次下,每一個新的派生類都簡單地把自己的成員變量添加到基類的成員變量之後 。看看上圖,C對象指針和D對象指針指向同一地址。
2.4 多重繼承
大多數情況下,其實單繼承就足夠了。但是,C++為了我們的方便,還提供了多重繼承。
比如,我們有一個組織模型,其中有經理類(分任務),工人類(干活)。那麼,對於一線經理類,即既要從上級經理那裡領取任務干活,又要向下級工人分任務的角色來說,如何在類層次中表達呢?單繼承在此就有點力不勝任。我們可以安排經理類先繼承工人類,一線經理類再繼承經理類,但這種層次結構錯誤地讓經理類繼承了工人類的屬性和行為。反之亦然。當然,一線經理類也可以僅僅從一個類(經理類或工人類)繼承,或者一個都不繼承,重新聲明一個或兩個接口,但這樣的實現弊處太多:多態不可能了;未能重用現有的接口;最嚴重的是,當接口變化時,必須多處維護。最合理的情況似乎是一線經理從兩個地方繼承屬性和行為——經理類、工人類。
C++就允許用多重繼承來解決這樣的問題:
struct Manager ... { ... };[cpp] view plaincopy
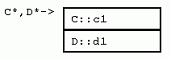
這樣的繼承將造成怎樣的類布局呢?下面我們還是用“字母類”來舉例:

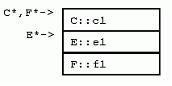
[cpp] view plaincopy
結構F從C和E多重繼承得來。與單繼承相同的是,F實例拷貝了每個基類的所有數據。與單繼承不同的是,在多重繼承下,內嵌的兩個基類的對象指針不可能全都與派生類對象指針相同:
[cpp] view plaincopy
譯者注:上面那行說明C對象指針與F對象指針相同,下面那行說明E對象指針與F對象指針不同。
觀察類布局,可以看到F中內嵌的E對象,其指針與F指針並不相同。正如後文討論強制轉化和成員函數時指出的,這個偏移量會造成少量的調用開銷。
具體的編譯器實現可以自由地選擇內嵌基類和派生類的布局。VC++ 按照基類的聲明順序先排列基類實例數據,最後才排列派生類數據。 當然,派生類數據本身也是按照聲明順序布局的(本規則並非一成不變,我們會看到,當一些基類有虛函數而另一些基類沒有時,內存布局並非如此)。
2.5 虛繼承
回到我們討論的一線經理類例子。讓我們考慮這種情況:如果經理類和工人類都繼承自“雇員類”,將會發生什麼?
[cpp] view plaincopy
如果經理類和工人類都繼承自雇員類,很自然地,它們每個類都會從雇員類獲得一份數據拷貝。如 果不作特殊處理,一線經理類的實例將含有兩個 雇員類實例,它們分別來自兩個雇員基類 。如果雇員類成員變量不多,問題不嚴重;如果成員變量眾多,則那份多余的拷貝將造成實例生成時的嚴重開銷。更糟的是,這兩份不同的雇員實例可能分別被修改,造成數據的不一致。因此,我們需要讓經理類和工人類進行特殊的聲明,說明它們願意共享一份雇員基類實例數據。
很不幸,在C++中,這種“共享繼承”被稱為“虛繼承”,把問題搞得似乎很抽象。虛繼承的語法很簡單,在指定基類時加上virtual關鍵字即可。
[cpp] view plaincopy
使用虛繼承,比起單繼承和多重繼承有更大的實現開銷、調用開銷。回憶一下,在單繼承和多重繼承的情況下,內嵌的基類實例地址比起派生類實例地址來,要麼地址相同(單繼承,以及多重繼承的最靠左基類) ,要麼地址相差一個固定偏移量(多重繼承的非最靠左基類) 。 然而,當虛繼承時,一般說來,派生類地址和其虛基類地址之間的偏移量是不固定的,因為如果這個派生類又被進一步繼承的話,最終派生類會把共享的虛基類實例數據放到一個與上一層派生類不同的偏移量處。請看下例:
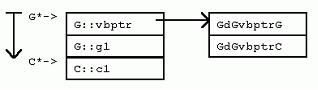
[c-sharp] view plaincopy
譯者注:GdGvbptrG(In G, the displacement of G’s virtual base pointer to G)意思是:在G中,G對象的指針與G的虛基類表指針之間的偏移量,在此可見為0,因為G對象內存布局第一項就是虛基類表指針; GdGvbptrC(In G, the displacement of G’s virtual base pointer to C)意思是:在G中,C對象的指針與G的虛基類表指針之間的偏移量,在此可見為8。
