分布式基礎學習
所謂分布式,在這裡,很狹義的指代以Google的三駕馬車,GFS、Map/Reduce、BigTable 為框架核心的分布式存儲和計算系統。通常如我一樣初學的人,會以Google這幾份經典的論 文作為開端的。它們勾勒出了分布式存儲和計算的一個基本藍圖,已可窺見其幾分風韻,但 終究還是由於缺少一些實現的代碼和示例,色彩有些斑駁,缺少了點感性。幸好我們還有 Open Source,還有Hadoop。Hadoop是一個基於Java實現的,開源的,分布式存儲和計算的項 目。作為這個領域最富盛名的開源項目之一,它的使用者也是大牌如雲,包括了Yahoo, Amazon,Facebook等等(好吧,還可能有校內,不過這真的沒啥分量...)。Hadoop本身,實 現的是分布式的文件系統HDFS,和分布式的計算(Map/Reduce)框架,此外,它還不是一個 人在戰斗,Hadoop包含一系列擴展項目,包括了分布式文件數據庫HBase(對應Google的 BigTable),分布式協同服務ZooKeeper(對應Google的Chubby),等等。。。
如此,一個看上去不錯的黃金搭檔浮出水面,Google的論文 + Hadoop的實現,順著論文 的框架看具體的實現,用實現來進一步理解論文的邏輯,看上去至少很美。網上有很多前輩 們,做過Hadoop相關的源碼剖析工作,我關注最多的是這裡,目前博主已經完成了HDFS的剖 析工作,Map/Reduce的剖析正火熱進行中,更新頻率之高,剖析之詳盡,都是難得一見的, 所以,走過路過一定不要錯過了。此外,還有很多Hadoop的關注者和使用者貼過相關的文章 ,比如:這裡,這裡。也可以去Hadoop的中文站點(不知是民間還是官方...),搜羅一些學 習資料。。。
我個人從上述資料中受益匪淺,而我自己要做的整理,與原始的源碼剖析有些不同,不是 依照實現的模塊,而是基於論文的脈絡和實現這樣系統的基本脈絡來進行的,也算,從另一 個角度給出一些東西吧。鑒於個人對於分布式系統的理解非常的淺薄,缺少足夠的實踐經驗 ,深入的問題就不班門弄斧了,僅做梳理和解析,大牛至此,可繞路而行了。。。
一. 分布式文件系統
分布式文件系統,在整個分布式系統體系中處於最低層最基礎的地位,存儲嘛,沒了數據 ,再好的計算平台,再完善的數據庫系統,都成了無水之舟了。那麼,什麼是分布式文件系 統,顧名思義,就是分布式+文件系統。它包含這兩個方面的內涵,從文件系統的客戶使用的 角度來看,它就是一個標准的文件系統,提供了一系列API,由此進行文件或目錄的創建、移 動、刪除,以及對文件的讀寫等操作。從內部實現來看,分布式的系統則不再和普通文件系 統一樣負責管理本地磁盤,它的文件內容和目錄結構都不是存儲在本地磁盤上,而是通過網 絡傳輸到遠端系統上。並且,同一個文件存儲不只是在一台機器上,而是在一簇機器上分布 式存儲,協同提供服務,正所謂分布式。。。
因此,考量一個分布式文件系統的實現,其實不妨可以從這兩方面來分別剖析,而後合二 為一。首先,看它如何去實現文件系統所需的基本增刪改查的功能。然後,看它如何考慮分 布式系統的特點,提供更好的容錯性,負載平衡,等等之類的。這二者合二為一,就明白了 一個分布式文件系統,整體的實現模式。。。
I. 術語對照
