Linux下的Valgrind真是利器啊(不知道Valgrind的請自覺查看參考文獻(1)(2)),幫我找出了不少C++中的內存管理錯誤,前一陣子還在糾結為什麼VS 2013下運行良好的程序到了Linux下用g++編譯運行卻崩潰了,給出一堆匯編代碼也看不懂。久久不得解過後,想想肯定是內存方面的錯誤,VS在這方面一般都不檢查的,就算你的程序千瘡百孔,各種內存洩露、內存管理錯誤,只要不影響運行,沒有讀到不該讀的東西VS就不會告訴你(應該是VS內部沒實現這個內存檢測功能),因此用VS寫出的程序可能不是完美或健壯的。
更新:感謝博客園好心網友@shines77的熱心推薦,即VS中有內存洩漏檢測工具插件VLD(Visual Leak Detector),需要下載安裝,安裝方法請看官方介紹,使用非常簡單,在第一個入口文件裡加上#include <vld.h>就可以了,檢測報告在輸出窗口中。我安裝使用了下,不知道是安裝錯誤還是什麼,無論程序有無內存洩露,輸出都是“No memory leaks detected.”
下面是我通過 Valgrind第一次檢測得到的結果和一點點修改後得到的結果(還沒改完,所以還有不少內存洩露問題……):
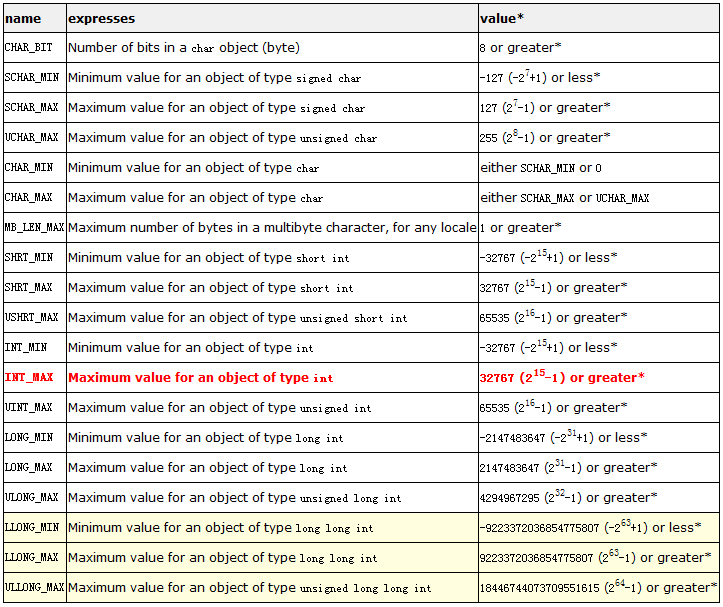
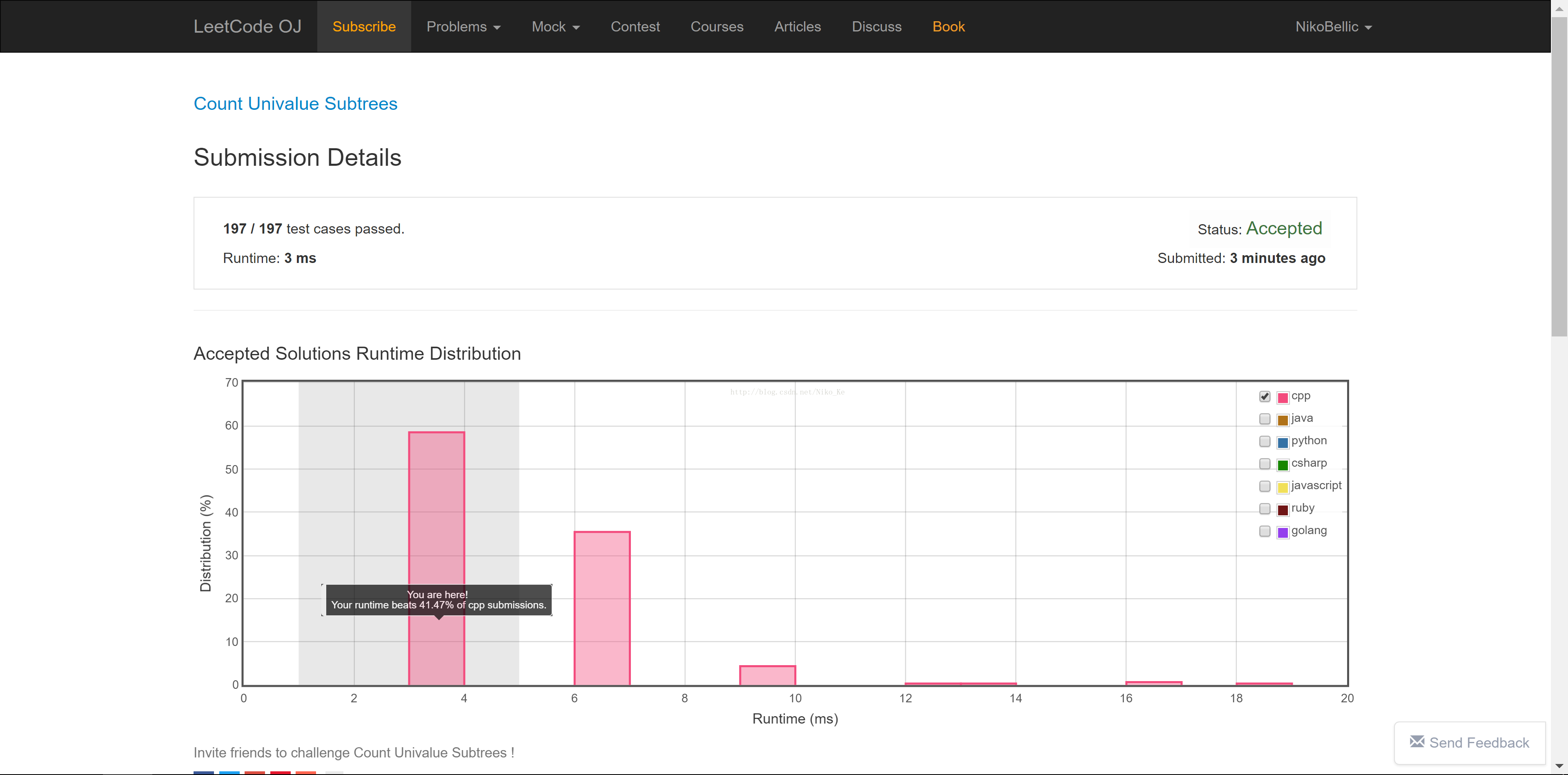
第一次檢測結果:慘不忍睹,因為程序規模有些大。
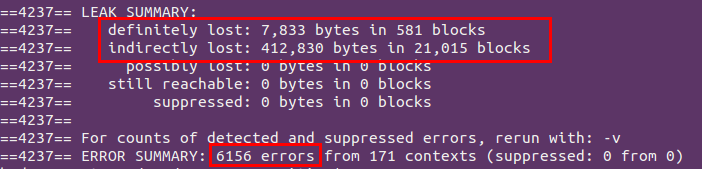
根據提示一點點修改過後,雖然還有個別錯誤和內存洩露問題,但還在修改中,至少已經能成功運行了……
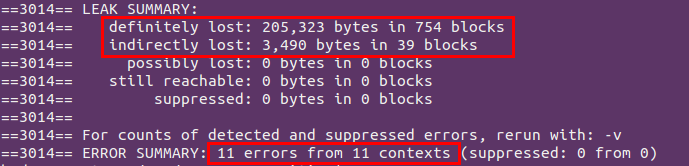
真感謝Valgrind幫我成功找出了一堆內存問題,查找過程中也為自己犯的低級錯誤而感到羞愧,所以記錄下來以便謹記。
1. 最多最低級的錯誤:不匹配地使用malloc/new/new[] 和 free/delete/delete[]
