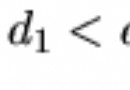第一章 c++簡介:
1.c語言是基於過程的,自上向下的編程語言
先分析大的解決方向,逐漸細化。
c++是面向對象的OOP,自下而上的編程語言
先設計類,然後將他們串聯起來
優點是:保護數據,代碼重用,可移植性強
2.c++的OOP與通用編程
都是強調代碼重用
不過OOP強調的是數據方面,而通用編程強調的是算法方面
3.OOP提供了高級抽象,C語言則提供了低級硬件訪問
4.C++融合了OOP 通用編程和傳統C的過程性方法。
5.程序可移植方面存在兩個障礙:
一個是:硬件障礙,有些程序直接控制固定的硬件設備則不能移植
二個是:語言障礙,不同系統的語言環境不一樣
6.程序創建流程: 編碼-》編譯-》鏈接-》執行
源代碼->通過編譯器->目標代碼->通過鏈接代碼(鏈接啟動代碼和庫代碼)->可執行代碼
7.在UNIX系統下,C程序實現代碼使用.c後綴名,而C++則使用.C(因為UNIX系統區分大小寫)
第二章 開始學習c++
1. c++ 對大小寫敏感
2. c++在輸出的末尾加上\n和endl都可以換行
第三章 數據類型
1. OOP的本質是設計並拓展自己的數據類型。設計自己的數據類型就是讓類型和數據匹配。
2. C++內置數據類型分兩種:基本類型和復合類型。基本類型分為整數和浮點數;復合類型包括
數組,字符串,指針和結構體。
3. 變量名命名規則:
1)只能使用字母字符,數字和下劃線
2)名稱的第一個字符不能為數字
3)名稱區分大小寫
4)不能使用c++的關鍵字
5)c++對於名稱的長度沒有限制(但是C99中只是保證前63個字符有意義)
4. c++的基本整型從小到大為:char、short、int和long 還有他們的又符合和無符號類型,一共8種
5. #include中定義了符號常量(INT_MAX,LONG_MAX,SHRT_MAX等)
6. 關鍵字sizeof 對類型名(如int等)使用時,應將名稱放到放到括號中,而對變量名使用時,可以不使用括號
7. short a = SHRT_MAX(32767); a+1 == -32768 (結果為true;因為越界)
unsigned short b = SHRT_MAX(32767); b+1 == 32768 (true,沒有越界,因為其最大值為65535)
b = 0; b-1 == 65536 (true;因為最小值為0,越界)
8. 在要使用cout輸出8位或者16位的整數時,可以先使用cout << hex;(則可在接下來的整數中顯示16進制)
cout << oct; (則可以在接下來的整數在輸出中使用8進制顯示)
9. cout.put(char);可以顯示一個單字符。如:cout.put('a');
10. '\b'是轉義字符,表示退格。'\a'表示振鈴;
11. c++特殊字符集使用 \u和\U來表示。用它們來實現通用字符名(表示一些特殊的字符)
12. 定義符號常量最好使用const而不是使用#define,因為const能指定類型,並且可以將作用域限定在
某個函數或者文件中,其三const還可以用於更復雜的類型
13. 計算機吧浮點數分成兩部分存儲,一部分是存儲值,另一部分存儲縮放比例
14. 浮點數float的表示方法有標准小數點表示法(1.23)和E表示法(2.53e+8)
15. E表示法不區分大小寫,指數必須為整數,指數可以是正數、負數或者省略。但是,數字中不能有空格(2.32 E5就是錯誤的)
16. c++的浮點類型有三種:float double和long double,是按照有效位和允許的指數的最小范圍來描述的
17. 浮點常量在默認情況下都為double類型,要使其為float,則需要手動在常量末尾加上f,比如1E7f則表示float類型,1E7則表示double
18. c++算術類型分為兩種:一種是整型,一種是浮點型
19. c++會自動進行類型轉換的有:
1)將一種算術類型轉化為另一種算術類型
2)表達式中包含不同的類型時
3)將參數傳給函數時
20. 轉換時因為精度降低導致的問題:
1)double轉float
2)浮點數轉化為整數
3)將較大的整數轉化為較小的整數
第四章 復合類型
1. 數組中的元素數目必須是整數常量或者(const值),也可以是常量表達式(8*sizeof(int))