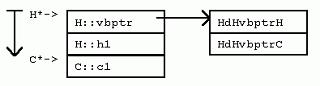
[cpp] view plaincopy
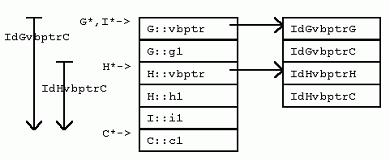
[cpp] view plaincopy
暫時不追究vbptr成員變量從何而來。從上面這些圖可以直觀地看到,在G對象中,內嵌的C基類對象的數據緊跟在G的數據之後,在H對象中,內嵌的C基類對象的數據也緊跟在H的數據之後。但是,在I對象中,內存布局就並非如此了。VC++實現的內存布局中,G對象實例中G對象和C對象之間的偏移,不同於I對象實例中G對象和C對象之間的偏移。當使用指針訪問虛基類成員變量時,由於指針可以是指向派生類實例的基類指針,所以,編譯器不能根據聲明的指針類型計算偏移,而必須找到另一種間接的方法,從派生類指針計算虛基類的位置。
在VC++ 中,對每個繼承自虛基類的類實例,將增加一個隱藏的“虛基類表指針”(vbptr)成員變量,從而達到間接計算虛基類位置的目的。該變量指向一個全類共享的偏移量表,表中項目記錄了對於該類 而言,“虛基類表指針”與虛基類之間的偏移量。
其它的實現方式中,有一種是在派生類中使用指針成員變量。這些指針成員變量指向派生類的虛基類,每個虛基類一個指針。這種方式的優點是:獲取虛基類地址時,所用代碼比較少。然而,編譯器優化代碼時通常都可以采取措施避免重復計算虛基類地址。況且,這種實現方式還有一個大弊端:從多個虛基類派生時,類實例將占用更多的內存空間;獲取虛基類的虛基類的地址時,需要多次使用指針,從而效率較低等等。
在VC++中,G擁有一個隱藏的“虛基類表指針”成員,指向一個虛基類表,該表的第二項是G dGvbptrC。(在G中,虛基類對象C的地址與G的“虛基類表指針”之間的偏移量( 當對於所有的派生類來說偏移量不變時,省略“d”前的前綴))。比如,在32位平台上,GdGvptrC是8個字節。同樣,在I實例中的G對象實例也有 “虛基類表指針”,不過該指針指向一個適用於“G處於I之中”的虛基類表,表中一項為IdGvbptrC,值為20。
觀察前面的G、H和I, 我們可以得到如下關於VC++虛繼承下內存布局的結論:
1 首先排列非虛繼承的基類實例;
2 有虛基類時,為每個基類增加一個隱藏的vbptr,除非已經從非虛繼承的類那裡繼承了一個vbptr;
3 排列派生類的新數據成員;
4 在實例最後,排列每個虛基類的一個實例。
該布局安排使得虛基類的位置隨著派生類的不同而“浮動不定”,但是,非虛基類因此也就湊在一起,彼此的偏移量固定不變。
3 成員變量
介紹了類布局之後,我們接著考慮對不同的繼承方式,訪問成員變量的開銷究竟如何。
沒有繼承: 沒有任何繼承關系時,訪問成員變量和C語言的情況完全一樣:從指向對象的指針,考慮一定的偏移量即可。
譯者注:pc是指向C的指針。
a. 訪問C的成員變量c1,只需要在pc上加上固定的偏移量dCc1(在C中,C指針地址與其c1成員變量之間的偏移量值),再獲取該指針的內容即可。
單繼承: 由於派生類實例與其基類實例之間的偏移量是常數0,所以,可以直接利用基類指針和基類成員之間的偏移量關系,如此計算得以簡化。
[cpp] view plaincopy
譯者注:D從C單繼承,pd為指向D的指針。
a. 當訪問基類成員c1時,計算步驟本來應該為“pd+dDC+dCc1”,即為先計算D對象和C對象之間的偏移,再在此基礎上加上C對象指針與成員變量c1 之間的偏移量。然而,由於dDC恆定為0,所以直接計算C對象地址與c1之間的偏移就可以了。
b. 當訪問派生類成員d1時,直接計算偏移量。
多重繼承 :雖然派生類與某個基類之間的偏移量可能不為0,然而,該偏移量總是一個常數。只要是個常數,訪問成員變量,計算成員變量偏移時的計算就可以被簡化。可見即使對於多重繼承來說,訪問成員變量開銷仍然不大。