這樣的錯誤主要源於我對C++的new/new[]、delete/delete[]機制不熟悉,凡是new/new[]分配內存的類型變量我一概用delete進行釋放,或者有的變量用malloc進行分配,結果釋放的時候卻用delete,導致申請、釋放很多地方不匹配,很多內存空間沒能釋放掉。為了維護方便,我後來一律使用new/new[]和delete/delete[],拋棄C中的malloc和free。
如果將用戶new的類型分為基本數據類型和自定義數據類型兩種,那麼對於下面的操作相信大家都很熟悉,也沒有任何問題。
(1)基本數據類型
一維指針:
// 申請空間
int *d = new int[5];
// 釋放空間
delete[] d;
二維指針:
// 申請空間
int **d = new int*[5];
for (int i = 0; i < 5; i++)
d[i] = new int[10];
// 釋放空間
for (int i = 0; i < 5; i++)
delete[] d[i];
delete[] d;
(2)自定義數據類型
比如下面這樣一個類型:
class DFA {
bool is_mark;
char *s;
public:
~DFA() { printf("delete it.n"); }
};
一維指針:
DFA *d = new DFA();
delete d;
二維指針:
// 申請空間
DFA **d = new DFA*[5];
for (int i = 0; i < 5; i++)
d[i] = new DFA();
// 釋放空間
for (int i = 0; i < 5; i++)
delete d[i];
delete[]d;
這沒有任何問題,因為我們都是配套使用new/delete和new[]/delete[]的。這在Valgrind下檢測也是完美通過的,但為什麼要這配套使用呢?原理是什麼?