說任何東西,都需要統一一下語言先,不然明明說的一個意思,卻容易被理解到另一個地 方去。Hadoop的分布式文件系統HDFS,基本是按照Google論文中的GFS的架構來實現的。但是 ,HDFS為了彰顯其不走尋常路的本性,其中的大量術語,都與GFS截然不同。明明都是一個枝 上長的土豆,它偏偏就要叫山藥蛋,弄得水火不容的,苦了我們看客。秉承老好人,誰也不 得罪的方針,文中,既不采用GFS的叫法,也不采用Hadoop的稱謂,而是另辟蹊徑,自立門戶 ,搞一套自己的中文翻譯,為了避免不必要的痛楚,特此先來一帖術語對照表,要不懂查一 查,包治百病。。。
文中所用翻譯 HDFS中的術語 GFS中的術語 術語解釋 主控服務器 NameNode Master 整個文件系統的大腦,它提供整個文件系統的目錄信息,並 且管理各個數據服務器。 數據服務器 DataNode Chunk Server 分布式文件系統中的每一個文件,都被切分成若干個數據塊 ,每一個數據塊都被存儲在不同的服務器上,此服務器稱之為數據服務器。 數據塊 Block Chunk 每個文件都會被切分成若干個塊,每一塊都有連續的一段文 件內容,是存儲的基恩單位,在這裡統一稱做數據塊。 數據包 Packet 無 客戶端寫文件的時候,不是一個字節一個字節寫入文件系統 的,而是累計到一定數量後,往文件系統中寫入一次,每發送一次的數據,都稱為一個數據 包。 傳輸塊 Chunk 無 在每一個數據包中,都會將數據切成更小的塊,每一個塊配 上一個奇偶校驗碼,這樣的塊,就是傳輸塊。 備份主控服務器 SecondaryNameNode 無 備用的主控服務器,在身後默默的拉取著主控服務器 的日志 ,等待主控服務器犧牲後被扶正。
*注:本文采用的Hadoop是0.19.0版本。
II. 基本架構
1. 服務器介紹
與單機的文件系統不同,分布式文件系統不是將這些數據放在一塊磁盤上,由上層操作系 統來管理。而是存放在一個服務器集群上,由集群中的服務器,各盡其責,通力合作,提供 整個文件系統的服務。其中重要的服務器包括:主控服務器(Master/NameNode),數據服務 器(ChunkServer/DataNode),和客戶服務器。HDFS和GFS都是按照這個架構模式搭建的。個 人覺得,其中設計的最核心內容是:文件的目錄結構獨立存儲在一個主控服務器上,而具體 文件數據,拆分成若干塊,冗余的存放在不同的數據服務器上。
存儲目錄結構的主控服務器,在GFS中稱為Master,在HDFS中稱為NameNode。這兩個名字 ,叫得都有各自的理由,是瞎子摸象各表一面。Master是之於數據服務器來叫的,它做為數 據服務器的領導同志存在,管理各個數據服務器,收集它們的信息,了解所有數據服務器的 生存現狀,然後給它們分配任務,指揮它們齊心協力為系統服務;而NameNode是針對客戶端 來叫的,對於客戶端而言,主控服務器上放著所有的文件目錄信息,要找一個文件,必須問 問它,由此而的此名。。。
主控服務器在整個集群中,同時提供服務的只存在一個,如果它不幸犧牲的話,會有後備 軍立刻前赴後繼的跟上,但,同一時刻,需要保持一山不容二虎的態勢。這種設計策略,避 免了多台服務器間即時同步數據的代價,而同時,它也使得主控服務器很可能成為整個架構 的瓶頸所在。因此,盡量為主控服務器減負,不然它做太多的事情,就自然而然的晉升成了 一個分布式文件系統的設計要求。。。