[cpp] view plaincopy
譯者注:F繼承自C和E,pf是指向F對象的指針。
a. 訪問C類成員c1時,F對象與內嵌C對象的相對偏移為0,可以直接計算F和c1的偏移;
b. 訪問E類成員e1時,F對象與內嵌E對象的相對偏移是一個常數,F和e1之間的偏移計算也可以被簡化;
c. 訪問F自己的成員f1時,直接計算偏移量。
虛繼承: 當類有虛基類時,訪問非虛基類的成員仍然是計算固定偏移量的問題。然而,訪問虛基類的成員變量,開銷就增大了 ,因為必須經過如下步驟才能獲得成員變量的地址:
1. 獲取“虛基類表指針”;
2. 獲取虛基類表中某一表項的內容;
3. 把內容中指出的偏移量加到“虛基類表指針”的地址上。
然而,事情並非永遠如此。正如下面訪問I對象的c1成員那樣,如果不是通過指針訪問,而是直接通過對象實例,則派生類的布局可以在編譯期間靜態獲得,偏移量也可以在編譯時計算,因此也就不必要根據虛基類表的表項來間接計算了。
[cpp] view plaincopy
譯者注:I繼承自G和H,G和H的虛基類是C,pi是指向I對象的指針。
a. 訪問虛基類C的成員c1時,dIGvbptr是“在I中,I對象指針與G的“虛基類表指針”之間的偏移”,*(pi + dIGvbptr)是虛基類表的開始地址,*(pi + dIGvbptr)[1]是虛基類表的第二項的內容(在I對象中,G對象的“虛基類表指針”與虛基類之間的偏移),dCc1是C對象指針與成員變量c1之間的偏移;
b. 訪問非虛基類G的成員g1時,直接計算偏移量;
c. 訪問非虛基類H的成員h1時,直接計算偏移量;
d. 訪問自身成員i1時,直接使用偏移量;
e. 當聲明了一個對象實例,用點“.”操作符訪問虛基類成員c1時,由於編譯時就完全知道對象的布局情況,所以可以直接計算偏移量。
當訪問類繼承層次中,多層虛基類的成員變量時,情況又如何呢?比如,訪問虛基類的虛基類的成員變量時?一些實現方式為:保存一個指向直接虛基類的指針,然後就可以從直接虛基類找到它的虛基類,逐級上推。VC++優化了這個過程。 VC++在虛基類表中增加了一些額外的項,這些項保存了從派生類到其各層虛基類的偏移量。
4 強制轉化
如果沒有虛基類的問題,將一個指針強制轉化為另一個類型的指針代價並不高昂。如果在要求轉化的兩個指針之間有“基類-派生類”關系,編譯器只需要簡單地在兩者之間加上或者減去一個偏移量即可(並且該量還往往為0)。
[cpp] view plaincopy
C和E是F的基類,將F的指針pf轉化為C*或E*,只需要將pf加上一個相應的偏移量。轉化為C類型指針C*時,不需要計算,因為F和C之間的偏移量為 0。轉化為E類型指針E*時,必須在指針上加一個非0的偏移常量dFE。C ++規范要求NULL指針在強制轉化後依然為NULL,因此在做強制轉化需要的運算之前,VC++會檢查指針是否為NULL。當然,這個檢查只有當指針被顯示或者隱式轉化為相關類型指針時才進行;當在派生類對象中調用基類的方法,從而派生類指針在後台被轉化為一個基類的Const “this” 指針時,這個檢查就不需要進行了,因為在此時,該指針一定不為NULL。
正如你猜想的,當繼承關系中存在虛基類時,強制轉化的開銷會比較大。具體說來,和訪問虛基類成員變量的開銷相當。
[cpp] view plaincopy
譯者注:pi是指向I對象的指針,G,H是I的基類,C是G,H的虛基類。
a. 強制轉化pi為G*時,由於G*和I*的地址相同,不需要計算;
b. 強制轉化pi為H*時,只需要考慮一個常量偏移;
c. 強制轉化pi為C*時,所作的計算和訪問虛基類成員變量的開銷相同,首先得到G的虛基類表指針,再從虛基類表的第二項中取出G到虛基類C的偏移量,最後根據pi、虛基類表偏移和虛基類C與虛基類表指針之間的偏移計算出C*。
一般說來,當從派生類中訪問虛基類成員時,應該先強制轉化派生類指針為虛基類指針,然後一直使用虛基類指針來訪問虛基類成員變量。這樣做,可以避免每次都要計算虛基類地址的開銷。見下例。
/* before: */ ... pi->c1 ... pi->c1 ...