2. c語言中的string類的相關函數操作放在cstring這個頭文件中。
3.友元函數
class girl;
class boy
{
public:
void disp(girl &);
};
void boy::disp(girl &x) //函數disp()為類boy的成員函數,也是類girl的友元函數
{
cout<<"girl's name is:"< }
class girl
{
private:
char *name;
int age;
friend boy; //聲明類boy是類girl的友元
};
4. 共用體的用途:
當數據項使用兩種或兩種以上類型的時候,可以節省空間。例如:假設管理一個商品目錄,商品的ID可能是數字,也可能是字符,
這個時候就可以使用union。
struct thing
{
char name[20];
int type;
union id
{
int id_num;
char id_ch[20];
}
}
4.使用new如果內存分配失敗,則會返回空指針,還可能引發bad_alloc異常
5.只能使用delete來釋放new分配的內存,而不能用來釋放指向變量的指針,對空指針使用delete是安全的
6.使用new構建動態數組的時候,int * psome = new int[10];其中psome是指向數組的第一個元素的地址。
使用new時帶上了[]創建數組,則在釋放時也應該加上[],delete [] psome;反之亦然。
7.如果使用new []為一個實體分配內存,則應該使用delete(沒有[])來釋放
8.位數組分配內存的通用格式是:type_name pointer = new type_name[num];
9.指針和數組名的區別是:
1)指針可以加減,而數組名不行,因為指針是變量,數組名是常量,
2)sizeof對數組名來說計算的是整個數組長度
10.數組: arr[3] <==> *(arr + 3);
11.在c++中,char數組名,char*,以及使用引號括起來的字符串常量都被解釋為 字符串的第一個字符的地址
12.使用在初始化字符數組時可以使用=為其直接賦值,
但是不是初始化的時候,則必須strcpy或者strncpy
13.c++有三種管理數據內存的方式:自動存儲,靜態存儲和動態存儲
1)函數內部定義的常規變量使用自動存儲空間
2)靜態存儲:函數外部定義的變量或者使用關鍵字:static
3)動態存儲:從內存池中使用new動態分配的方式
14.
第五章 關系表達式
1.逗號運算符 - 它的優先級是在所有操作符中最低的,如:
arrno = 17,240;
會被解釋為: (arrno=17),240; ==> arrno = 17;
arrno = (17,240); ==》 arrno = 240
***********************************組合字符串的好方法**********************************************************
std_string reg_line;
auto at_detail = m_plat_info->get_register()->get_reg_status();
for ( auto it = at_detail.begin() ; it != at_detail.end() ; it++ )
{
if ( reg_line.size() != 0 )
{
reg_line += "|";
}
reg_line += it->c_str();
}
第七章 函數
1.函數原型不需要提供變量名,有類型列表就夠了
2.數據名被解釋為其第一個元素的地址,除了數組聲明使用數組名來標記存儲位置 和 對數組使用sizeof計算的是整個數組的長度
3.當int * arr 和 int arr[]用於函數頭和聲明中的時候,他們的含義是一致的
4.const int *pt = NUM;表示不能通過*pt來修改NUM變量的值,但是可以通過直接修改NUM變量來改變值
5.const float g_earth = 1.1;
const float * pe = &g_earth;這種方法是可行的,g_earth和指針pe都不能修改值
const float g_earth = 1.1;
