libevent 是一款非常好用的 C 語言網絡庫,它也采用 Reactor 模型,正好可以與 muduo 做一對 比。
本文用 ping pong 測試來對比 muduo 和 libevent2 的吞吐量,測試結果表明 muduo 吞吐量 平均比 libevent2 高 18% 以上,個別情況達到 70%。
測試對象
libevent 2.0.6-rc (http://monkey.org/~provos/libevent-2.0.6-rc.tar.gz)
muduo 0.1.1 (http://muduo.googlecode.com/files/muduo-0.1.1-alpha.tar.gz) SHA1 Checksum: a446ea8a22915f439063d2bc52eb2dc4b9caf92d
測試環境與測試方法
測試環境與前文《muduo 與 boost asio 吞吐量對比》相同。
我自己編寫了 libevent2 的 ping pong 測試代碼,地址在 http://github.com/chenshuo/recipes/tree/master/pingpong/libevent/ 。由於這個測試代碼沒有使 用多線程,所以本次測試只對比單線程下的性能。
測試內容為:客戶端與服務器運行在同一台 機器,均為單線程,測試並發連接數為 1/10/100/1000/10000 時的吞吐量。
在同一台機器測試 吞吐量的原因:
現在的 CPU 很快,即便是單線程單 TCP 連接也能把 Gigabit 以太網的帶寬跑滿。如果用兩台機器 ,所有的吞吐量測試結果都將是 100 MiB/s,失去了對比的意義。(或許可以對比哪個庫占的 CPU 少 。)
在同一台機器上測試,可以在 CPU 資源相同的情況下,單純對比網絡庫的效率。也就是說單線程下 ,服務端和客戶端各占滿 1 個 CPU,比較哪個庫的吞吐量高。
測試結果
單線程吞吐量測試,數字越大越好:
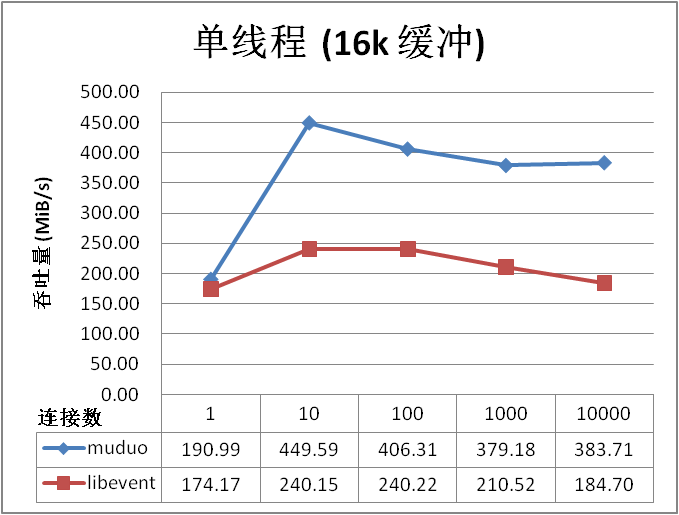
以上結果讓人大跌眼鏡,muduo 居然比 libevent 快 70%!跟蹤 libevent2 的源代碼發現,它每次 最多從 socket 讀取 4096 字節的數據 (證據在 buffer.c 的 evbuffer_read() 函數),怪不得吞吐量 比 muduo 小很多。因為在這一測試中,muduo 每次讀取 16384 字節,系統調用的性價比較高。
buffer.c:#define EVBUFFER_MAX_READ 4096
為了公平起見,我 再測了一次,這回兩個庫都發送 4096 字節的消息。
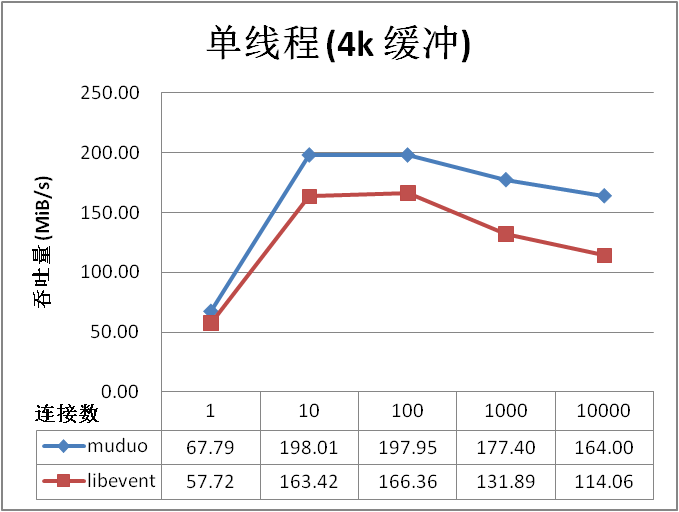
測試結果表明 muduo 吞吐量平均比 libevent2 高 18% 以上。
討論
由於 libevent2 每次最多從網絡讀取 4096 字節,大大限制了它的吞吐量。
查看本欄目