Reduction操作:規約操作就是由多個數生成一個數,如求最大值、最小值、向量點積、求和等操作,都屬於這一類操作。
有大量數據的情況下,使用GPU進行任務並行與數據並行,可以收到可好的效果。
group同步:OpenCL只提供了工作組內的各線程之間的同步機制,並沒有提供所有線程的同步。提供組內item-work同步的方法:
void barrier (cl_mem_fence_flags flags)
參數說明:cl_mem_fence_flags 可以取CLK_LOCAL_MEM_FENCE、CLK_GLOBAL_MEM_FENCE
函數說明:(1)一個work-group中所有work-item遇到barrier方法,都要等待其他work-item也到達該語句,才能執行後面的程序;
(2)還可以組內的work-item對local or global memory的順序讀寫操作。
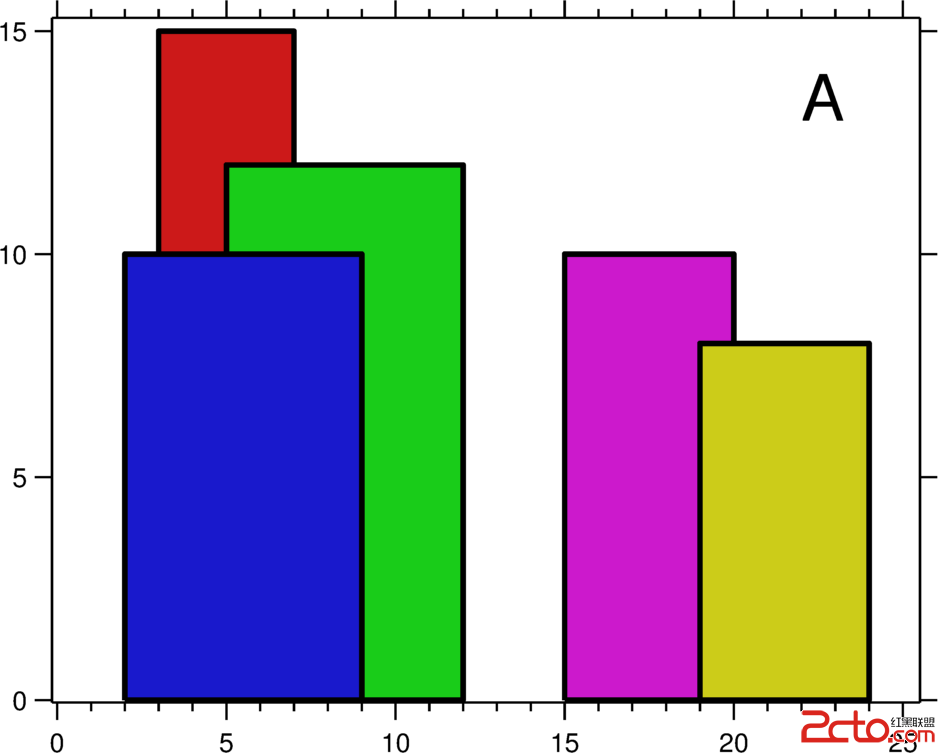
如下圖中每個大框表示任務並行、每個group線程;框中的計算是數據並行、每個item-work線程:

作為練習,給出個完整的使用OpenCL計算整數序列求和,在數據並行中使用Local Memory 加速,group組內並行同步使用CLK_LOCAL_MEM_FENCE。
程序實例(整數序列求和):
1.核函數(Own_Reduction_Kernels.cl):
__kernel
void
reduce(__global uint4* input, __global uint4* output, int NUM)
{
NUM = NUM / 4; //每四個數為一個整體uint4。
unsigned int tid = get_local_id(0);
unsigned int localSize = get_local_size(0);
unsigned int globalSize = get_global_size(0);
uint4 res=(uint4){0,0,0,0};
__local uint4 resArray[64];
unsigned int i = get_global_id(0);
while(i < NUM)
{
res+=input[i];
i+=globalSize;
}
resArray[tid]=res; //將每個work-item計算結果保存到對應__local memory中
barrier(CLK_LOCAL_MEM_FENCE);
// do reduction in shared mem
for(unsigned int s = localSize >> 1; s > 0; s >>= 1)
{
if(tid < s)
{
resArray[tid] += resArray[tid + s];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
// write result for this block to global mem
if(tid == 0)
output[get_group_id(0)] = resArray[0];
}
2.tool.h 、tool.cpp
見:http://www.cnblogs.com/xudong-bupt/p/3582780.html
3.Reduction.cpp
#include <CL/cl.h>
#include "tool.h"
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <string>
#include <fstream>
using namespace std;
int isVerify(int NUM,int groupNUM,int *res) //校驗結果
{
int sum1 = (NUM+1)*NUM/2;
int sum2 = 0;
for(int i = 0;i < groupNUM*4; i++)
sum2 += res[i];
if(sum1 == sum2)
return 0;
return -1;
}
void isStatusOK(cl_int status) //判斷狀態碼
{
if(status == CL_SUCCESS)
cout<<"RIGHT"<<endl;
else
cout<<"ERROR"<<endl;
}
int main(int argc, char* argv[])
{
cl_int status;
/**Step 1: Getting platforms and choose an available one(first).*/
cl_platform_id platform;
getPlatform(platform);
/**Step 2:Query the platform and choose the first GPU device if has one.*/
cl_device_id *devices=getCl_device_id(platform);
/**Step 3: Create context.*/
cl_context context = clCreateContext(NULL,1, devices,NULL,NULL,NULL);
/**Step 4: Creating command queue associate with the context.*/
cl_command_queue commandQueue = clCreateCommandQueue(context, devices[0], 0, NULL);