float * pe = &g_earth;這種方法是不可行的,因為指針可以修改其值,但是g_earth是的const是禁止的,顯得沖突了
結論: c++禁止將const的地址 賦值給非const的指針;如果非要這樣做-》可以使用const_cast強制轉換
6.盡量使用const,這樣可以避免無意間修改數據而導致的編譯錯誤,使用const可以處理const和非const實參
7.回調函數:回調函數是在編寫者不知道函數什麼時候會被調用的情況下編寫的,一般用於動態庫函數的接口使用。
8.內聯函數-》是為了提高程序運行速度的一個方式,在運行的時候直接替換代碼
9.如果使用宏執行了類似函數的功能,則應該考慮將他們轉換成內聯函數。
10.宏和內聯函數的區別:
用內聯取代宏:
1.內聯函數在運行時可調試,而宏定義不可以;
2.編譯器會對內聯函數的參數類型做安全檢查或自動類型轉換(同普通函數),而宏定義則不會;
3.內聯函數可以訪問類的成員變量,宏定義則不能;
4.在類中聲明同時定義的成員函數,自動轉化為內聯函數。
5.在內聯函數中如果有復雜操作將不被內聯。如:循環和遞歸調用。
6.參數的傳遞方式有:按值傳遞,按引用傳遞,按指針傳遞
7.返回引用時需要注意:
不能返回臨時的內存單元如:
const struct_test & foo()
{
struct_test stt;
return stt;
}
為了避免返回一個臨時變量,一般我們都返回一個 作為參數傳遞給函數的引用,因為這也他的作用域還不會消失
還有一種辦法就是使用new來為變量分配內存空間,並返回指向該內存空間的指針。只是這樣要記得釋放
8.不能返回零時變量的引用。
9.什麼時候應該使用引用,什麼時候應該使用指針,什麼時候應該按值傳遞
=》如果數據對象較小,如內置類型和小型的結構,則按值傳遞
=》如果對象是數組,則使用指針,這是唯一的選擇,並將指針聲明為指向const的指針
=》如果數據對象是較大的結構,則使用const指針或者const引用,以提高程序的效率,節省空間開支
=》如果數據對象是類,則使用const引用。類設計的語義常常要求使用引用。
10.對於帶參數列表的函數,必須從右向左添加默認值,也就是說如果要為某個參數設置默認值,則要麼將這個參數放在
最右邊,要麼為它有點的所有參數都設置默認值。
11.函數的默認參數
函數的默認參數只能從右向左,依次聲明,定義函數體的時候函數列表中不需要添加默認參數
12.函數重載
參數列表不同(參數順序,參數個數,參數類型不同)的同名函數可以構成函數重載
1)一般只是用於做相近的函數功能的時候使用。
2)當參數列表只是個數不同的時候,一般情況下可以使用默認參數,而不需要使用重載
3)const和非const的參數可以構成函數重載
int foo(const char* p); 與 int foo (char* p)可以構成
int foo(int)const; 與 int foo(int)也可以構成
第九章 內存模型和名稱空間
1.一般情況下,不要將函數的定義或變量聲明放在頭文件中。因為如果這個頭文件在被其他兩個文件中包含,
那麼這個函數就會被定義兩次。除非函數是內聯的,否則就會出錯(類的成員函數默認是內聯的)。
2.register int a;這種聲明方式為 寄存器變量,只要使用了register,就不能獲取a的地址,因為寄存器中是沒有地址的,
這個時候不論編譯器到底有沒有使用寄存器來存儲這個變量。 auto int a 《==》 int a;前後等價,都存儲於堆棧中。
使用register的好處是,他存儲的變量如果是被頻繁使用,則可以大大提高訪問速度。
3.如果在文件2中試圖定義和文件1中一樣的全局變量,那麼程序將會出錯。
正確的方法是:使用extern關鍵
如果是定義的static靜態全局變量和其他文件中的全局變量想通,那麼靜態變量將隱藏常規的外部變量
static定義的全局變量,作用域只在於他本文件之中,不能被引用到其他文件中。
4.mutable關鍵字是為了突破const的限制而設置的,變量將用於處於可變的狀態,即使是在一個const函數中
struct data
{
char ch[20];
mutable int a;
}
const data veep={"love", 1};
strcpy(veep.ch, "like");//error
veep.a = 10; //OK
5.布局new操作符和常規new操作符???
