能被不同平台共享的代碼越多,跨平台的項目就越容易。所有平台上公用的功能應該被標識出來避免它們在平台相關的代碼裡重復出現。並且它們的編譯、測試和部署應該貫穿在整個生命周期中。建議隱藏到一個統一的API抽象之中去。
在工廠模式下,可以編寫一個希望暴露的功能接口,進而向每一個支持的平台提供這個功能的具體實現。在編譯或運行階段,可以根據平台的不同來具體實現,然後實例化,最後粘合到接口類中。當application調用接口類時,把平台相關的功能代理給這個具體實現。可移植功能單獨在接口類中實現,不能重復。
假如實現一個列出在系統上所有運行中的進程名字和id的函數,在 mac、linux、和windows上運行
#includeusing namespace std; class ProcessList { public : int Scan(); int GetCount(); const char * GetName(const int i); int GetPID(const int i); }; //使用上述類 int main() { ProcessList processList; processList.Scan(); for (int i = 0; i < processList.GetCount(); i++) { cout << processList.GetPID(i); cout << processList.GetName(i); } return 0; }
每個平台都有它去的進程名/id的獨特方式,這個被封裝在Scan()中,獲取數據後存在一個平台無關的數據結構中,就可以獨立於平台風格實現。需要把ProcessList類改造如下
class ProcessList {
public :
#if defined(WIN32)
int ScanWindows();
#endif
#if defined(DARWIN)
int ScanMacOSX();
#endif
#if defined(LINUX)
int ScanLinux();
#endif
int GetCount();
const char * GetName(const int i);
int GetPID(const int i);
};
對應的main方法如下
int main()
{
ProcessList processList;
#if defined(WIN32)
processList.ScanWindows();
#endif
#if defined(DARWIN)
processList.ScanMacOSX();
#endif
#if defined(LINUX)
processList.ScanLinux();
#endif
for (int i = 0; i < processList.GetCount(); i++)
{
cout << processList.GetPID(i);
cout << processList.GetName(i);
}
return 0;
}
由於scan操作的實現沒有提供任何抽象,開發人員必須不停地檢查維護每一個平台的實現,來剔除公共的代碼。所以把公共的部分提煉出來放到一個單獨的Scan函數中。回到ProcessList的原始定義中
class ProcessList {
public :
int Scan();
int GetCount();
const char * GetName(const int i);
int GetPID(const int i);
};
這個接口是平台無關的,最終執行平台相關代碼的是被調用的Scan,所以#ifdefs可以放到這一層,於是scan的實現如下
ProcessList::Scan()
{
#if defined(WIN32)
return ScanWindows();
#endif
#if defined(DARWIN)
return ScanMacOSX();
#endif
#if defined(LINUX)
return ScanLinux();
#endif
return -1;
}
最後的-1代表調用Scan()的平台沒有相關的實現,目標達成!
