模板元編程(template metaprogramming TMP)是實現基於模板的C++程序的過程,它能夠在編譯期執行。你可以想一想:一個模板元程序是用C++實現的並且可以在C++編譯器內部運行的一個程序,它的輸出——從模板中實例化出來的C++源碼片段——會像往常一樣被編譯。
如果這沒有沖擊到你,是因為你沒有足夠盡力去想。
C++不是為了模板元編程而設計的,但是自從TMP早在1990年被發現之後,它就被證明是非常有用的,為了使TMP的使用更加容易,在C++語言和標准庫中加入了一些擴展。是的,TMP是被發現的,而不是被發明。當模板被添加到C++中的時候TMP這個特性就被引入了。對於某些人來說所有需要做的就是關注如何以一種聰明的和意想不到的方式來使用它。
TMP有兩種強大的力量。第一,它使得一些事情變得容易,也即是說如果沒有TMP,這些事情做起來很難或者不可能實現。第二,因為模板元編程在C++編譯期執行,它們可以將一些工作從運行時移動到編譯期。一個結果就是一些原來通常在運行時能夠被發現的錯誤,現在在編譯期就能夠被發現了。另外一個結果就是使用TMP的C++程序在基本上每個方面都更加高效:更小的執行體,更短的運行時間,更少的內存需求。(然而,將工作從運行時移到編譯期的一個後果就是編譯時間增加了。使用TMP的程序比沒有使用TMP的程序可能消耗更長的時間來進行編譯。)
考慮在Item 47中為STL的advance寫出來的偽代碼。我已經為偽代碼部分做了粗體:
1 template<typename IterT, typename DistT>
2 void advance(IterT& iter, DistT d)
3 {
4 if (iter is a random access iterator) {
5
6 iter += d; // use iterator arithmetic
7
8 } // for random access iters
9
10 else {
11
12
13 if (d >= 0) { while (d--) ++iter; } // use iterative calls to
14 else { while (d++) --iter; } // ++ or -- for other
15 } // iterator categories
16 }
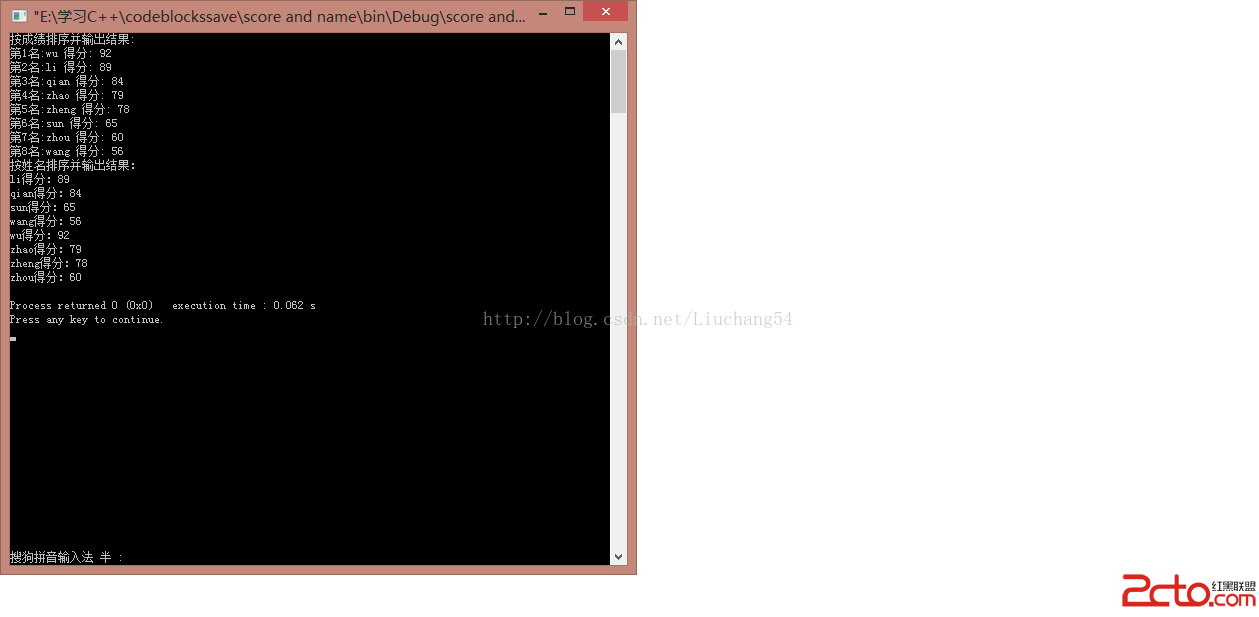
我們可以使用typeid替換偽代碼,讓程序能夠執行。這就產生了一個“普通的”C++方法——也就是所有工作都在運行時開展的方法:
1 template<typename IterT, typename DistT>
2 void advance(IterT& iter, DistT d)
3 {
4 if ( typeid(typename std::iterator_traits<IterT>::iterator_category) ==
5 typeid(std::random_access_iterator_tag)) {
6
7 iter += d; // use iterator arithmetic
8
9 } // for random access iters
10
11 else {
12
13
14 if (d >= 0) { while (d--) ++iter; } // use iterative calls to
15 else { while (d++) --iter; } // ++ or -- for other
16 } // iterator categories
17 }
Item 47指出這種基於typeid的方法比使用trait效率更低,因為通過使用這種方法,(1)類型測試發生在運行時而不是編譯期(2)執行運行時類型測試的代碼在運行的時候必須可見。事實上,這個例子也展示出了為什麼TMP比一個“普通的”C++程序更加高效,因為traits方式屬於TMP。記住,trait使得在類型上進行編譯期if…else運算成為可能。