6.using聲明使一個名稱可用,而using編譯指令,也就是using namespace使整個命名空間的內容都可用
第十章 對象和類
1.當且僅當沒有定義任何的構造函數時,編譯器才會提供默認構造函數。而只要我們定義了構造函數後,
我們就必須為它提供默認構造函數,如果我們只是提供了非默認構造函數(如:stock(char* p)),
但沒有提供默認構造函數,則下面聲明:stock stock1;將出錯。
2.定義默認構造函數的方法有兩種:一是給已有的構造函數的所有參數都提供默認值(如:stock(char* p=“hello”)),
另一種則是通過重載來定義另外一個構造函數——沒有參數的構造函數(stock();)
由於只能有一個默認構造函數,所以不要同時采用這兩種方法。
3.隱式的調用構造函數時,不要使用括號,不要就成了一個返回對象的函數(stock stock1();)
4.析構函數沒有參數,所以不能實現重載
5.const stock stock1("hello");
stock1.fun(); 如果:fun()函數不是聲明為const參數,則程序不能通過,因為編譯器無法確定fun()裡面的代碼不會修改
stock1的值,在這兒因為fun函數沒有參數,所以只能這樣聲明(void stock::fun()const{ ... }const成員函數 )
6.只要類的定義不修改調用對象,則我們應將其聲明為const
7.如果一個函數的參數是const,如果函數要返回這個參數,則返回值也必須是const
8.要創建對象數組,則這個類必須有默認構造函數,因為對象數組的初始化是先使用默認構造函數來創建數組元素
9.c++類中定義常量的方式有兩種:一是使用枚舉,這樣相當於宏;二是使用static關鍵字,在聲明的地方直接可以初始化
如:static const int a=30;
10.bool在大多數平台只占用一個字節,而BOOL占用4個字節
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
第十一章 使用類
1.操作符重載的規則:
1)重載後的操作符至少有一個操作數是用戶定義的類型,這是為了防止用戶為標准類型重載操作符,例如不能將-重載為兩個double的+
2)操作符不能違反原來的句法原則,例如不能將%重載為只是使用一個操作數(原本為兩個)
3)不能修改操作符的優先級,操作符重載後將保持原來的優先級
4)不能定義新的操作符,例如不能使用operator @()來表示求冪;
5)sizeof . .* :: ?: typeid 以及4個強制轉化符 不能被重載
2.如果一個函數為類的友元函數,那麼就賦予了該函數和類一樣的訪問權限。
3.為什麼需要非成員重載操作符函數?
因為:如果是類的成員操作符函數,那麼在對於重載二元操作符函數來說:第一個參數已經默認為this指針了,第二個參數才是我們自己定義的另外一個參數;
這時候當我們使用重載操作符的時候只能是 this->operator+(type);
例如: Time operator * (double m); 我們在使用的時候,只能使用 Time tm = Time*2.5;而不能使用成Time tm = 2.5*Time;
這時候我們使用非成員重載操作符則可以自己定義參數列表順序,Time operator *(double m, const Time& t);這樣就可以使用上述方法調用了;
=》但是這兒出現了另外一個問題,就是非成員函數不能訪問類的私有變量,這樣就不能實現操作符重載;這個時候就需要把函數聲明為友元函數就解決了;
=》最好的例子: friend void operator<< (ostream & os, const Time& t);第一個參數必須是cout;
4.類的友元函數需要在類中聲明前加上關鍵字friend;友元函數不是類的成員函數,所以不能用成員操作符來調用。(定義中不需要friend關鍵字了)
5.只有類聲明中可以決定哪一個函數為友元函數,因此類聲明依然控制了哪些函數可以訪問私有數據,這樣不會破壞OOP原則。
6.ostream & operator << (ostream& os, const Time& t)
{
os << t.hours << " " << t.minutes;
return os;
}
返回ostream的引用是為了,能在函數外部能正常使用cout ; cout << Time << " ";