/* faster: */ C* pc = pi; ... pc->c1 ... pc->c1 ...
譯者注:前者一直使用派生類指針pi,故每次訪問c1都有計算虛基類地址的較大開銷;後者先將pi轉化為虛基類指針pc,故後續調用可以省去計算虛基類地址的開銷。
5 成員函數
一個C++成員函數只是類范圍內的又一個成員。X類每一個非靜態的成員函數都會接受一個特殊的隱藏參數——this指針,類型為X* const。該指針在後台初始化為指向成員函數工作於其上的對象。同樣,在成員函數體內,成員變量的訪問是通過在後台計算與this指針的偏移來進行。
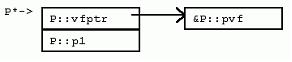
[cpp] view plaincopy
P有一個非虛成員函數pf(),以及一個虛成員函數pvf()。很明顯,虛成員函數造成對象實例占用更多內存空間,因為虛成員函數需要虛函數表指針。這一點以後還會談到。這裡要特別指出的是,聲明非虛成員函數不會造成任何對象實例的內存開銷。現在,考慮P::pf()的定義。
[cpp] view plaincopy
這裡P:pf()接受了一個隱藏的this指針參數,對於每個成員函數調用,編譯器都會自動加上這個參數。同時,注意成員變量訪問也許比看起來要代價高昂一些,因為成員變量訪問通過this指針進行,在有的繼承層次下,this指針需要調整,所以訪問的開銷可能會比較大。然而,從另一方面來說,編譯器通常會把this指針緩存到寄存器中,所以,成員變量訪問的代價不會比訪問局部變量的效率更差。
譯者注:訪問局部變量,需要到SP寄存器中得到棧指針,再加上局部變量與棧頂的偏移。在沒有虛基類的情況下,如果編譯器把this指針緩存到了寄存器中,訪問成員變量的過程將與訪問局部變量的開銷相似。
5.1 覆蓋成員函數
和成員變量一樣,成員函數也會被繼承。與成員變量不同的是,通過在派生類中重新定義基類函數,一個派生類可以覆蓋,或者說替換掉基類的函數定義。覆蓋是靜態 (根據成員函數的靜態類型在編譯時決定)還是動態 (通過對象指針在運行時動態決定),依賴於成員函數是否被聲明為“虛函數”。
Q從P繼承了成員變量和成員函數。Q聲明了pf(),覆蓋了P::pf()。Q還聲明了pvf(),覆蓋了P::pvf()虛函數。Q還聲明了新的非虛成員函數qf(),以及新的虛成員函數qvf()。
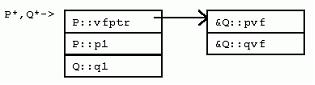
[cpp] view plaincopy
對於非虛 的成員函數來說,調用哪個成員函數是在編譯時,根據“->”操作符左邊指針表達式的類型靜態決定 的。特別地,即使ppq指向Q的實例,ppq->pf()仍然調用的是P::pf(),因為ppq被聲明為“P*”。(注意,“->”操作符左邊的指針類型決定隱藏的this參數的類型。)
[cpp] view plaincopy
譯者注:標記“錯誤”處,P*似應為Q*。因為pf非虛函數,而pq的類型為Q*,故應該調用到Q的pf函數上,從而該函數應該要求一個Q* const類型的this指針。
對於虛函數調用來說,調用哪個成員函數在運行時 決定。不管“->”操作符左邊的指針表達式的類型如何,調用的虛函數都是由指針實際指向的實例類型所決定。比如,盡管ppq的類型是P*,當ppq指向Q的實例時,調用的仍然是Q::pvf()。
[cpp] view plaincopy
譯者注:標記“錯誤”處,P*似應為Q*。因為pvf是虛函數,pq本來就是Q*,又指向Q的實例,從哪個方面來看都不應該是P*。