每一個文件的具體數據,被切分成若干個數據塊,冗余的存放在數據服務器。通常的配置 ,每一個數據塊的大小為64M,在三個數據服務器上冗余存放(這個64M,不是隨便得來的, 而是經過反復實踐得到的。因為如果太大,容易造成熱點的堆疊,大量的操作集中在一台數 據服務器上,而如果太小的話,附加的控制信息傳輸成本,又太高了。因此沒有比較特定的 業務需求,可以考慮維持此配置...)。數據服務器是典型的四肢發達頭腦簡單的苦力,其主 要的工作模式就是定期向主控服務器匯報其狀況,然後等待並處理命令,更快更安全的存放 好數據。。。
此外,整個分布式文件系統還有一個重要角色是客戶端。它不和主控服務和數據服務一樣 ,在一個獨立的進程中提供服務,它只是以一個類庫(包)的模式存在,為用戶提供了文件 讀寫、目錄操作等APIs。當用戶需要使用分布式文件系統進行文件讀寫的時候,把客戶端相 關包給配置上,就可以通過它來享受分布式文件系統提供的服務了。。。
2. 數據分布
一個文件系統中,最重要的數據,其實就是整個文件系統的目錄結構和具體每個文件的數 據。具體的文件數據被切分成數據塊,存放在數據服務器上。每一個文件數據塊,在數據服 務器上都表征為出雙入隊的一對文件(這是普通的Linux文件),一個是數據文件,一個是附 加信息的元文件,在這裡,不妨把這對文件簡稱為數據塊文件。數據塊文件存放在數據目錄 下,它有一個名為current的根目錄,然後裡面有若干個數據塊文件和從dir0-dir63的最多64 個的子目錄,子目錄內部結構等同於current目錄,依次類推(更詳細的描述,參見這裡)。 個人覺得,這樣的架構,有利於控制同一目錄下文件的數量,加快檢索速度。。。
這是磁盤上的物理結構,與之對應的,是內存中的數據結構,用以表征這樣的磁盤結構, 方便讀寫操作的進行。Block類用於表示數據塊,而FSDataset類是數據服務器管理文件塊的 數據結構,其中,FSDataset.FSDir對應著數據塊文件和目錄,FSDataset.FSVolume對應著一 個數據目錄,FSDataset.FSVolumeSet是FSVolume的集合,每一個FSDataset有一個 FSVolumeSet。多個數據目錄,可以放在不同的磁盤上,這樣有利於加快磁盤操作的速度。相 關的類圖,可以參看這裡 。。。
此外,與FSVolume對應的,還有一個數據結構,就是DataStorage,它是Storage的子類, 提供了升級、回滾等支持。但與FSVolume不一樣,它不需要了解數據塊文件的具體內容,它 只知道有這麼一堆文件放這裡,會有不同版本的升級需求,它會處理怎麼把它們升級回滾之 類的業務(關於Storage,可以參見這裡)。而FSVolume提供的接口,都基本上是和Block相 關的。。。
相比數據服務器,主控服務器的數據量不大,但邏輯更為復雜。主控服務器主要有三類數 據:文件系統的目錄結構數據,各個文件的分塊信息,數據塊的位置信息(就數據塊放置在 哪些數據服務器上...)。在GFS和HDFS的架構中,只有文件的目錄結構和分塊信息才會被持 久化到本地磁盤上,而數據塊的位置信息則是通過動態匯總過來的,僅僅存活在內存數據結 構中,機器掛了,就灰飛煙滅了。每一個數據服務器啟動後,都會向主控服務器發送注冊消 息,將其上數據塊的狀況都告知於主控服務器。俗話說,簡單就是美,根據DRY原則,保存的 冗余信息越少,出現不一致的可能性越低,付出一點點時間的代價,換取了一大把邏輯上的 簡單性,絕對應該是一個包賺不賠的買賣。。。