7.C operator+(const B & b)const; 和 friend C operator+(const C& c, const B& b);不能同時存在,參數列表相同,調用時會產生二義性
應當C operator+(const B & b)const;與 friend C operator+(const B& b, const C& c);這樣參數順序不一致即可
8."-" 操作符 在c++中可以表示一元的負數,或者二元的減號;這時候重載"-"的時候,可以重載為一元或二元都可以
9.當構造函數只接受一個參數的時候,在初始化類對象的時候可以直接用等號進行初始化: Time time = 8; Time::Time(int day);
這種等價於 Time time(8); 或者 Time time = Time(8);
10.可以為類定義類型轉化函數:
Time::operator int()const
{
return hour;
}
注意這裡不能有返回值,不能有參數。因為已經確定了返回類型為int,而參數為類對象本身。
這個時候就可以使用 int hour = int(Time(342));這樣的類型轉換了
11.如果一個類裡面定義兩種類型轉化函數 (int 和 double),這個時候我們如果要進行long的類型轉化,這時候會出現二義性
12.應當謹慎的使用隱式轉換,因為這樣往往對導致很多麻煩。
13.可以聲明一個全局的對象,這樣可以在main函數之前,通過全局對象的構造函數來做一些事情。常見於MFC的theApp對象技術。
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
第十二章 類的動態內存分配
1.使用動態內存分配最主要的目的是:有時候不知道分配多少內存合適,如果使用數組預估一個值分配,則有可能會過大;但是過小又不能存儲
這個時候就可以在構造函數中,先對傳遞進來的參數進行內存占用計算,然後在分配相應大小的內存,這樣就不會浪費空間了。
(new將在運行時確定分配空間的大小,而數組是在編譯時確定分配內存的大小。)
2.類的成員不能在聲明的地方進行初始化:因為聲明的時候只是指定了成員變量的格式和使用方法,但是沒有為其分配內存空間。
3.靜態類成員如果加上了const,則可以在聲明中進行初始化。
4.新建一個對象,並將其初始化為同類現有對象的時候,將調用拷貝構造函數。
每當程序生產了對象副本時,編譯器都將使用復制構造函數。
如:
Time tm(0);//
Time t = Time(tm);
Time t(tm);
Time t = tm;
Time * t = new Time(tm);
5.成員復制也稱為淺復制,默認的拷貝構造只是復制成員的值,而不會拷貝內存.
6.在一個類的成員函數裡面,可以訪問該類另一個對象的私有成員. 例如Time(const Time & tm);
在這個拷貝構造函數中,可以直接使用tm的私有成員hour。
7.復制操作符 Time & operator=(const Time& tm); 這兒返回Time&是為了連續賦值(tm2=tm1=tm;)
相當於:tm2.operator=(tm1.operator=(tm));
8.賦值操作符只能使用成員函數重載
9.如果一個類有多個構造函數,其中每個構造函數new出內存空間的方式都應該一致,
要麼都是用new 要麼都是用new[],因為只有一個析構函數,只能有一種方式釋放
10.類的轉換函數:
1)將其他類型轉換為類,可以使用類的構造函數;Time(type_name _value);的方式
2)將類轉換為其他類型,則需要使用類成員函數:operator type_name();來實現,
其中type_name則是要轉換成的類型,函數沒有聲明返回類型,但是必須返回對應類型的值。
11.const int num; num是const類型的成員變量,必須在執行到構造函數之前(即創建對象時)對其進行初始化,
這時候就需要使用初始化列表。當然初始化列表不只是可以初始化const修飾的成員變量,適用於所有的變量初始化。
注:聲明為引用的初始化成員變量,也必須使用初始化列表對其進行初始化。
注:如果是類對象的成員變量,使用初始化列表的效率更高。
注:數據成員被初始化的順序與初始化列表中的排列順序無關,和他們聲明的順序想同。
12.類成員初始化的方法也可以用於普通常量的初始化中,如:int a=1; <=> int a(1);
13.如果想你的對象不能被復制或者調用默認構造函數可以這樣:
Time (int hour){}
