和分治思想的第一次相遇
當問題的規模是可以劃分的時候,分治的算法往往是很有效的:
不斷分割問題的規模,直到子問題的規模足夠小便直接求解,之後不斷整合子問題的解得到更大規模的解,最後得到完全解。
歸並排序就是分治算法的一個簡單的例子。
可能有人覺得快速排序也是屬於分治算法,但我不這麼覺得,因為快速排序是先得到大問題的解的一部分,再靠子問題來完成解,
並沒有整合子問題這一步,所以硬要說的話,快速排序應該是
“治分”算法。
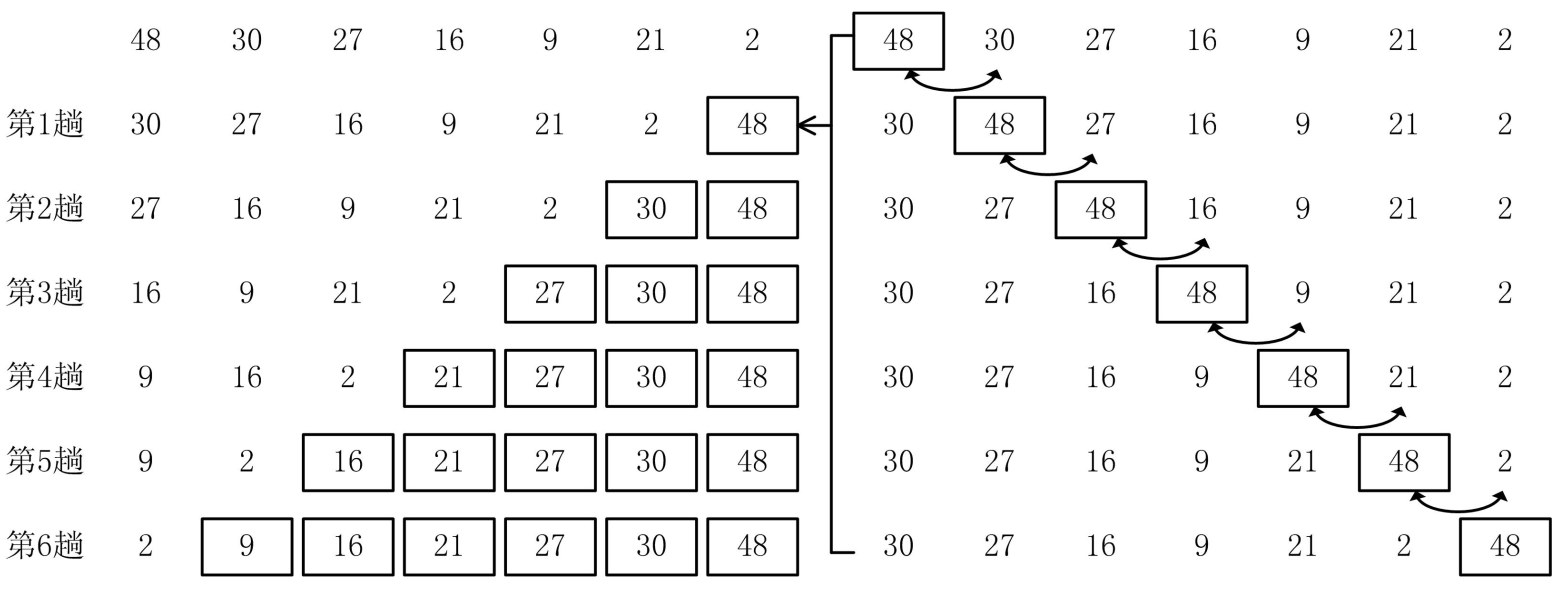
簡單圖示(是不是有點太簡單了)

如何分解?
歸並排序把問題劃為均勻的兩個子問題,即左半區間和右半區間,於是得到遞歸函數:
#define MID(i) (i >> 1) /// i / 2
/*****************************************
函數:歸並排序
說明:對區間[low, high)范圍的數據排序
*****************************************/
void mergeSort(int* low, int* high)
{
int range = high - low; ///區間元素個數
if(range > 1) ///對於規模為1的子問題本身已經是解了,所以只處理規模大於1的子問題
{
int* mid = MID(range) + low; ///求出分割點
///遞歸求解子問題
mergeSort(low, mid);
mergeSort(mid, high);
merge(low, mid, high); ///再合並兩個子問題,這個函數待會實現
}
}這裡是不能應用尾遞歸優化的,因為節點信息需要保存,以便執行merge(合並)過程。
讀者可以思考下對於規模為2的問題為什麼不會出現無限遞歸。
怎麼合並?