雖然深究這些東西好像沒什麼實際意義,但對於想深入了解C++內部機制或像我一樣老是釋放出錯導致大量內存洩露的小白程序員還是值得研究的,至少知道了為什麼,以後就不會犯現在的低級錯誤。
參考文獻(3)是這樣描述的:
通常狀況下,編譯器在new的時候會返回用戶申請的內存空間大小,但是實際上,編譯器會分配更大的空間,目的就是在delete的時候能夠准確的釋放這段空間。
這段空間在用戶取得的指針之前以及用戶空間末尾之後存放。
實際上:blockSize = sizeof(_CrtMemBlockHeader) + nSize + nNoMansLandSize; 其中,blockSize 是系統所分配的實際空間大小,_CrtMemBlockHeader是new的頭部信息,其中包含用戶申請的空間大小等其他一些信息。 nNoMansLandSize是尾部的越界校驗大小,一般是4個字節“FEFEFEFE”,如果用戶越界寫入這段空間,則校驗的時候會assert。nSize才是為我們分配的真正可用的內存空間。
用戶new的時候分為兩種情況
A. new的是基礎數據類型或者是沒有自定義析構函數的結構
B. new的是有自定義析構函數的結構體或類
這兩者的區別是如果有用戶自定義的析構函數,則delete的時候必須要調用析構函數,那麼編譯器delete時如何知道要調用多少個對象的析構函數呢,答案就是new的時候,如果是情況B,則編譯器會在new頭部之後,用戶獲得的指針之前多分配4個字節的空間用來記錄new的時候的數組大小,這樣delete的時候就可以取到個數並正確的調用。
這段描述可能有些晦澀難懂,參考文獻(4)給了更加詳細的解釋,一點即通。這樣的解釋其實也隱含著一個推論:如果new的是基本數據類型或者是沒有自定義析構函數的結構,那麼這種情況下編譯器不會在用戶獲得的指針之前多分配4個字節,因為這時候delete時不用調用析構函數,也就是不用知道數組個數的大小(因為只有調用析構函數時才需要知道要調用多少個析構函數,也就是數組的大小),而是直接傳入數組的起始地址從而釋放掉這塊內存空間,此時delete與delete[]是等價的。
2. 最看不懂的錯誤:一堆看不懂的Invalid read/write錯誤(更新:已解決)
比如下面這樣一個程序:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
struct accept_pair {
bool is_accept_state;
bool is_strict_end;
char app_name[0];
};
int main() {
char *s = "Alexia";
accept_pair *ap = (accept_pair*)malloc(sizeof(accept_pair) + sizeof(s));
strcpy(ap->app_name, s);
printf("app name: %s\n", ap->app_name);
free(ap);
return 0;
}
首先對該程序做個扼要的說明:
這裡結構體裡定義零長數組的原因在於我的需求:我在其它地方要用到很大的accept_pair數組,其中只有個別accept_pair元素中的app_name是有效的(取決於某些值的判斷,如果為true才給app_name賦值,如果為false則app_name無意義,為空),因此若是char app_name[20],那麼大部分accept_pair元素都浪費了這20個字節的空間,所以我在這裡先一個字節都不分配,到時誰需要就給誰分配,遵循“按需分配”的古老思想。可能有人會想,用char *app_name也可以啊,同樣能實現按需分配,是的,只是多4個字節而已,屬於替補方法。
在g++下經過測試,沒有什麼問題,能夠正確運行,但用Valgrind檢測時卻報出了一些錯誤,不是內存洩露問題,而是內存讀寫錯誤:
==3511== Memcheck, a memory error detector ==3511== Copyright (C) 2002-2012, and GNU GPL'd, by Julian Seward et al. ==3511== Using Valgrind-3.8.1 and LibVEX; rerun with -h for copyright info ==3511== Command: ./zero ==3511== ==3511== Invalid write of size 1 ==3511== at 0x402CD8B: strcpy (in /usr/lib/valgrind/vgpreload_memcheck-x86-linux.so) ==3511== by 0x80484E3: main (in /home/hadoop/test/zero) ==3511== Address 0x420002e is 0 bytes after a block of size 6 alloc'd ==3511== at 0x402C418: malloc (in /usr/lib/valgrind/vgpreload_memcheck-x86-linux.so) ==3511== by 0x80484C8: main (in /home/hadoop/test/zero) ==3511== ==3511== Invalid write of size 1 ==3511== at 0x402CDA5: strcpy (in /usr/lib/valgrind/vgpreload_memcheck-x86-linux.so) ==3511== by 0x80484E3: main (in /home/hadoop/test/zero) ==3511== Address 0x4200030 is 2 bytes after a block of size 6 alloc'd ==3511== at 0x402C418: malloc (in /usr/lib/valgrind/vgpreload_memcheck-x86-linux.so) ==3511== by 0x80484C8: main (in /home/hadoop/test/zero) ==3511== ==3511== Invalid read of size 1 ==3511== at 0x40936A5: vfprintf (vfprintf.c:1655) ==3511== by 0x409881E: printf (printf.c:34) ==3511== by 0x4063934: (below main) (libc-start.c:260) ==3511== Address 0x420002e is 0 bytes after a block of size 6 alloc'd ==3511== at 0x402C418: malloc (in /usr/lib/valgrind/vgpreload_memcheck-x86-linux.so) ==3511== by 0x80484C8: main (in /home/hadoop/test/zero) ==3511== ==3511== Invalid read of size 1 ==3511== at 0x40BC3C0: _IO_file_xsputn@@GLIBC_2.1 (fileops.c:1311) ==3511== by 0x4092184: vfprintf (vfprintf.c:1655) ==3511== by 0x409881E: printf (printf.c:34) ==3511== by 0x4063934: (below main) (libc-start.c:260) ==3511== Address 0x420002f is 1 bytes after a block of size 6 alloc'd ==3511== at 0x402C418: malloc (in /usr/lib/valgrind/vgpreload_memcheck-x86-linux.so) ==3511== by 0x80484C8: main (in /home/hadoop/test/zero) ==3511== ==3511== Invalid read of size 1 ==3511== at 0x40BC3D7: _IO_file_xsputn@@GLIBC_2.1 (fileops.c:1311) ==3511== by 0x4092184: vfprintf (vfprintf.c:1655) ==3511== by 0x409881E: printf (printf.c:34) ==3511== by 0x4063934: (below main) (libc-start.c:260) ==3511== Address 0x420002e is 0 bytes after a block of size 6 alloc'd ==3511== at 0x402C418: malloc (in /usr/lib/valgrind/vgpreload_memcheck-x86-linux.so) ==3511== by 0x80484C8: main (in /home/hadoop/test/zero) ==3511== ==3511== Invalid read of size 4 ==3511== at 0x40C999C: __GI_mempcpy (mempcpy.S:59) ==3511== by 0x40BC310: _IO_file_xsputn@@GLIBC_2.1 (fileops.c:1329) ==3511== by 0x4092184: vfprintf (vfprintf.c:1655) ==3511== by 0x409881E: printf (printf.c:34) ==3511== by 0x4063934: (below main) (libc-start.c:260) ==3511== Address 0x420002c is 4 bytes inside a block of size 6 alloc'd ==3511== at 0x402C418: malloc (in /usr/lib/valgrind/vgpreload_memcheck-x86-linux.so) ==3511== by 0x80484C8: main (in /home/hadoop/test/zero) ==3511== app name: Alexia ==3511== ==3511== HEAP SUMMARY: ==3511== in use at exit: 0 bytes in 0 blocks ==3511== total heap usage: 1 allocs, 1 frees, 6 bytes allocated ==3511== ==3511== All heap blocks were freed -- no leaks are possible ==3511== ==3511== For counts of detected and suppressed errors, rerun with: -v ==3511== ERROR SUMMARY: 9 errors from 6 contexts (suppressed: 0 from 0)
從檢測報告可以看出:
strcpy(ap->app_name, s);這句是內存寫錯誤,printf("app name: %s\n", ap->app_name);這句是內存讀錯誤,兩者都說明Valgrind認為ap->app_name所處內存空間是不合法的,可是我明明已經為其分配了內存空間,只是沒有注明這段空間就是給它用的,難道結構體中零長數組char app_name[0]是不能寫入值的嗎?還是我對零長數組的使用有誤?至今仍不得解,求大神解答……
更新:謝謝博客園網友@shines77的好心指正,這裡犯了個超級低級的錯誤,就是忘了main中s是char*的,因此sizeof(s)=4或8(64位機),因此accept_pair *ap = (accept_pair*)malloc(sizeof(accept_pair) + sizeof(s));這句並沒有為app_name申請足夠的空間,當然就會出現Invalid read/write了。這個低級錯誤真是。。。後來想了下,是自己在項目中直接拷貝過來的這句,項目中的s不是char*的,拷貝過來忘了改成accept_pair *ap = (accept_pair*)malloc(sizeof(accept_pair) + strlen(s) + 1);了,以後還是細心的好,真是浪費自己時間也浪費大家時間了。
