m = 1; n = m+++m++;
最近有位不相識的朋友發email給我,問為什麼在某個C++系統裡,下面表達式打印出兩個4,而不是4和5:
a = 4; cout << a++ << a;
C++ 不是規定 << 操作左結合嗎?是C++ 書上寫錯了,還是這個系統的實現有問題?
; cout << a++ <<++
C/C++ 語言是“基於表達式的語言”,所有計算(包括賦值)都在表達式裡完成。“x = 1;”就是表達式
“x = 1”後加表示語句結束的分號。要弄清程序的意義,首先要理解表達式的意義,也就是:1)表達式所確定的計算過程;2)它對環境(可以把環境看作
當時可用的所有變量)的影響。如果一個表達式(或子表達式)只計算出值而不改變環境,我們就說它是引用透明的,這種表達式早算晚算對其他計算沒有影響(不
改變計算的環境。當然,它的值可能受到其他計算的影響)。如果一個表達式不僅算出一個值,還修改了環境,就說這個表達式有副作用(因為它多做了額外的事)。a++ 就是有副作用的表達式。這些說法也適用於其他語言裡的類似問題。
現在問題變成:如果C/C++ 程序裡的某個表達式(部分)有副作用,這種副作用何時才能實際體現到使用中?為使問題更清楚,我們假定程序裡有代碼片段
“...a[i]++ ... a[j] ...”,假定當時i與j的值恰好相等(a[i] 和a[j] 正好引用同一數組元素);假定a[i]++ 確
實在a[j] 之前計算;再假定其間沒有其他修改a[i] 的動作。在這些假定下,a[i]++ 對 a[i] 的修改能反映到 a[j] 的求值中嗎?
注意:由於 i 與 j 相等的問題無法靜態判定,在目標代碼裡,這兩個數組元素訪問(對內存的訪問)必然通過兩段獨立代碼完成。現代計算機的計算都在寄
存器裡做,問題現在變成:在取 a[j] 值的代碼執行之前,a[i] 更新的值是否已經被(從寄存器)保存到內存?如果了解語言在這方面的規定,這個問
題的答案就清楚了。
程序語言通常都規定了執行中變量修改的最晚實現時刻(稱為順序點、序點或執行點)。程序執行中存在一系列順序點(時
刻),語言保證一旦執行到達一個順序點,在此之前發生的所有修改(副作用)都必須實現(必須反應到隨後對同一存儲位置的訪問中),在此之後的所有修改都還
沒有發生。在順序點之間則沒有任何保證。對C/C++ 語言這類允許表達式有副作用的語言,順序點的概念特別重要。
現在上面問題的回答已經很清楚了:如果在a[i]++ 和a[j] 之間存在一個順序點,那麼就能保證a[j] 將取得修改之後的值;否則就不能保證。
C/C++語言定義(語言的參考手冊)明確定義了順序點的概念。順序點位於:
1. 每個完整表達式結束時。完整表達式包括變量初始化表達式,表達式語句,return語句的表達式,以及條件、循環和switch語句的控制表達式(for頭部有三個控制表達式);
2. 運算符 &&、||、?: 和逗號運算符的第一個運算對象計算之後;
3. 函數調用中對所有實際參數和函數名表達式(需要調用的函數也可能通過表達式描述)的求值完成之後(進入函數體之前)。
假設時刻ti和ti+1是前後相繼的兩個順序點,到了ti+1,任何C/C++ 系統(VC、BC等都是C/C++系統)都必須實現ti之後發生的所有副
作用。當然它們也可以不等到時刻ti+1,完全可以選擇在時段 [t, ti+1] 之間的任何時刻實現在此期間出現的副作用,因為C/C++ 語言允許
這些選擇。
前面討論中假定了a[i]++ 在a[i] 之前做。在一個程序片段裡a[i]++ 究竟是否先做,還與它所在的表達式確定的計算過程有關。我們都熟悉C/C++ 語言有關優先級、結合性和括號的規定,而出現多個運算對象時的計算順序卻常常被人們忽略。看下面例子:
(a + b) * (c + d) fun(a++, b, a+5)