Time & operator=(const Time tm){ return *this;}
把這兩個函數定位為private:這樣就不能通過復制和初始化的方法使用這個對象了。
14. 12.2隊列例子理解清楚????? 440頁
第十三章 類繼承
1.如果父類沒有默認的構造函數,則子類在繼承父類後,子類的構造函數必須完成對父類的構造。
如: A(char *p){}; class B :public A{}; 則B(char* p): A(p){};
否則將調用父類的默認構造函數,如果父類沒有定義默認構造函數,則會出錯。
2.派生類構造函數注意要點:
1)基類對象首先被創建
2)派生類構造函數應通過成員初始化列表將基類信息傳遞給基類構造函數
3)派生類構造函數應該初始化派生類新添加的數據成員。
3.派生類要添加的東西:
1)新的構造函數
2)額外的數據成員和成員函數
4.如果基類的構造函數有參數,則派生類的構造函數必須先初始化基類的構造函數,否則會調用基類的默認構造函數。
5.除虛擬基類外,類的初始化列表只能將值傳遞給相鄰的基類,後者也可以使用相同的機制將信息再傳遞給他的基類
如果沒有在成員初始化列表提供基類的構造函數,則程序使用默認的基類無參構造函數。
成員初始化列表只能出現在構造函數中,主要用於初始化基類和const成員。
6.繼承只能是is-a,而不能是is-like-a,is-kind-a,uses-a的關系
7.基類聲明為虛析構函數,是為了確保對象在釋放的時候,先釋放派生類,再釋放基類。如果不是虛擬析構,則只會調用基類析構
8.如果要在派生類中重新定義基類的方法,通常應該將基類方法聲明為虛擬的,這樣程序能根據對象類型來選擇方法版本,
同時這時候為基類聲明為虛擬析構函數也是一種慣例。
9.靜態聯編:在編譯過程中聯編的(宏,內聯),編譯器對非虛擬方法使用靜態聯編。(效率高)
動態聯編:在運行時中聯編的(多態)()
10.將派生類引用或指針轉換為基類引用或指被稱為向上強制轉換,這使得公有繼承不需要進行顯示類型轉換。
向上強制轉換是可傳遞的,比如A派生出B,B派生出C,則A的指針和引用可以引用A、B、C對象。
11.虛函數工作原理:
編譯器為每個有虛函數的對象添加一個隱藏成員(一個保存了指向函數地址數組的指針,這個數組稱為虛函數表),
如果派生類提供了某個虛函數的新定義,則虛函數表將保存新函數的地址,在使用時則根據指針去尋找對應的函數地址
12.虛函數疑點:
(1)內聯函數不能聲明為虛函數
所謂內聯就是告訴編譯器將代碼嵌入到調用者的代碼中,以增加執行碼長度來換取執行的速度,而虛函數是執行器動態轉換的,則編譯器不知道要替換哪部分代碼進去,故不能內聯
(2)靜態成員函數不能聲明為虛函數
而類的普通成員函數(包括虛函數)在編譯時加入this指針,通過這種方式可以與對象捆綁,而靜態函數編譯時不加this,因為靜態函數是給所有類對象公用的,所以沒有在編譯時加this,所以無法與對象捆綁,而虛函數就是靠著與對象捆綁加上虛函數列表才實現了動態捆綁。所以沒有this指針虛函數無從談起。
(3)構造函數不能聲明為虛函數的原因是:
構造一個對象的時候,必須知道對象的實際類型,而虛函數行為是在運行期間確定實際類型的。而在構造一個對象時,由於對象還未構造成功。編譯器無法知道對象 的實際類型,是該類本身,還是該類的一個派生類,或是更深層次的派生類。無法確定。。。
虛函數的執行依賴於虛函數表。而虛函數表在構造函數中進行初始化工作,即初始化vptr,讓他指向正確的虛函數表。而在構造對象期間,虛函數表還沒有被初始化,將無法進行。
(4)析構函數設為虛函數的作用:
在類的繼承中,如果有基類指針指向派生類,那麼用基類指針delete時,如果不定義成虛函數,派生類中派生的那部分無法析構。
(5)友元函數不能為虛函數:
友元不是類成員,只有類成員才能是虛函數。
13.如果在基類中定義了虛函數 virtual foo(){};而派生類中定義了 virtual foo(int a){};這個時候派生類不會出現兩個函數重載的版本,而是隱藏了基類版本,只是保留派生類中的版本。(重新定義基類的方法並不是重載,而是隱藏同名的基類方法)
(所以如果重新定義了基類方法,則應確保和原來的參數列表一致,包括返回值)
14.如果基類重載了某個函數的多種方法,則應該在派生類中實現所有的重載版本。因為如果派生類如果只定義了一個版本,
則會把基類重載的其他版本全部隱藏而導致不能使用。(如果其他重載版本不需要修改,可以在實現中調用基類版本即可)
15.對於類外部來說,保護成員和私有成員相似,而對於派生類來說,保護成員和共有成員相似。