在合並兩個子問題時我們知道子問題對應的區間已經是有序的。所以我們可以通過比較兩區間當前的最小值,得到整個區間的最小值,不斷選出最小值便可完成合並(類似選擇排序)
整個過程的花費是線性的O(n),n為兩區間元素個數和。
不過整個過程需要一個輔助數組來存放不斷選出的最小值(總不能占別的元素的位置吧),所以為了效率,首先聲明足夠大的輔助數組:
#define MID(i) (i >> 1) /// i / 2
int* helper; ///輔助數組
/**********************************************
函數:歸並函數
說明:合並有序區間[low, mid)和[mid, high)
left為左區間的遍歷指針
right為右區間的遍歷指針
helper為局部變量覆蓋全局聲明
這樣做是為了減少代碼行數
時間復雜度:O(high - low)
**********************************************/
void merge(int* low, int* mid, int* high, int* left, int* right, int* helper)
{
while(true)
{
if(*left <= *right) ///相等時下標小的優先,使得算法穩定
{
*(helper++) = *(left++);
if(left >= mid) ///左區間已經空了
{
while(right < high) *(helper++) = *(right++); ///把右區間剩下的復制過去
break; ///跳出循環(外層)
}
}
else
{
*(helper++) = *(right++);
if(right >= high) ///右區間空了
{
while(left < mid) *(helper++) = *(left++); ///把左區間剩下的復制過去
break; ///跳出外層循環
}
}
}
while(high > low) *(--high) = *(--helper); ///再復制回來
}
/*****************************************
函數:歸並排序
說明:對區間[low, high)范圍的數據排序
時間復雜度:O(nlgn)
*****************************************/
void mergeSortRoutine(int* low, int* high)
{
int range = high - low; ///區間元素個數
if(range > 1) ///對於規模為1的子問題本身已經是解了,所以只處理規模大於1的子問題
{
int* mid = MID(range) + low; ///求出分割點
///遞歸求解子問題
mergeSortRoutine(low, mid);
mergeSortRoutine(mid, high);
merge(low, mid, high, low, mid, helper); ///再合並兩個子問題
}
}
/****************************************
函數:歸並排序“外殼”
****************************************/
void mergeSort(int* low, int* high)
{
helper = new int[high - low]; ///輔助數組最多也就存輸入的元素數
if(helper != nullptr)
{
mergeSortRoutine(low, high);
delete[] helper; ///釋放內存
}
else return; ///空間不足,沒法啟動歸並排序
}
時間復雜度
上面的歸並排序的時間復雜度是很好分析的,最多有lgn層問題,每層均花費O(n)所以是O(nlgn),並且最壞和最好情況都是差不多的。
優化
關於歸並排序的優化還是挺多的,這裡先來講一種很不錯的優化:
在原始的歸並函數中左右區間的元素都會按大小全部復制到輔助數組中去,之後再一一復制回來。這一過程沒錯不過卻沒有考慮那些原本就處於正確位置的元素。
比如當左區間空了的時候,此刻右區間剩下的元素還需要再復制到復制數組中嗎?答案是不需要的,因為它們本來就已經在正確位置了:
/**********************************************
函數:優化版歸並函數
說明:合並有序區間[low, mid)和[mid, high)
left為左區間的遍歷指針
right為右區間的遍歷指針
helper為局部變量覆蓋全局聲明
這樣做是為了減少代碼行數
時間復雜度:O(high - low)
**********************************************/
void merge(int* low, int* mid, int* high, int* left, int* right, int* helper)
{
while(true)
{
if(*left <= *right) ///相等時下標小的優先,使得算法穩定
{
*(helper++) = *(left++);
if(left >= mid) break; ///左區間掃描完直接跳出外層循環,此時右區間剩下來的元素本來就處於正確位置
}
else
{
*(helper++) = *(right++);
if(right >= high) ///右區間空了
{
while(left < mid) *(helper++) = *(left++); ///把左區間剩下的復制過去
break; ///跳出外層循環
}
}
}
while(right > low) *(--right) = *(--helper); ///再復制回來,不過要跳過右區間剩下的元素
}這樣不僅使代碼更加簡短,並且在很多時候會使程序加速。
同理可以應用於左區間原本就處於正確位置的元素,最終得到:
/**********************************************
函數:優化版歸並函數
說明:合並有序區間[low, mid)和[mid, high)
right為右區間的遍歷指針
helper為局部變量覆蓋全局聲明
這樣做是為了減少代碼行數
時間復雜度:O(high - low)
**********************************************/
void merge(int* low, int* mid, int* high, int* right, int* helper)
{
///收縮左邊界,不再考慮左區間原本位於正確位置的元素
