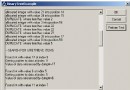
Uniscribe是Windows 2000以來就存在於WinAPI中的一個庫。這個庫能夠提供給我們關於字符串渲染的很多信息,譬如說哪裡可以換行啦,渲染的時候字符的順序應該是什麼樣子啦,還有每一個字符的大小什麼的。關於Uniscribe的資料可以在http://msdn.microsoft.com/en-us/library/windows/desktop/dd374091(v=vs.85).aspx看到。
在使用Uniscribe之前,我們先看看利用Uniscribe我們可以做到什麼樣的效果:
本欄目
當然,渲染的部分不包含在Uniscribe裡面,只不過Uniscribe告訴我們的信息可以讓我們直接計算出渲染每一小段字符串的位置。當然,這也就足夠了。下面我來介紹一下Uniscribe的幾個函數的作用。
首先,我們需要注意的是,Uniscribe一次只處理一行字符串。我們固然可以把多行字符串一次性丟給Uniscribe進行計算,但是得到的結果處理起來要困難得多。所以我們一次只給Uniscribe一行的字符串。現在我們需要渲染一個帶有多種格式的一行字符串。首先我們需要知道這些字符串可以被分為多少段。這在那些從右到左閱讀的文字(譬如說阿拉伯文)特別重要,而且這也是一個特別復雜的話題,在這裡我就不講了,我們假設我們只處理從左到右的字符串。
於是我們第一個遇到的函數就是ScriptItemize。
HRESULT ScriptItemize( _In_ const WCHAR *pwcInChars, _In_ int cInChars, _In_ int cMaxItems, _In_opt_ const SCRIPT_CONTROL *psControl, _In_opt_ const SCRIPT_STATE *psState, _Out_ SCRIPT_ITEM *pItems, _Out_ int *pcItems );
由於我們不處理從右到左的字符串渲染,也不處理把數字變成亂七八糟格式的效果(譬如在某些邪惡的帝國主義國家12345被表達成12,345),因此這個函數的psControl和psState參數我們都可以給NULL。這個時候我們需要首先為SCRIPT_ITEM數組分配空間。由於一個字符串的item最多就是字符數量那麼多個,所以我們要先創建一個cInChars+1那麼長的SCRIPT_ITEM數組。在調用了這個函數之後,*pcItems+1的結果就是pItems裡面的有效長度了。為什麼pItems的長度總是要+1呢?因為SCRIPT_ITEM裡面有一個很有用的成員叫做iCharPos,這個成員告訴我們這個item是從字符串的什麼地方開始的。那長度呢?自然是用下一個SCRIPT_ITEM的cCharPos去剪了。那麼最後一個item怎麼辦呢?所以ScriptItemize給了我們額外的一個結尾item,讓我們總是可以方便的這麼減……特別的蛋疼……
好了,現在我們把一行字符串分成了各個item。現在第一個問題就來了,一行字符串裡面可能有各種不同的字體的樣式,接下來怎麼辦呢?我們要同時用item的邊界和樣式的邊界來切割這個字符串,讓每一個字符串的片段都完全被某個item包含,並且片段的所有字符都有一樣的樣式。這聽起來好像很復雜,我來舉個例子:
譬如我們有一個字符串長成下面這個樣子:
This parameter (foo) is optional
然後ScriptItemize告訴我們這個字符串一共分為3個片段(這個劃分當然是我胡扯的,我只是舉個例子):
This parameter
(foo)
is optional
所以,字體的樣式和ScriptItemize的結果就把這個字符串分成了下面的五段:
This
parameter
(foo)
is
optional
是不是聽起來很直觀呢?但是代碼寫起來還是比較麻煩的,不過其實說麻煩也不麻煩,只需要大約十行左右就可以搞定了。在MSDN裡面,這五段的“段”叫做“run”或者是“range”。
現在,我們拿起一個run,送進一個叫做ScriptShape的函數裡面:
HRESULT ScriptShape( _In_ HDC hdc, _Inout_ SCRIPT_CACHE *psc, _In_ const WCHAR *pwcChars, _In_ int cChars, _In_ int cMaxGlyphs, _Inout_ SCRIPT_ANALYSIS *psa, _Out_ WORD *pwOutGlyphs, _Out_ WORD *pwLogClust, _Out_ SCRIPT_VISATTR *psva, _Out_ int *pcGlyphs );
這個函數可以告訴我們,這一堆wchar_t可以被如何分割成glyph。這裡我們要注意的是,glyph的數量和wchar_t的數量並不相同。所以在調用這個函數的時候,我們要先猜一個長度來分配空間。MSDN告訴我們,我們可以先讓cMaxGlyphs = cChars*1.5 + 16。
在上面的參數裡,SCRIPT_ANALYSIS其實就是SCRIPT_ITEM::a。由於一個run肯定是完整的屬於一個item的,因此SCRIPT_ITEM就可以直接從上一個函數的結果獲得了。然後這個函數告訴我們三個信息:
1、pwOutGlyphs:這個字符串一共有多少glyph組成。
2、psva:每一個glyph的屬性是什麼。
3、pwLogClust:wchar_t(術語叫unicode code point)是如何跟glyph對應起來的。
在這裡解釋一下glyph是什麼意思。glyph其實就是字體裡面的一個“圖”。一個看起來像一個字符的東西,有可能由多個glyph組成,譬如說“á”,其實就占用了兩個wchar_t,同時這兩個wchar_t具有兩個glyph(a和上面的小點)。而且這兩個wchar_t在渲染的時候必須被渲染在一起,因此他們至少應該屬於同一個range,鼠標在文本框選中的時候,這兩個wchar_t必須作為一個整體(後面這些信息可以由ScriptBreak函數給出)。當然還有1個wchar_t對多個glyph的情況,但是我現在一下子找不到。