我已經在前面提到過一些東西說明其在TMP中比在“普通”C++中更加容易,Item 47中也提供了一個advance的例子。Item 47中提到了advance的基於typeid的實現會導致編譯問題,看下面的例子:
1 std::list<int>::iterator iter; 2 ... 3 advance(iter, 10); // move iter 10 elements forward; 4 // won’t compile with above impl.
考慮為上面調用所產生的advance的版本,將模板參數IterT和DistT替換為iter和10的類型之後,我們得到下面的代碼:
1 void advance(std::list<int>::iterator& iter, int d)
2 {
3 if (typeid(std::iterator_traits<std::list<int>::iterator>::iterator_category) ==
4 typeid(std::random_access_iterator_tag)) {
5
6 iter += d;
7
8 // error! won’t compile
9
10
11 }
12 else {
13 if (d >= 0) { while (d--) ++iter; }
14 else { while (d++) --iter; }
15 }
16 }
有問題的是高亮部分,就是使用+=的語句。在這個例子中,我們在list<int>::iterator上使用+=,但是list<int>::iterator是一個雙向迭代器(見Item 47),所以它不支持+=。只有隨機訪問迭代器支持+=。現在,我們知道了+=這一行將永遠不會被執行到,因為為list<int>::iteraotr執行的typeid測試永遠都不會為真,但是編譯器有責任確保所有的源碼都是有效的,即使不被執行到,當iter不是隨機訪問迭代器“iter+=d”就是無效代碼。將它同基於tratis的TMP解決方案進行比較,後者把為不同類型實現的代碼分別放到了不同的函數中,每個函數中進行的操作只針對特定的類型。
TMP已經被證明是圖靈完全的(Turing-Complete),這也就意味著它足夠強大到可以計算任何東西。使用TMP,你可以聲明變量,執行循環,實現和調用函數等等。但是這些概念同“普通”C++相對應的部分看起來非常不同。例如,Item 47中if…else條件在TMP中是如何通過使用模板和模板特化來表現的。但這是程序級別(assembly-level)的TMP。TMP庫(例如,Boost MPL,見Item 55)提供了更高級別的語法,這些語法不會讓你誤認為是“普通的”C++。
再瞥一眼事情在TMP中是如何工作的,讓我們看一下循環。TMP中沒有真正的循環的概念,所以循環的效果是通過遞歸來完成的。(如果一提到遞歸你就不舒服,在進入TMP 冒險之前你就需要處理好它。TMP主要是一個函數式語言,遞歸對於函數式語言就如同電視對美國流行文化一樣重要:它們是不可分割的。)即使是遞歸也不是普通的遞歸,因為TMP循環沒有涉及到遞歸函數調用,所涉及到的是遞歸模板實例化(template instantiations)。
TMP的“hello world”程序是在編譯期計算階乘。它算不上是令人激動的程序,“hello world”也不是,但是這兩個例子對於介紹語言都是有幫助的。TMP階乘計算通過對模板實例進行遞歸來對循環進行示范。也同樣示范了變量是如何在TMP中被創建和使用的,看下面的代碼:
1 template<unsigned n> // general case: the value of