為了實現這種機制,引入了隱藏的vfptr 成員變量。 一個vfptr被加入到類中(如果類中沒有的話),該vfptr指向類的虛函數表(vftable)。類中每個虛函數在該類的虛函數表中都占據一項。每項保存一個對於該類適用的虛函數的地址。因此,調用虛函數的過程如下:取得實例的vfptr;通過vfptr得到虛函數表的一項;通過虛函數表該項的函數地址間接調用虛函數。也就是說,在普通函數調用的參數傳遞、調用、返回指令開銷外,虛函數調用還需要額外的開銷。
回頭再看看P和Q的內存布局,可以發現,VC++編譯器把隱藏的vfptr成員變量放在P和Q實例的開始處。這就使虛函數的調用能夠盡量快一些。實際上,VC++的實現方式是,保證任何有虛函數的類的第一項永遠是vfptr。這就可能要求在實例布局時,在基類前插入新的vfptr,或者要求在多重繼承時,雖然在右邊,然而有vfptr的基類放到左邊沒有vfptr的基類的前面(如下)。
[cpp] view plaincopy
對於CL類,它的內存布局是:
int b;
int a;
int c;
但是,改造CA如下:
[cpp] view plaincopy
對於同樣繼承順序的CL,內存布局是:
vfptr;
int a;
int b;
int c;
許多C++的實現會共享或者重用從基類繼承來的vfptr。比如,Q並不會有一個額外的vfptr,指向一個專門存放新的虛函數qvf()的虛函數表。Qvf項只是簡單地追加到P的虛函數表的末尾。如此一來,單繼承的代價就不算高昂。一旦一個實例有vfptr了,它就不需要更多的vfptr。新的派生類可以引入更多的虛函數,這些新的虛函數只是簡單地在已存在的,“每類一個”的虛函數表的末尾追加新項。
5.2 多重繼承下的虛函數
如果從多個有虛函數的基類繼承,一個實例就有可能包含多個vfptr。考慮如下的R和S類:
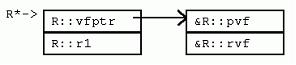
[cpp] view plaincopy
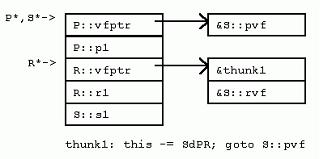
[cpp] view plaincopy
這裡R是另一個包含虛函數的類。因為S從P和R多重繼承,S的實例內嵌P和R的實例,以及S自身的數據成員S::s1。注意,在多重繼承下,靠右的基類R,其實例的地址和P與S不同。S::pvf覆蓋了P::pvf()和R::pvf(),S::rvf()覆蓋了R::rvf()。
[cpp] view plaincopy
譯者注:
調用((P*)ps)->pvf()時,先到P的虛函數表中取出第一項,然後把ps轉化為S*作為this指針傳遞進去;
調用((R*)ps)->pvf()時,先到R的虛函數表中取出第一項,然後把ps轉化為S*作為this指針傳遞進去;
因為S::pvf()覆蓋了P::pvf()和R::pvf(),在S的虛函數表中,相應的項也應該被覆蓋。然而,我們很快注意到,不光可以用P*,還可以用R*來調用pvf()。問題出現了:R的地址與P和S的地址不同。表達式 (R*)ps與表達式(P*)ps指向類布局中不同的位置。因為函數S::pvf希望獲得一個S*作為隱藏的this指針參數,虛函數必須把R*轉化為 S*。因此,在S對R虛函數表的拷貝中,pvf函數對應的項,指向的是一個“調整塊”的地址,該調整塊使用必要的計算,把R*轉換為需要的S*。
譯者注:這就是“thunk1: this-= sdPR; goto S::pvf”干的事。先根據P和R在S中的偏移,調整this為P*,也就是S*,然後跳轉到相應的虛函數處執行。
在微軟VC++實現中,對於有虛函數的多重繼承,只有當派生類虛函數覆蓋了多個基類的虛函數時,才使用調整塊。
5.3 地址點與“邏輯this調整”
考慮下一個虛函數S::rvf(),該函數覆蓋了R::rvf()。我們都知道S::rvf()必須有一個隱藏的S*類型的this參數。但是,因為也可以用R*來調用rvf(),也就是說,R的rvf虛函數槽可能以如下方式被用到:
[cpp] view plaincopy
所以,大多數實現用另一個調整塊將傳遞給rvf的R*轉換為S*。還有一些實現在S的虛函數表末尾添加一個特別的虛函數項,該虛函數項提供方法,從而可以直接調用ps->rvf(),而不用先轉換R*。MSC++的實現不是這樣,MSC++有意將S::rvf編譯為接受一個指向S中嵌套的R實例,而非指向S實例的指針(我們稱這種行為是“給派生類的指針類型與該虛函數第一次被引入時接受的指針類型相同”)。所有這些在後台透明發生,對成員變量的存取,成員函數的this指針,都進行“邏輯this調整”。
當然,在debugger中,必須對這種this調整進行補償。
[cpp] view plaincopy
譯者注:調用rvf虛函數時,直接給入R*作為this指針。
所以,當覆蓋非最左邊的基類的虛函數時,MSC++一般不創建調整塊,也不增加額外的虛函數項。
5.4 調整塊
正如已經描述的,有時需要調整塊來調整this指針的值(this指針通常位於棧上返回地址之下,或者在寄存器中),在this指針上加或減去一個常量偏移,再調用虛函數。某些實現(尤其是基於cfront的)並不使用調整塊機制。它們在每個虛函數表項中增加額外的偏移數據。每當虛函數被調用時,該偏移數據(通常為0),被加到對象的地址上,然後對象的地址再作為this指針傳入。
ps->rvf();[cpp] view plaincopy
譯者注:當調用rvf虛函數時,前一句表示虛函數表每一項是一個結構,結構中包含偏移量;後一句表示調用第i個虛函數時,this指針使用保存在虛函數表中第i項的偏移量來進行調整。
這種方法的缺點是虛函數表增大了,虛函數的調用也更加復雜。
現代基於PC的實現一般采用“調整—跳轉”技術:
[cpp] view plaincopy
當然,下面的代碼序列更好(然而,當前沒有任何實現采用該方法):
S::pvf-adjust:
[cpp] view plaincopy
譯者注:IBM的C++編譯器使用該方法。
5.5 虛繼承下的虛函數
T虛繼承P,覆蓋P的虛成員函數,聲明了新的虛函數。如果采用在基類虛函數表末尾添加新項的方式,則訪問虛函數總要求訪問虛基類。在VC++中,為了避免獲取虛函數表時,轉換到虛基類P的高昂代價,T中的新虛函數通過一個新的虛函數表 獲取,從而帶來了一個新的虛函數表指針。該指針放在T實例的頂端。
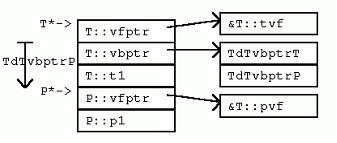
[cpp] view plaincopy
如上所示,即使是在虛函數中,訪問虛基類的成員變量也要通過獲取虛基類表的偏移,實行計算來進行。這樣做之所以必要,是因為虛函數可能被進一步繼承的類所覆蓋,而進一步繼承的類的布局中,虛基類的位置變化了。下面就是這樣的一個類:
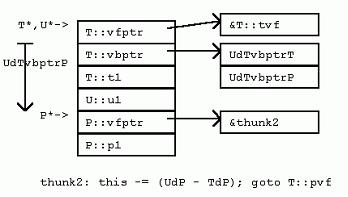
[cpp] view plaincopy
在此U增加了一個成員變量,從而改變了P的偏移。因為VC++實現中,T::pvf()接受的是嵌套在T中的P的指針,所以,需要提供一個調整塊,把this指針調整到T::t1之後(該處即是P在T中的位置)。
5.6 特殊成員函數
本節討論編譯器合成到特殊成員函數中的隱藏代碼。
5.6.1 構造函數和析構函數
正如我們所見,在構造和析構過程中,有時需要初始化一些隱藏的成員變量。最壞的情況下,一個構造函數要執行如下操作:
1 * 如果是“最終派生類”,初始化vbptr成員變量,調用虛基類的構造函數;
2 * 調用非虛基類的構造函數
3 * 調用成員變量的構造函數
4 * 初始化虛函數表成員變量
5 * 執行構造函數體中,程序所定義的其他初始化代碼
(注意:一個“最終派生類”的實例,一定不是嵌套在其他派生類實例中的基類實例)