如果要記錄Scan()被調用這個事件,可以重寫Scan()(假設Log是一個知道怎麼正確做日志的宏,如添加時間戳)
ProcessList::Scan()
{
LOG("Scan was called!");
#if defined(WIN32)
return ScanWindows();
#endif
#if defined(DARWIN)
return ScanMacOSX();
#endif
#if defined(LINUX)
return ScanLinux();
#endif
return -1;
}
有一個需要注意的問題是為ProcessList類增加了一個新的平台相關的函數,例如增加一個改變進程優先級的函數。在UNIX下,你可以通過調用nice()函數做到這一點,nice()函數接受一個整形參數作為優先級。在windows下可以打開一個進程調用一個交SetPriorityClass()函數。類UNIX系統的返回值都有不同,Linux裡返回0代表成功,-1代表失敗。而Darwin系統上返回值就是進程的優先級,不能作為成功或失敗的標志。
可以采用相同方法,給ProcessList加一個抽象API,叫做SetPriority(),然後在函數裡用#ifdefs把平台相關的幫助函數隔離起來。隨著功能的添加,#ifdef的數量就回隨之增長。工廠模式雖然不能完全實習#ifdef是,但它會被限定在一個單獨的地方,增加代碼易讀性。
工廠模式允許我們在Scan()函數裡申請並獲得一個可以提供平台相關的實現的對象。這個對象從一個定義了平台相關實習API的基礎類上繼承而來。ProcessList維護了一個指向這個類的指針,而工廠模式則是提供這個指針的對象。Scan結構改變如下
int ProcessList::Scan() {
if (m_processsImpl)
return m_processsImpl->Scan();
return -1;
}
這裡的m_processImpl是一個指向工廠模式提供的對象的指針,可以在Scan()裡向工廠模式申請這個對象,或者是從ProcessList的構造函數裡獲得
#include "processesfactory.h"
int ProcessList::ProcessList() : m_processesImpl(NULL)
ProcessesFactory * factory = ProcessesFactory::GetProcessFactory();
if (factory)
{
m_porcessesImpl = factory->MakeProcesses();
}
}
ProcessFactory是一個singleton對象,必須通過平台無關代碼實現函數GetProcessFactory()獲得,實現GetProcessFactory()的源碼是#ifdefs出現的唯一地點:
#pragma once
class ProcessesFactory
{
#if defined(HAVE_WIN32)
#include "windows\windowsfactory.h"
#endif
#if defined(HAVE_MACOS)
#include "cocoa/cocafactory.h"
#endif
#if defined(HAVE_LINUX)
#include "linux/linuxfactory.h"
#endif
int ProcessesFactory::GetProcessFactory()
{
static ProcessesFactory *processesFactory = 0;
if (!processesFactory)
{
#if defined(HAVE_WIN32)
processesFactory = WindwosFactory::GetFactoryInstance();
#endif
#if defined(HAVE_MACOS)
processesFactory = CocoaFactory::GetFactoryInstance();
#endif
#if defined(HAVE_LINUX)
processesFactory = LinuxFactory::GetFactoryInstance();
#endif
}
return processesFactory;
}
};
上邊代碼是按條件編譯的,build系統保證同一時間只設置其中一個開關(如HAVE_WIN32)。通常會在Makefile裡做相關設定讓它作為編譯時一個編譯參數。
每個平台都提供一個可以創建並返回平台相關實現指針的類(比如WindowsFactory)。這個類被編譯到平台相關的庫裡並鏈接到應用程序。每個支持的平台都有一個這樣的庫。當平台無關的代碼獲得這個指針後,可以用它來創建提供平台相關功能的對象。
WindowsFactory實現了一個靜態函數GetFactoryInstance(),它創建並返回一個平台相關實現的單體
#pragma once
#if ! defined(_WINDOWS_FACTORY_H_)
#define _WINDOWS_Factory_H_
#include "processesfactory.h"
class WindowsFactory :public ProcessesFactory {
public:
static WindowsFactory * GetFactoryInstance() {
static WindowsFactory * factory = 0;
{
if (!factory)
factory = new WindowsFactory;
return factory;
}
}
virtual ~WindowsFactory();
virtual ProcessesImpl * MakeProcesses();
private:
WindowsFactory();
};
#endif