16.單例模式:
class TheOne
{
public:
static TheOne* GetOneInstance();
protected:
TheOne(){ }
};
TheOne* TheOne::GetOneInstance()
{
static TheOne onlyOne;
return &onlyOne;
}
解析:GetOneInstance()方法僅在第一次被調用時,會創建TheOne類的一個實例,用這種方式構造的靜態對象一直有效,知道程序終止。
因為靜態變量在函數調用結束後仍保存在內存中,所有後面再調用GetOneInstance()時,將返回同一個靜態對象的地址。
17.對於派生類中有使用new申請變量的構造函數時,必須為基類也要調用派生類的引用。hasClass(const hasClass& cls):baseClass(cls){ ... }
18.對於使用了new的派生類,賦值操作符使用方法:hasClass& operator=(const hasClass & cls){... baseClass::operator=(cls); ...}
19.當基類和派生類均使用了動態內存分配的時候,派生類的析構函數,賦值操作符和拷貝構造函數都需要使用相應的基類方法來處理基類元素。如上17和18條。
20.函數返回對象和返回對象的引用,最主要的目的是返回引用可以方便減少內存的操作,不能返回臨時變量的引用。
21.void myCls::show()const{} 這兒的const可以確保方法不修改調用它的對象。
22.基類的構造函數和析構函數都不能被繼承,賦值操作符也不能被繼承=》因為基類和派生類的賦值的時候參數不一樣(特征標不一樣)
23.派生類的友元函數可以通過強制類型轉換dynamic_cast,將派生類的引用或指針轉化成基類的引用或指針,
然後就可以通過這種方式訪問基類的友元函數等了。
第十四章:c++中的代碼重用
1.如果一個成員類沒有在構造函數的初始化列表中構造,那麼c++將調用這個類的默認構造函數進行構造;而這樣就不能傳遞參數了。
2.如果一個類的初始化列表包含多個項目時,這些項目的初始化順序是按照他們的聲明順序來初始化的,而不是初始化列表中的順序。
3.如果私有繼承的時候想使用基類的方法,則可以使用作用域限定符::後面跟方法名來使用相應的方法。(500頁)
如果是共有繼承則可以使用對象調用相應的方法《=》私有繼承使用父類名加上作用域限定符來調用相應的方法。
如果要使用基類對象本身,則使用強制類型轉換。(const string& ) *this;
4.私有繼承的好處:私有繼承下 基類的保護成員 在派生類中可以直接使用,而如果是把類作為類的成員變量,則保護成員不可訪問
通常情況下,我們使用包含來建立has-a關系,但是如果新類需要訪問原有類的保護成員,則應該使用私有繼承
5.要想在使用私有繼承的派生類中使用基類的私有方法,可以使用using;比如using string::size;
這樣就可以把size()函數作為共有方法一樣使用啦
6.虛繼承:當B、C繼承自A,而D同時繼承自B、C時,這時候會出現菱形繼承關系,D同時會擁有兩份A基類數據的拷貝,訪問時將會出錯;
為避免這種情況發生,則在B、C繼承A的時候 使用virtual關鍵字來實現虛繼承。class B :virtual public A {};
1)在使用虛繼承進行構造D類的時候,會在D的初始化列表中同時調用A、B、C的構造函數,如:
D(int d, int b, int c, int a):B(b,a),C(c,a),A(a){ m_d = d};
注意:非虛繼承的情況下,D不能直接調用A的構造函數,而虛繼承的情況下,A如果不希望調用默認構造函數,則必須這樣做。
2)如果D同時繼承B、C都存在的foo()函數時,D在使用foo()函數的時候會存在二義性,這時候需要使用作用域限定符,D.B::foo();
7.在基類和派生類中定義了相同的函數名時,派生類的定義優先於基類的定義。
8.虛擬二義性規則與訪問規則無關,也就是說,C繼承自A,B,而A、B都有foo()函數,不管foo在AB中是私有還是共有,在C中調用foo的時候都會出現二義性。
要避免出現二義性,則需要使用基類的類限定符,A::foo()、B::foo();同名成員變量亦如此。
9.類模板
類模板的特性:可以為類型參數提供默認值: template 這樣如果在使用時省略T2,則使用默認類型
注意:不能為函數模板提供默認值。
10.疑問:類模板和函數模板的具體化?!!