所以,如果你有一個包含虛函數的很深的繼承層次,即使該繼承層次由單繼承構成,對象的構造可能也需要很多針對虛函數表的初始化。
反之,析構函數必須按照與構造時嚴格相反的順序來“肢解”一個對象。
1 * 合成並初始化虛函數表成員變量
2 * 執行析構函數體中,程序定義的其他析構代碼
3 * 調用成員變量的析構函數(按照相反的順序)
4 * 調用直接非虛基類的析構函數(按照相反的順序)
5 * 如果是“最終派生類”,調用虛基類的析構函數(按照相反順序)
在VC++中,有虛基類的類的構造函數接受一個隱藏的“最終派生類標志”,標示虛基類是否需要初始化。對於析構函數,VC++采用“分層析構模型”,代碼中加入一個隱藏的析構函數,該函數被用於析構包含虛基類的類(對於 “最終派生類”實例而言);代碼中再加入另一個析構函數,析構不包含虛基類的類。前一個析構函數調用後一個。
5.6.2 虛析構函數與delete操作符
假如A是B的父類,
A* p = new B();
如果析構函數不是虛擬的,那麼,你後面就必須這樣才能安全的刪除這個指針:
delete (B*)p;
但如果構造函數是虛擬的,就可以在運行時動態綁定到B類的析構函數,直接:
delete p;
就可以了。這就是虛析構函數的作用。
實際上,很多人這樣總結:當且僅當類裡包含至少一個虛函數的時候才去聲明虛析構函數。
考慮結構V和W。

[cpp] view plaincopy

struct W : V {
[cpp] view plaincopy
析構函數可以為虛。一個類如果有虛析構函數的話,將會象有其他虛函數一樣,擁有一個虛函數表指針,虛函數表中包含一項,其內容為指向對該類適用的虛析構函數的地址。這些機制和普通虛函數相同。虛析構函數的特別之處在於:當類實例被銷毀時,虛析構函數被隱含地調用。調用地(delete發生的地方)雖然不知道銷毀的動態類型,然而,要保證調用對該類型合適的delete操作符。例如,當pv指向W的實例時,當W::~W被調用之後,W實例將由W類的delete操作符來銷毀。
V* pv = new V;
[cpp] view plaincopy
譯者注:
V沒有定義delete操作符,delete時使用函數庫的delete操作符;
W定義了delete操作符,delete時使用自己的delete操作符;
可以用全局范圍標示符顯示地調用函數庫的delete操作符。
為了實現上述語意,VC++擴展了其“分層析構模型”,從而自動創建另一個隱藏的析構幫助函數——“deleting析構函數”,然後,用該函數的地址來替換虛函數表中“實際”虛析構函數的地址。析構幫助函數調用對該類合適的析構函數,然後為該類有選擇性地調用合適的delete操作符。
6 數組
堆上分配空間的數組使虛析構函數進一步復雜化。問題變復雜的原因有兩個:
1、 堆上分配空間的數組,由於數組可大可小,所以,數組大小值應該和數組一起保存。因此,堆上分配空間的數組會分配額外的空間來存儲數組元素的個數;
2、 當數組被刪除時,數組中每個元素都要被正確地釋放,即使當數組大小不確定時也必須成功完成該操作。然而,派生類可能比基類占用更多的內存空間,從而使正確釋放比較困難。
[cpp] view plaincopy
譯者注:WW從W繼承,增加了一個成員變量,因此,WW占用的內存空間比W大。然而,不管指針pv指向W的數組還是WW的數組,delete[]都必須正確地釋放WW或W對象占用的內存空間。
雖然從嚴格意義上來說,數組delete的多態行為C++標准並未定義,然而,微軟有一些客戶要求實現該行為。因此,在MSC++中,該行為是用另一個編譯器生成的虛析構幫助函數來完成。該函數被稱為“向量delete析構函數”(因其針對特定的類定制,比如WW,所以,它能夠遍歷數組的每個元素,調用對每個元素適用的析構函數)。