需要注意的是。首先,靜態函數GetFactoryInstance()允許我們創建並獲得windows-factory的單體,另一個關鍵是工廠模式實現了一個MakeProcesses()的函數,返回了一個指向我們需要的ProcessesImpl對象的指針。一個工廠模式可以創建各種各樣的對象,每個對象都提供針對平台的某個功能。假設我們寫獨立於平台的讀寫文件功能嗲嗎,首先創建一個新的抽象工廠類FilesFactory,然後修改WindowsFactory如下
#pragma once
#if ! defined(_WINDOWS_FACTORY_H_)
#define _WINDOWS_Factory_H_
#include "processesfactory.h"
#include "filefactory.h"
#include "processesimpl.h"
#include "filesimpl.h"
class WindowsFactory :public ProcessesFactory, public FilesFactory
{
public:
static WindowsFactory * GetFactoryInstance() {
static WindowsFactory * factory = 0;
{
if (!factory)
factory = new WindowsFactory;
return factory;
}
}
virtual ~WindowsFactory();
virtual ProcessesImpl * MakeProcesses();
virtual FileImpl * MakeFiles();
private:
WindowsFactory();
};
#endif
這是ProcessesImpl的定義
# pragma once # if ! defined(__PROCESSES_IMPL_H__) #define _ _PROCESSES_IMPL_H__ #include "processes.h" #includeclass ProcessesImpl { public: ProcessesImpl() {}; virtual ~ProcessesImpl() {}; virtual int Scan() = 0; int GetCount(); const char * GetName(const int which); protected: std::vector m_processList; }; #endif
這個類裡的實現大多數代碼都是可以用在所用的平台上。進程名和ID列表存放在STL移植性很高的vector裡,而GetCount()這樣的函數都只依賴於這個vector,所以也很自然的在基類裡實現。
另一方面,Scan()函數是平台相關的,所以必須在子類裡實現。
#if !defined(_WINDOWSPROCESSESIMPL_H__) #define _WINDOWSPROCESSESIMPL_H__ #include "../processesimpl.h" #include#include #include #include "psapi.h" class WindowsProcessesImpl :public ProcessesImpl { public: WindowsProcessesImpl(); virtual ~WindowsProcessesImpl(); virtual int Scan(); private: void ScanProcesses(); void PrintProcessNameAndID(DWORD processID); }; #endif
注意這裡包含了Windwos相關的頭文件,因為這段代碼只在Windows上編譯,所以包含它或其他平台相關的代碼都ok。Scan()函數只用到了兩個私有的幫助函數WindowsProcessImpl:ScanProcess()和PrintProcessNameAndID()。只要按基類的要求聲明了Scan()函數,其他的都可自行添加。
Linux下實現使用了proc文件系統來獲取進程信息。首先是頭文件:
#pragma once #if !defined(_LINUXPRROCESSIMPL_H__) #define _LINUXPRROCESSIMPL_H__ #include"../processimpl.h" #includeclass LinuxProcessesImpl :public ProcessesImpl { public : LinuxProcessesImpl(); virtual ~LinuxProcessesImpl(); virtual int Scan(); }; #endif
然後是具體實現
#include "linuxprocessesimpl.h" #include#include #include #include #include int LinuxProcesseSImpl::Scan() { DIR *dir; m_prorcessList.clear(); dir = opendir("/proc"); if (dir == NULL) return 0; std::string name; struct dirent *dirEnt; struct stat statBuf; while ((dirEnt == readdir(dir))) { name = "/proc/"; name += dirEnt->d_name; if (!stat(name.c_str(), &statBuf) { if (statBuf.st_mode & S_IFDIR) { char *p; p = dirEnt->d_name; bool allDigit = true; while (*p) { if (!isdigit(*p)) { allDigits = false; break; } p++; } if (allDigits) { Process proc; proc.SetPID(atoi(dirEnt->d_name)); std::string