2
3 struct Factorial { // Factorial<n> is n times the value
4
5
6 // of Factorial<n-1>
7 enum { value = n * Factorial<n-1>::value };
8 };
9 template<> // special case: the value of
10 struct Factorial<0> { // Factorial<0> is 1
11 enum { value = 1 };
12 };
考慮上面的模板元編程(真的僅僅是單一的元函數Factorial),你通過引用Factorial<n>::value來得到factorial(n)的值。
代碼的循環部分發生在模板實例Factorial<n>引用模板實例Factorial<n-1>的時候。像所有遞歸一樣,有一種特殊情況來讓遞歸終止。在這裡是模板特化Factorial<0>。
每個Factorial模板的實例都是一個結構體,每個結構體使用enum hack(Item 2)來聲明一個叫做value的TMP變量。Value持有遞歸計算的當前值。如果TMP有一個真正的循環結構,value將會每次循環的時候進行更新。既然TMP使用遞歸模板實例來替換循環,每個實例會得到它自己的value的拷貝,每個拷貝都會有一個和“循環”中位置想對應的合適的值。
你可以像下面這樣使用Facorial:
1 int main()
2 {
3 std::cout << Factorial<5>::value; // prints 120
4
5 std::cout << Factorial<10>::value; // prints 3628800
6
7 }
如果你認為這比冰激凌更酷,你就已經獲得模板元程序員需要的素材。如果模板和特化,遞歸實例和enum hacks,還有像Factorial<n-1>::value這樣的輸入使你毛骨悚然,你還是一個“普通的”C++程序員。
當然,Factorial對TMP的功能進行了示范,如同“hello world”程序對任何傳統編程語言的功能進行示范一樣。為了讓你明白為什麼TMP是值得了解的,知道它能夠做什麼很重要,這裡有三個例子:
1 typedef SquareMatrix<double, 10000> BigMatrix; 2 BigMatrix m1, m2, m3, m4, m5; // create matrices and 3 ... // give them values 4 BigMatrix result = m1 * m2 * m3 * m4 * m5; // compute their product
用“普通的”方式來計算result會有四次創建臨時matrice對象的調用,每次調用都應用在對operator*調用的返回值上面。這些獨立的乘法在矩陣元素上產生了四 次循環。使用TMP的高級模板技術——表達式模板(expression templates),來消除臨時對象以及合並循環是有可能的,並且不用修改上面的客戶端代碼的語法。最 後的程序使用了更少的內存,而且運行速度會有很大的提升。
TMP並不是為每個人准備的。因為語法不直觀,支持的相關工具也很弱。(像為模板元編程提供的調試器。)作為一個“突然性“的語言它只是最近才被發現的,TMP編程的一些約定正在實驗階段。然而通過將工作從運行時移到編譯期所帶來的效率提升帶給人很深刻的印象,對一些行為表達的能力(很難或者不可能在運行時實現)也是很吸引人的。
對於TMP的支持正在上升期。很可能下個版本的C++就是顯示的支持它。TR1中已經支持了(Item 54)。關於這個主題的書籍已經開始出來了,網上的一些關於TMP信息也越來越多。TMP可能永遠不會成為主流,但是對於一些程序員來說——尤其是程序庫的實現者——幾乎必然會成為主要手段。