7 異常處理
簡單說來,異常處理是C++標准委員會工作文件提供的一種機制,通過該機制,一個函數可以通知其調用者“異常”情況的發生,調用者則能據此選擇合適的代碼來處理異常。該機制在傳統的“函數調用返回,檢查錯誤狀態代碼”方法之外,給程序提供了另一種處理錯誤的手段。
因為C++是面向對象的語言,很自然地,C++中用對象來表達異常狀態。並且,使用何種異常處理也是基於“拋出的”異常對象的靜態或動態類型來決定的。不光如此,既然C++總是保證超出范圍的對象能夠被正確地銷毀,異常實現也必須保證當控制從異常拋出點轉換到異常“捕獲”點時(棧展開),超出范圍的對象能夠被自動、正確地銷毀。
考慮如下例子:
[cpp] view plaincopy
譯者注:X是異常類,Z是帶析構函數的工作類,recover是錯誤處理函數,f和g一起產生異常條件,g實際拋出異常。
這段程序會拋出異常。在main中,加入了處理異常的try & catch框架,當調用f(0)時,f構造z1,調用g(0)後,再構造z2,再調用g(-1),此時g發現參數為負,拋出X異常對象。我們希望在某個調用層次上,該異常能夠得到處理。既然g和f都沒有建立處理異常的框架,我們就只能希望main函數建立的異常處理框架能夠處理X異常對象。實際上,確實如此。當控制被轉移到main中異常捕獲點時,從g中的異常拋出點到main中的異常捕獲點之間,該范圍內的對象都必須被銷毀。在本例中,z2和z1應該被銷毀。
談到異常處理的具體實現方式,一般情況下,在拋出點和捕獲點都使用“表”來表述能夠捕獲異常對象的類型;並且,實現要保證能夠在特定的捕獲點真正捕獲特定的異常對象;一般地,還要運用拋出的對象來初始化捕獲語句的“實參”。通過合理地選擇編碼方案,可以保證這些表格不會占用過多的內存空間。
異常處理的開銷到底如何?讓我們再考慮一下函數f。看起來f沒有做異常處理。f確實沒有包含try,catch,或者是throw關鍵字,因此,我們會猜異常處理應該對f沒有什麼影響。錯!編譯器必須保證一旦z1被構造,而後續調用的任何函數向f拋回了異常,異常又出了f的范圍時,z1對象能被正確地銷毀。同樣,一旦z2被構造,編譯器也必須保證後續拋出異常時,能夠正確地銷毀z2和z1。
要實現這些“展開”語意,編譯器必須在後台提供一種機制,該機制在調用者函數中,針對調用的函數拋出的異常動態決定異常環境(處理點)。這可能包括在每個函數的准備工作和善後工作中增加額外的代碼,在最糟糕的情況下,要針對每一套對象初始化的情況更新狀態變量。例如,上述例子中,z1應被銷毀的異常環境當然與z2和z1都應該被銷毀的異常環境不同,因此,不管是在構造z1後,還是繼而在構造z2後,VC++都要分別在狀態變量中更新(存儲)新的值。
所有這些表,函數調用的准備和善後工作,狀態變量的更新,都會使異常處理功能造成可觀的內存空間和運行速度開銷。正如我們所見,即使在沒有使用異常處理的函數中,該開銷也會發生。
幸運的是,一些編譯器可以提供編譯選項,關閉異常處理機制。那些不需要異常處理機制的代碼,就可以避免這些額外的開銷了。
8 小結
好了,現在你可以寫C++編譯器了(開個玩笑)。
在本文中,我們討論了許多重要的C++運行實現問題。我們發現,很多美妙的C++語言特性的開銷很低,同時,其他一些美妙的特性(譯者注:主要是和“虛”字相關的東西)將造成較大的開銷。C++很多實現機制都是在後台默默地為你工作。一般說來,單獨看一段代碼時,很難衡量這段代碼造成的運行時開銷,必須把這段代碼放到一個更大的環境中來考察,運行時開銷問題才能得到比較明確的答案。
轉自:http://blog.csdn.net/wangqiulin123456/article/details/8275595