path = name + std::string("/cmdline"); int fd = open(path.c_str().O_RDONLY); if (fd != -1) { char buf[1024]; memset(buf, '\0', sizeof(buf)); int n; if ((n = read(fd, buf, sizeof(buf) - 1)) > 0) { proc.SetName(buf); m_porcessList.push_back(proc); } else if (n == 0) { path = name + std::string("/status"); int fd2 = open(path.c_str(), O_RDONLY); if (fd2 != -1) { memset(buf, '\0', sizeof(buf)); if (n = read(fd2, buf, sizeof(buf) - 1) > 0) { char *p = buf; while (*p) { if (*p == '\n') { *p = '\0'; break; } p++; } if ((p = strstr(buf, "Name:"))) { p += strlen("Name:"); while (*p && isspace(*p)) p++; } else p = buf; proc.SetName(p); m_processList.push_back(proc); close(fd2); } close(fd); } } } } } } closedir(dir); return m_processList.size(); }
最後,我們來看看使用BSD奇特的sysctl()函數來獲取進程信息的Darwin系統的實現方法。
#pragma once #if ! defined(_COCOAPROCESSESIMPL_H__) #define _COCOAPROCESSESIMPL_H__ #include"../processimpl.h" #include #include#include #include #include #include typedef struct kinfo_proc kinfo_proc; class CocoaProcessesImpl :public ProcessesImpl { public : CocoaProcessesImpl(); virtual ~CocoaProcessesImpl(); virtual int Scan(); private: int getBSDProcessList(kinfo_proc **procList,size_t * procCount); }; #endif
實現可以參考(http://developer.apple.com)
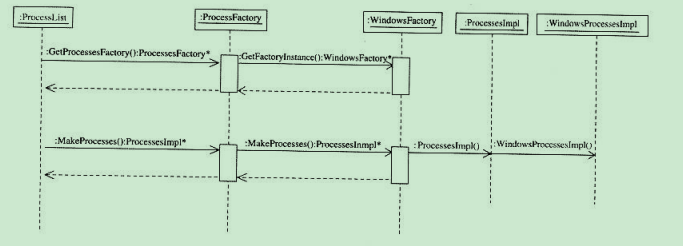
ProcessList構造函數獲取一個指向從ProcessesImpl繼承而來的類的指針。ProcessesImpl定義了Scan()、GetSize()、GetID()和GetName()的接口。當應用程序調用ProcessList::Scan()時,ProcessList會通過Scan()去調用相應平台的版本。而要得到這個指針,ProcessList先調用ProcessesFactory::GetProcessesFactory(),隨後它再次調用WindowsFactory::GetFactoryInstance()。因為ProcessesFactory::GetProcessesFactory()只是被部分編譯了而已
#pragma once
ProcessList::ProcessList() :m_processesImpl(NULL)
{
ProcessesFactory *factory = ProcessFactory::GetProcessesFactory();
if (factory)
m_processesImpl = factory->MakeProcesses();
}
ProcessFactory *ProcessesFactory::GetProcessesFactory() {
static ProcessesFactory * processesFactory = 0;
if (!processesFactory)
#if defined*(HAVE_WIN32)
processesFactory = WindowsFactory::GetFactoryInstance();
#endif
return processesFactory;
}
WindowsFactory::GetFactoryInstance會實例化ProcessesImpl的子類WindowsProcessesImpl,隨後指向這個對象的指針將會返回給ProcessList的構造函數。
scan的序列圖
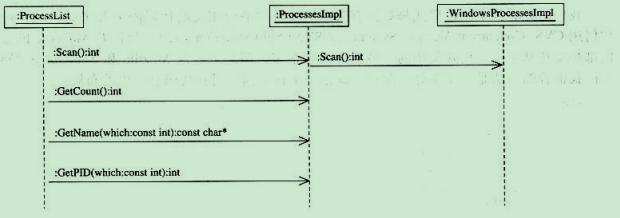
這裡ProcessList每個函數代碼都差不多,先檢查工廠對象返回的ProcessesImpl指針是不是為空,若是非空,則調用相應的函數
int ProcessList::Scan(){
if (m_processesImpl)
return m_processesImpl->Scan();
return -1;
}
int ProcessList::GetCount() {
if (m_processesImpl) {
return m_processesImpl->GetPID(i);
return -1;
}
const char*
ProcessList::GetName(const int i) {
if (m_processesImpl)
return m_processesImpl->GetName(i);
return NULL;
}
}
其中Scan()調用的WindowsProcessesImpl的實現