不僅如此,還有兩個wchar_t對一個glyph的情況,譬如說這些字“ ”。雖然wchar_t的范圍是0到65536,但這並不代表utf-16只有6萬多個字符(實際上是60多萬),所以wchar_t其實也是變長的。但是utf-16的編碼設計的很好,當我們拿到一個wchar_t的時候,我們通過閱讀他們的數字就可以知道這個wchar_t是只有一個code point的、還是那些兩個code point的字的第一個或者是第二個,跟我們以前遇到的MBCS(char/ANSI)完全不同。
因此wchar_t和glyph的對應關系很復雜,可能是一對多、多對一、一對一或者多對多。所以pwLogClust這個數組就特別的重要。MSDN裡面有一個例子:
譬如說我們的一個7個wchar_t的字符串被分成4組glyph,對應關系如下:
字符:| c1u1 | c2u1 | c3u1 c3u2 c3u3 | c4u1 c4u2 |
圖案:| c1g1 | c2g1 c2g2 c2g3 | c3g1 | c4g1 c4g2 c4g3 |
上面的意思是,第二個字符c2u2被渲染成了3個glyph:c2g1、c2g2和c2g3,而c3u1、c3u2和c3u3三個字符責備合並成了一個glyph:c3g1。這種情況下,pwLogClust[cChars]的內容就是下面這個樣子的:
| 0 | 1 | 4 4 4 | 5 5 |
連續的數字相同的幾個clust說明這些wchar_t是被歸到一起的,而且這一組wchar_t的第一個glyph的的序號就是pwLogClust的內容了。那麼這一組wchar_t究竟有多少個glyph呢?當然就要看下一組wchar_t的第一個glyph在哪了。
為什麼我們需要這些信息呢?因為字符串的長度是按照glyph的長度來計算的!而且接下來我們要介紹的函數ScriptPlace會真的給我們每一個glyph的長度。因此我們在計算換行的時候,我們只能在每一組glyph並且ScriptBreak告訴我們可以換行的那個地方換行,所以當我們拿出一段完整的不會被換行的一個run的子集的時候,我們要在渲染的時候計算長度,就要特別小心glyph和wchar_t的對應關系。因為我們渲染的是一串wchar_t,但是我們的長度是按照glyph計算的,這個對應關系要是亂掉了,要麼計算出錯,要麼渲染的字符選錯,總之是很麻煩的。那麼ScriptPlace究竟長什麼樣子呢:
HRESULT ScriptPlace( _In_ HDC hdc, _Inout_ SCRIPT_CACHE *psc, _In_ const WORD *pwGlyphs, _In_ int cGlyphs, _In_ const SCRIPT_VISATTR *psva, _Inout_ SCRIPT_ANALYSIS *psa, _Out_ int *piAdvance, _Out_ GOFFSET *pGoffset, _Out_ ABC *pABC );
這就是那個傳說中的幫我們計算glyph大小的函數了。其中pwGlyphs就是我們剛剛從ScriptShape函數拿到的pwOutGlyphs,而psa還是那個psa,psva也還是那個psva。接下來的piAdvance數組告訴我們每一個glyph的長度,pGoffset這個是每一個glyph的偏移量(還記得“á”上面的那個小點嗎),pABC是整一個run的長度。至於ABC的三個長度我們並不用管,因為我們需要的是pABC裡面三個長度的和。而且這個和跟piAdvance的所有數字加起來一樣。
現在我們拿到了所有glyph的尺寸信息,和他們的分組情況,最後就是知道字符串的一些屬性了,譬如說在哪裡可以換行。為什麼要知道這些呢?譬如說我們有一個字符串叫做
c:\ThisIsAFolder\ThisIsAFile.txt
然後我們渲染字符串的位置可以容納下“c:\ThisIsAFolder\”,卻不能容納完整的“c:\ThisIsAFolder\ThisIsAFile”。這個時候,ScriptBreak函數就可以告訴我們,一個優美的換行可以在斜槓“\”的後面產生。讓我們來看看這個ScriptBreak函數的真面目:
HRESULT ScriptBreak( _In_ const WCHAR *pwcChars, _In_ int cChars, _In_ const SCRIPT_ANALYSIS *psa, _Out_ SCRIPT_LOGATTR *psla );
這個函數告訴我們每一個wchar_t對應的SCRIPT_LOGATTR。這個結構我們暫時只關心下面幾個成員:
1、fSoftBreak:可以被換行的位置。譬如說上面那個美妙的換行在“\”處,就是因為接下來的ThisIsAFile的第一個字符“T”的fSoftBreak是TRUE。
2、fCharStop和fWordStop:告訴我們每一個wchar_t是不是char或者word的第一個code point(參考那些一個字有兩個wchar_t那麼長的 )。
現在我們距離大功告成已經很近了。我們在渲染的時候,就一個run一個run的渲染。當我們發現一行剩余的空間不夠容納一個完整的run的時候,我們就可以用ScriptBreak告訴我們的信息,把這個run看成若干個可以被切開的段,然後用ScriptPlace告訴我們的piAdvance算出每一個切開的小段落的長度,然後盡可能多的完整渲染這些段。
上面這段話雖然很簡單,但是實際上需要注意的事情特別多,譬如說那個復雜的wchar_t和glyph的關系。我們通過piAdvance計算出可以一次性渲染的glyph有多少個,再把通過ScriptShape告訴我們的pwLogClust把這些glyph換算成對應wchar_t的范圍。最後再把他們送進TextOut函數裡,如果你用的是GDI的話。每次渲染完一些glyph,x坐標就要偏移他們的piAdvances的和。