while(*low <= *right)
if(++low >= mid) return; ///如果左區間的元素全部在正確位置,那麼右區間也是如此,直接返回
int* left = low; ///設置左區間遍歷指針
*(helper++) = *(right++); ///別浪費上面循環失敗的比較結果。。。
if(right >= high) ///右區間空了
while(left < mid) *(helper++) = *(left++); ///把左區間剩下的復制過去
else while(true)
{
if(*left <= *right) ///相等時下標小的優先,使得算法穩定
{
*(helper++) = *(left++);
if(left >= mid) break; ///左區間掃描完直接跳出外層循環,此時右區間剩下來的元素本來就處於正確位置
}
else
{
*(helper++) = *(right++);
if(right >= high) ///右區間空了
{
while(left < mid) *(helper++) = *(left++); ///把左區間剩下的復制過去
break; ///跳出外層循環
}
}
}
while(right > low) *(--right) = *(--helper); ///再復制回來,不過要跳過右區間剩下的元素
}
雖然在最壞情況下和原始的歸並函數一樣,但是大部分情況還是有優化的,特別是當數組原本有序時,每層只需簡單遍歷O(n/2)個元素,比快速排序更高效。
減少的“倒騰”次數的期望
即下面cnt的平均值:
int cnt = 0; ///計數器
void merge(int* low, int* mid, int* high, int* right, int* helper)
{
while(*low <= *right)
{
cnt++; ///左邊多一個元素不用參與復制
if(++low >= mid)
{
cnt += high - right; ///右邊都不用參加
return;
}
}
int* left = low;
*(helper++) = *(right++);
if(right >= high)
while(left < mid) *(helper++) = *(left++);
else while(true)
{
if(*left <= *right)
{
*(helper++) = *(left++);
if(left >= mid)
{
cnt += high - right; ///右邊不用參加復制的元素個數
break;
}
}
else
{
*(helper++) = *(right++);
if(right >= high)
{
while(left < mid) *(helper++) = *(left++);
break;
}
}
}
while(right > low) *(--right) = *(--helper); ///再復制回來,不過要跳過右區間剩下的元素
}
當左右區間元素個數均為 k/2時,左區間不用參與復制的元素個數為 i 的條件為前 i 小的元素都被分在了左邊,並且第 i + 1大元素被分在了右邊,但第k/2大元素要單獨考慮。
右邊不用參與復制的元素個數和左區間是一樣的,因為是對稱的。於是得到下面的級數:

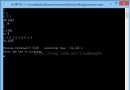
下面是我的測試數據(元素互異且隨機排列):

可以看出這項優化平均減少O(n)次多余的操作。
使葉子“變粗”
同樣歸並排序也可以用插入排序來優化,同樣也是因為對於小規模的數據插入排序常數小的緣故。並且由於引進插入排序我們知道葉子寬度一定大於1,因此可以簡化歸並函數:
#define FACTOR 10 ///葉子寬度
#define MID(i) (i >> 1) /// i / 2
int* helper; ///輔助數組
/**********************************************
函數:優化版歸並函數
說明:合並有序區間[low, mid)和[mid, high)
right為右區間的遍歷指針
helper為局部變量覆蓋全局聲明
這樣做是為了減少代碼行數
時間復雜度:O(high - low)
**********************************************/
void merge(int* low, int* mid, int* high, int* right, int* helper)
{
///收縮左邊界,不再考慮左區間原本位於正確位置的元素
while(*low <= *right)
{
if(++low >= mid)
return; ///如果左區間的元素全部在正確位置,那麼右區間也是如此,直接返回
}
int* left = low; ///設置左區間遍歷指針
*(helper++) = *(right++); ///別浪費上面循環失敗的比較結果。。。
///因為葉子大於1,所以之前那兩句就不用了。
while(true)
{
if(*left <= *right) ///相等時下標小的優先,使得算法穩定
{
*(helper++) = *(left++);
if(left >= mid) break; ///左區間掃描完直接跳出外層循環,此時右區間剩下來的元素本來就處於正確位置
}
else
{
*(helper++) = *(right++);
if(right >= high) ///右區間空了
{
while(left < mid) *(helper++) = *(left++); ///把左區間剩下的復制過去
break; ///跳出外層循環
}
}
}
while(right > low) *(--right) = *(--helper); ///再復制回來,不過要跳過右區間剩下的元素
}
/*************************************
函數:優化版插入排序
說明:對區間[low, high)的數據排序
時間復雜度:O(n + inverse)
*************************************/
static void improvedInsertionSort(int* low , int* high)
{
for(int* cur = low; ++cur < high; ) ///實際是從第二個元素開始插入,因為第一個已經有序了
{
int tmp = *cur; ///臨時保存要插入的值
int* destPos = cur; ///記錄當前要插入的元素的正確安放位置,這裡初始化為本來的位置