/**Step 5: Create program object */
const char *filename = "Own_Reduction_Kernels.cl";
string sourceStr;
status = convertToString(filename, sourceStr);
const char *source = sourceStr.c_str();
size_t sourceSize[] = {strlen(source)};
cl_program program = clCreateProgramWithSource(context, 1, &source, sourceSize, NULL);
/**Step 6: Build program. */
status=clBuildProgram(program, 1,devices,NULL,NULL,NULL);
/**Step 7: Initial input,output for the host and create memory objects for the kernel*/
int NUM=25600; //6400*4
size_t global_work_size[1] = {640}; ///
size_t local_work_size[1]={64}; ///256 PE
size_t groupNUM=global_work_size[0]/local_work_size[0];
int* input = new int[NUM];
for(int i=0;i<NUM;i++)
input[i]=i+1;
int* output = new int[(global_work_size[0]/local_work_size[0])*4];
cl_mem inputBuffer = clCreateBuffer(context, CL_MEM_READ_ONLY|CL_MEM_COPY_HOST_PTR, (NUM) * sizeof(int),(void *) input, NULL);
cl_mem outputBuffer = clCreateBuffer(context, CL_MEM_WRITE_ONLY , groupNUM*4* sizeof(int), NULL, NULL);
/**Step 8: Create kernel object */
cl_kernel kernel = clCreateKernel(program,"reduce", NULL);
/**Step 9: Sets Kernel arguments.*/
status = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&inputBuffer);
status = clSetKernelArg(kernel, 1, sizeof(cl_mem), (void *)&outputBuffer);
status = clSetKernelArg(kernel, 2, sizeof(int), &NUM);
/**Step 10: Running the kernel.*/
cl_event enentPoint;
status = clEnqueueNDRangeKernel(commandQueue, kernel, 1, NULL, global_work_size, local_work_size, 0, NULL, &enentPoint);
clWaitForEvents(1,&enentPoint); ///wait
clReleaseEvent(enentPoint);
isStatusOK(status);
/**Step 11: Read the cout put back to host memory.*/
status = clEnqueueReadBuffer(commandQueue, outputBuffer, CL_TRUE, 0,groupNUM*4 * sizeof(int), output, 0, NULL, NULL);
isStatusOK(status);
if(isVerify(NUM, groupNUM ,output) == 0)
cout<<"The result is right!!!"<<endl;
else
cout<<"The result is wrong!!!"<<endl;
/**Step 12: Clean the resources.*/
status = clReleaseKernel(kernel);//*Release kernel.
status = clReleaseProgram(program); //Release the program object.
status = clReleaseMemObject(inputBuffer);//Release mem object.
status = clReleaseMemObject(outputBuffer);
status = clReleaseCommandQueue(commandQueue);//Release Command queue.
status = clReleaseContext(context);//Release context.
free(input);
free(output);
free(devices);
return 0;
}
作者:cnblogs 旭東的博客