3. 最不明所以的內存洩露:definitely lost/indefinitely lost(更新:已解決)
請看下面這樣一個程序:
#include <stdio.h>
#include <string.h>
class accept_pair {
public:
bool is_accept_state;
bool is_strict_end;
char *app_name;
public:
accept_pair(bool is_accept = false, bool is_end = false);
~accept_pair();
};
class DFA {
public:
unsigned int _size;
accept_pair **accept_states;
public:
DFA(int size);
~DFA();
void add_state(int index, char *s);
void add_size(int size);
};
int main() {
char *s = "Alexia";
DFA *dfa = new DFA(3);
dfa->add_state(0, s);
dfa->add_state(1, s);
dfa->add_state(2, s);
dfa->add_size(2);
dfa->add_state(3, s);
dfa->add_state(4, s);
printf("\napp_name: %s\n", dfa->accept_states[4]->app_name);
printf("size: %d\n\n", dfa->_size);
delete dfa;
return 0;
}
accept_pair::accept_pair(bool is_accept, bool is_end) {
is_accept_state = is_accept;
is_strict_end = is_end;
app_name = NULL;
}
accept_pair::~accept_pair() {
if (app_name) {
printf("delete accept_pair.\n");
delete[] app_name;
}
}
DFA::DFA(int size) {
_size = size;
accept_states = new accept_pair*[_size];
for (int s = 0; s < _size; s++) {
accept_states[s] = NULL;
}
}
DFA::~DFA() {
for (int i = 0; i < _size; i++) {
if (accept_states[i]) {
printf("delete dfa.\n");
delete accept_states[i];
accept_states[i] = NULL;
}
}
delete[] accept_states;
}
void DFA::add_state(int index, char *s) {
accept_states[index] = new accept_pair(true, true);
accept_states[index]->app_name = new char[strlen(s) + 1];
memcpy(accept_states[index]->app_name, s, strlen(s) + 1);
}
void DFA::add_size(int size) {
// reallocate memory for accept_states.
accept_pair **tmp_states = new accept_pair*[size + _size];
for (int s = 0; s < size + _size; s++)
tmp_states[s] = new accept_pair(false, false);
for (int s = 0; s < _size; s++) {
tmp_states[s]->is_accept_state = accept_states[s]->is_accept_state;
tmp_states[s]->is_strict_end = accept_states[s]->is_strict_end;
if (accept_states[s]->app_name != NULL) {
tmp_states[s]->app_name = new char[strlen(accept_states[s]->app_name) + 1];
memcpy(tmp_states[s]->app_name, accept_states[s]->app_name, strlen(accept_states[s]->app_name) + 1);
}
}
// free old memory.
for (int s = 0; s < _size; s++) {
if (accept_states[s] != NULL) {
delete accept_states[s];
accept_states[s] = NULL;
}
}
_size += size;
delete []accept_states;
accept_states = tmp_states;
}
雖然有點長,但邏輯很簡單,其中add_size()首先分配一個更大的accept_pair數組,將已有的數據全部拷貝進去,然後釋放掉原來的accept_pair數組所占空間,最後將舊的數組指針指向新分配的內存空間。這是個demo程序,在我看來這段程序是沒有任何內存洩露問題的,因為申請的所有內存空間最後都會在DFA析構函數中得到釋放。但是Valgrind的檢測報告卻報出了1個內存洩露問題(紅色的是程序輸出):
==3093== Memcheck, a memory error detector
==3093== Copyright (C) 2002-2012, and GNU GPL'd, by Julian Seward et al.