///把第一次測試單獨提出來
if(*(--destPos) > tmp)
{
do
{
*(destPos + 1) = *destPos;
}while(--destPos >= low && *destPos > tmp); ///測試上一個是否是目標位置
*(destPos + 1) = tmp; ///最後一次測試失敗使得destIndex比實際小1
}
}
}
/*****************************************
函數:歸並排序
說明:對區間[low, high)范圍的數據排序
時間復雜度:O(nlgn)
*****************************************/
void mergeSortRoutine(int* low, int* high)
{
int range = high - low; ///區間元素個數
if(range > FACTOR) ///對於規模為1的子問題本身已經是解了,所以只處理規模大於1的子問題
{
int* mid = MID(range) + low; ///求出分割點
///遞歸求解子問題
mergeSortRoutine(low, mid);
mergeSortRoutine(mid, high);
merge(low, mid, high, mid, helper); ///再合並兩個子問題
}
else improvedInsertionSort(low, high);
}
/****************************************
函數:歸並排序“外殼”
****************************************/
void mergeSort(int* low, int* high)
{
helper = new int[high - low]; ///輔助數組最多也就存輸入的元素數
if(helper != nullptr)
{
mergeSortRoutine(low, high);
delete[] helper; ///釋放內存
}
else return; ///空間不足,沒法啟動歸並排序
}
自底向上的歸並排序
上面遞歸版的歸並排序的分解步驟是通過劃分父問題才得到子問題,但其實子問題是可以被我們直接找到的,因為一個子問題的標識是一個區間,而區間是由左右端點的數字確定的。
所以我們可以直接計算出我們目前想得到的子問題的區間:
#define MID(i) (i >> 1) /// i / 2
#define NEXT_GAP(i) (i <<= 1) ///下一個步長
int* helper; ///輔助數組
/**********************************************
函數:優化版歸並函數
說明:合並有序區間[low, mid)和[mid, high)
right為右區間的遍歷指針
helper為局部變量覆蓋全局聲明
這樣做是為了減少代碼行數
時間復雜度:O(high - low)
**********************************************/
void merge(int* low, int* mid, int* high, int* right, int* helper)
{
///收縮左邊界,不再考慮左區間原本位於正確位置的元素
while(*low <= *right) if(++low >= mid) return; ///如果左區間的元素全部在正確位置,那麼右區間也是如此,直接返回
int* left = low; ///設置左區間遍歷指針
*(helper++) = *(right++); ///別浪費上面循環失敗的比較結果。。。
if(right >= high) ///右區間空了
while(left < mid) *(helper++) = *(left++); ///把左區間剩下的復制過去
else while(true)
{
if(*left <= *right) ///相等時下標小的優先,使得算法穩定
{
*(helper++) = *(left++);
if(left >= mid) break; ///左區間掃描完直接跳出外層循環,此時右區間剩下來的元素本來就處於正確位置
}
else
{
*(helper++) = *(right++);
if(right >= high) ///右區間空了
{
while(left < mid) *(helper++) = *(left++); ///把左區間剩下的復制過去
break; ///跳出外層循環
}
}
}
while(right > low) *(--right) = *(--helper); ///再復制回來,不過要跳過右區間剩下的元素
}
/************************************************
函數:自底向上版歸並排序
說明:對區間[low, low + range)范圍的數據排序
時間復雜度:O(nlgn)
************************************************/
void mergeSortRoutine(int* low, int* high, int range)
{
for(int gap = 2; MID(gap) < range; NEXT_GAP(gap))
for(int* right = low + gap, * mid = low + MID(gap); mid < high; right += gap, mid += gap)
merge(right - gap, mid, right > high ? high : right, mid, helper);
}
/****************************************
函數:歸並排序“外殼”
****************************************/
void mergeSort(int* low, int* high)
{
helper = new int[high - low]; ///輔助數組最多也就存輸入的元素數
if(helper != nullptr)
{
mergeSortRoutine(low, high, high - low);
delete[] helper; ///釋放內存
}
else return; ///空間不足,沒法啟動歸並排序
}不過不知道為什麼在我電腦上遞歸版反而更快,真是奇怪。
後記
如果內容有誤或有什麼提議請在下面評論,謝謝。