第十五章 友元、異常和其他
1.友元類的所有方法都可以訪問原始類的私有成員和保護成員。
2.友元類的聲明friend class B;可以放在在共有、私有和保護部分
3.對類的嵌套通常是為了實現另外一個類,並且避免名稱沖突。
4.異常類型通常定義為一個類:
class Bad_error
{
public:
Bad_error(char* p):str(p){}
void err_info(){cout << "err=" << str << endl;}
private:
string str;
};
在使用的時候:
void foo(int a) throw(Bad_error) //如果throw後面的括號為空就表示該函數不會拋出異常
{
if(a==0)
throw Bad_error("參數為0");
else
return a++;
}
6.異常捕獲中,catch塊的排列順序應該與派生順序相反,不然它將可能捕獲不了所有的異常。
當你不知道異常類型的時候,可以使用省略號來表示異常類型,這樣可以捕獲任何異常。
當你知道這部分程序可能會出現一部分異常的時候,可以先在catch後面列出這些異常,然後在最後使用"..."來捕獲其他所有。
在catch中使用基類對象時,將捕獲所有子對象。
7.c++中定義了 exception異常類,我們可以把我們的異常類自他繼承下來,
8.如果程序拋出了異常,但是我們沒有捕獲,那麼程序將會調用MyQuit()退出程序。
9.RTTI 運行階段類型識別:
=>c++有3個支持RTTI的元素
1)dynamic_case操作符:它可以安全的將對象的地址貴指定類的指針。可以將派生類轉化為基類。轉化成功,返回對象地址,轉化失敗返回空指針
2)typeid操作符返回一個type_info對象,可以對兩個typeid的返回值進行比較。比如 typeid(string) == typeid(int);typeid操作符返回一個對type_info對象的引用。
3)type_info結構存儲了有關特定類型的信息。
10.4種類型轉化操作符
=》dynamic_cast(動態轉換),可以將類進行類型轉換,只有當轉換為自己的基類類型時,才會成功。用途:確保安全的調用虛函數。
=》const_cast (const轉換),用於改變值為 const和volatile的類型,類型的其他地方必須一致,如果不一致將會出錯,一般用於取消const關鍵字
High bar; const High *pbar = &bar; High *pb = const_cast(pbar);正確(用於大多數時候是常量,但有時候是可以修改的值)
=》static_cast(靜態轉換),可以將兩個有關系的類互相轉化,比如基類轉換為派生類,或者派生類轉換為基類。
只要一個類型可以從一個方向轉換到另外一個類型,比如枚舉可以轉換為整數,那麼使用這種類型轉換則可以從整數轉化到枚舉。
=》reinterpret_cast,用於天生危險的類型轉換
第十六章: string類和標准模板庫
1.auto_ptr類 ---》用於管理動態內存分配的用法
2.只能對new分配出來的內存使用auto_ptr,而不要new[]分配的或通過自動變量聲明的內存來使用它
3.基類成員一般都為抽象類,具體類一般處於繼承關系的最後一級。