==3093== Using Valgrind-3.8.1 and LibVEX; rerun with -h for copyright info
==3093== Command: ./test
==3093==
delete accept_pair.
delete accept_pair.
delete accept_pair.
app_name: Alexia
size: 5
delete dfa.
delete accept_pair.
delete dfa.
delete accept_pair.
delete dfa.
delete accept_pair.
delete dfa.
delete accept_pair.
delete dfa.
delete accept_pair.
==3093==
==3093== HEAP SUMMARY:
==3093== in use at exit: 16 bytes in 2 blocks
==3093== total heap usage: 21 allocs, 19 frees, 176 bytes allocated
==3093==
==3093== 16 bytes in 2 blocks are definitely lost in loss record 1 of 1
==3093== at 0x402BE94: operator new(unsigned int) (in /usr/lib/valgrind/vgpreload_memcheck-x86-linux.so)
==3093== by 0x8048A71: DFA::add_size(int) (in /home/hadoop/test/test)
==3093== by 0x8048798: main (in /home/hadoop/test/test)
==3093==
==3093== LEAK SUMMARY:
==3093== definitely lost: 16 bytes in 2 blocks
==3093== indirectly lost: 0 bytes in 0 blocks
==3093== possibly lost: 0 bytes in 0 blocks
==3093== still reachable: 0 bytes in 0 blocks
==3093== suppressed: 0 bytes in 0 blocks
==3093==
==3093== For counts of detected and suppressed errors, rerun with: -v
==3093== ERROR SUMMARY: 1 errors from 1 contexts (suppressed: 0 from 0)
說明add_size()這個函數裡存在用new申請的內存空間沒有得到釋放,這一點感覺很費解,開始以為tmp_states指針所指向的數據賦給accept_states後沒有及時釋放導致的,於是我最後加了句delete tmp_states;結果招致更多的錯誤。相信不是Valgrind誤報,說明我對C++的new和delete機制還是不明不白,一些於我而言不明所以的內存洩露問題真心不得解,希望有人能夠告訴我是哪裡的問題?
------------------------------------------------------------------------------------------------------------------------------
更新:謝謝博客園好心網友@NewClear的解惑。這裡的確有洩露問題,下面是他的解答:
第3個問題,是有兩個洩露
DFA::add_state裡面直接
accept_states[index] = new accept_pair(true, true);
如果原來的accept_states[index]不為NULL就洩露了
而在DFA::add_size裡面,
for (int s = 0; s < size + _size; s++)
tmp_states[s] = new accept_pair(false, false);
對新分配的tmp_states的每一個元素都new了一個新的accept_pair
所以在main函數裡面dfa->add_size(2);以後,總共有5個成員,而且5個都不為NULL
之後
dfa->add_state(3, s);
dfa->add_state(4, s);
結果就導致了index為3和4的原先的對象洩露了
你的系統是32位的,所以一個accept_pair大小是8byte,兩個對象就是16byte
解決方案也很簡單,修改add_size函數,重新申請空間時僅為已有的accept_pair數據申請空間,其它的初始化為NULL,這樣在需要時才在add_state裡面申請空間,也就是修改add_size函數如下:
void DFA::add_size(int size) {
// reallocate memory for accept_states.
accept_pair **tmp_states = new accept_pair*[size + _size];
for (int s = 0; s < size + _size; s++)
tmp_states[s] = NULL;
for (int s = 0; s < _size; s++) {
tmp_states[s] = new accept_pair(false, false);
tmp_states[s]->is_accept_state = accept_states[s]->is_accept_state;
tmp_states[s]->is_strict_end = accept_states[s]->is_strict_end;
if (accept_states[s]->app_name != NULL) {
tmp_states[s]->app_name = new char[strlen(accept_states[s]->app_name) + 1];
memcpy(tmp_states[s]->app_name, accept_states[s]->app_name, strlen(accept_states[s]->app_name) + 1);
}
}
// free old memory.
for (int s = 0; s < _size; s++) {
if (accept_states[s] != NULL) {
delete accept_states[s];
accept_states[s] = NULL;
}
}
_size += size;
delete[]accept_states;
accept_states = tmp_states;
}
作者:cnblogs Alexia(minmin)