如果把上面這些事情全部做完的話,我們就已經完整的渲染出一行帶有復雜結構的文字了。
=========================================================
最後我貼上這個程序的代碼。這個程序使用GacUI編寫,中間的部分使用GDI進行渲染。由於這只是個臨時代碼,會從codeplex上刪掉,所以把代碼留在這裡,給有需要的人閱讀。
代碼裡面用到的這個叫document.txt的文件,可以在GacUI的Codeplex頁面上下載代碼後,在(\Libraries\GacUI\GacUISrc\GacUISrcCodepackedTest\Resources\document.txt)找到
#include <GacUI.h>
#include <usp10.h>
#pragma comment(lib, "usp10.lib")
using namespace vl::collections;
using namespace vl::stream;
using namespace vl::regex;
using namespace vl::presentation::windows;
int CALLBACK WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int CmdShow)
{
return SetupWindowsGDIRenderer();
}
/***********************************************************************
Uniscribe
***********************************************************************/
bool operator==(const SCRIPT_ITEM&, const SCRIPT_ITEM&){return false;}
bool operator!=(const SCRIPT_ITEM&, const SCRIPT_ITEM&){return false;}
bool operator==(const SCRIPT_VISATTR&, const SCRIPT_VISATTR&){return false;}
bool operator!=(const SCRIPT_VISATTR&, const SCRIPT_VISATTR&){return false;}
bool operator==(const GOFFSET&, const GOFFSET&){return false;}
bool operator!=(const GOFFSET&, const GOFFSET&){return false;}
bool operator==(const SCRIPT_LOGATTR&, const SCRIPT_LOGATTR&){return false;}
bool operator!=(const SCRIPT_LOGATTR&, const SCRIPT_LOGATTR&){return false;}
namespace test
{
/***********************************************************************
DocumentFragment
***********************************************************************/
class DocumentFragment : public Object
{
public:
bool paragraph;
WString font;
bool bold;
Color color;
int size;
WString text;
Ptr<WinFont> fontObject;
DocumentFragment()
:paragraph(false)
,bold(false)
,size(0)
{
}
DocumentFragment(Ptr<DocumentFragment> prototype, const WString& _text)
:paragraph(prototype->paragraph)
,font(prototype->font)
,bold(prototype->bold)
,color(prototype->color)
,size(prototype->size)
,fontObject(prototype->fontObject)
,text(_text)
{
}
WString GetFingerPrint()
{
return font+L":"+(bold?L"B":L"N")+L":"+itow(size);
}
};
int ConvertHex(wchar_t c)
{
if(L'a'<=c && c<=L'f') return c-L'a'+10;
if(L'A'<=c && c<=L'F') return c-L'A'+10;
if(L'0'<=c && c<=L'9') return c-L'0';
return 0;
}
Color ConvertColor(const WString& colorString)
{
return Color(
ConvertHex(colorString[1])*16+ConvertHex(colorString[2]),
ConvertHex(colorString[3])*16+ConvertHex(colorString[4]),
ConvertHex(colorString[5])*16+ConvertHex(colorString[6])
);
}
// 本欄目