這裡“*”的兩個運算對象中哪個先算?fun及其三個參數按什麼順序計算?對第一個表達式,采用任何計算順序都沒關系,因為其中的子表達式都是引用透明的。
第二個例子裡的實參表達式出現了副作用,計算順序就非常重要了。少數語言明確規定了運算對象的計算順序(Java規定從左到右),C/C++ 則有意不予
規定,既沒有規定大多數二元運算的兩個對象的計算順序(除了&&、|| 和 ,),也沒有規定函數參數和被調函數的計算順序。在計算第二
個表達式時,首先按照某種順序算fun、a++、b和a+5,之後是順序點,而後進入函數執行。
不少書籍在這些問題上有錯(包括一些很流行的書)。例如說C/C++ 先算左邊(或右邊),或者說某個C/C++ 系統先計算某一邊。這些說法都是錯誤
的!一個C/C++ 系統可以永遠先算左邊或永遠先算右邊,也可以有時先算左邊有時先算右邊,或在同一表達式裡有時先算左邊有時先算右邊。不同系統可能采
用不同的順序(因為都符合語言標准);同一系統的不同版本完全可以采用不同方式;同一版本在不同優化方式下,在不同位置都可能采用不同順序。因為這些做法
都符合語言規范。在這裡還要注意順序點的問題:即使某一邊的表達式先算了,其副作用也可能沒有反映到內存,因此對另一邊的計算沒有影響。
回到前面的例子:“誰知道下面C語句給n賦什麼值?”
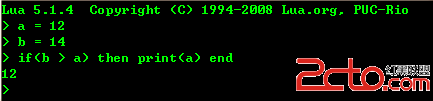
m = 1; n = m++ +m++;
正確回答是:語言沒有規定它應該算出什麼,結果完全依賴具體系統在具體上下文中的具體處理。其中牽涉到運算對象的求值順序和變量修改的實現時刻問題。對於:
cout << a++ << a;
我們知道它是
(cout.operator <<(a++)).operator << (a);
的簡寫。先看外層函數調用,這裡需要算出所用函數,還需要計算a的值。語言沒有規定哪個先算。如果真的先算函數,這一計算中出現了另一次函數調用,在被調
函數體執行前有一個順序點,那時a++的副作用就會實現。如果是先算參數,求出a的值4,而後計算函數時的副作用當然不會改變它(這種情況下輸出兩個
4)。當然,這些只是假設,實際應該說的是:這種東西根本不該寫,討論其效果沒有意義。
有人可能說,為什麼人們設計 C/C++時不把順序規定清楚,免去這些麻煩?C/C++ 語言的做法完全是有意而為,其目的就是允許編譯器采用任何求值順序,使編譯器在優化中可以根據需要調整實現表達式求值的指令序列,以得到效率更高的代碼。像
Java那樣嚴格規定表達式的求值順序和效果,不僅限制了語言的實現方式,還要求更頻繁的內存訪問(以實現副作用),這些可能帶來可觀的效率損失。應該
說,在這個問題上,C/C++和Java的選擇都貫徹了它們各自的設計原則,各有所獲(C/C++ 潛在的效率,Java更清晰的程序行為),當然也都有
所失。還應該指出,大部分程序設計語言實際上都采用了類似C/C++的規定。
討論了這麼多,應該得到什麼結論呢?C/C++ 語言的規定告訴我們,任何依賴於特定計算順序、依賴於在順序點之間實現修改效果的表達式,其結果都沒有保證。程序設計中應該貫徹的規則是:注意:這裡的問題不是在某個系統裡試一試的問題,因為我們不可能試驗所有可能的表達式組合形式以及所有可能的上下文。這裡討論的是語言,而不是某個實現。總而言之,絕不要寫這種表達式,否則我們或早或晚會某種環境中遇到麻煩。
後記:去年參加一個學術會議,看到有同行寫文章討論某個C系統裡表達式究竟按什麼順序求值,並總結出一些“規律”。從討論中了解到某“程序員水平考試”出
了這類題目。這使我感到很不安。今年給一個教師學習班講課,發現許多專業課教師也對這一基本問題也不甚明了,更覺得問題確實嚴重。因此整理出這篇短文供大
家參考。
後後記:4年多過去了,許多新的和老的教科書仍然在不厭其煩地討論在C語言裡原本並無意義的問題(如本文所指出的)。希望學習和使用C語言的人不要陷入其中。