在HDFS中,FSNamespacesystem類就負責保管文件系統的目錄結構以及每個文件的分塊狀 況的,其中,前者是由FSDirectory類來負責,後者是各個INodeFile本身維護。在INodeFile 裡面,有一個BlockInfo的數組,保存著與該文件相關的所有數據塊信息,BlockInfo中包含 了從數據塊到數據服務器的映射,INodeFile只需要知道一個偏移量,就可以提供相關的數據 塊,和數據塊存放的數據服務器信息。。。
3、服務器間協議
在Hadoop的實現中,部署了一套RPC機制,以此來實現各服務間的通信協議。在Hadoop中 ,每一對服務器間的通信協議,都定義成為一個接口。服務端的類實現該接口,並且建立RPC 服務,監聽相關的接口,在獨立的線程處理RPC請求。客戶端則可以實例化一個該接口的代理 對象,調用該接口的相應方法,執行一次同步的通信,傳入相應參數,接收相應的返回值。 基於此RPC的通信模式,是一個消息拉取的流程,RPC服務器等待RPC客戶端的調用,而不會先 發制人主動把相關信息推送到RPC客戶端去。。。
其實RPC的模式和原理,實在是沒啥好說的,之所以說,是因為可以通過把握好這個,徹 底理順Hadoop各服務器間的通信模式。Hadoop會定義一些列的RPC接口,只需要看誰實現,誰 調用,就可以知道誰和誰通信,都做些啥事情,圖中服務器的基本架構、各服務所使用的協 議、調用方向、以及協議中的基本內容。。。
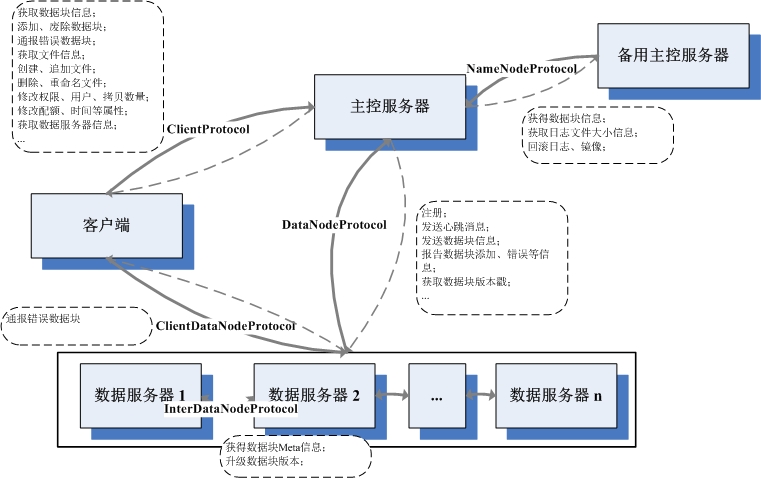
III. 基本的文件操作
基本的文件操作,可以分成兩類,一個是對文件目錄結構的操作,比如文件和目錄的創建 、刪除、移動、更名等等;另一個是對文件數據流的操作,包括讀取和寫入文件數據。當然 ,文件讀和寫,是有本質區別的,尤其是在數據冗余的情況下,因此,當成兩類操作也不足 為過。此外,要具體到讀寫的類別,也是可以再繼續分類下去的。在GFS的論文中,對於分布 式文件系統的讀寫場景有一個重要的假定(其實是從實際業務角度得來的...):就是文件的 讀取是由大數據量的連續讀取和小數據量的隨機讀取組成,文件的寫入則基本上都是批量的 追加寫,和偶爾的插入寫(GFS中還有大量的假設,它們構成了分布式文件系統架構設計的基 石。每一個系統架構都是搭建在一定假設上的,這些假設有些來自於實際業務的狀況,有些 是因為天生的條件約束,不基於假設理解設計,肯定會有失偏頗...)。在GFS中,對文件的 寫入分成追加寫和插入寫都有所支持,但是,在HDFS中僅僅支持追加寫,這大大降低了復雜 性。關於HDFS與GFS的一些不同,可以參看這裡。。。
1. 文件和目錄的操作
文件目錄的信息,全部囤積在主控服務器上,因此,所有對文件目錄的操作,只會直接涉 及到客戶端和主控服務器。整個目錄相關的操作流程基本都是這樣的:客戶端DFSClient調用 ClientProtocol定義的相關函數,該操作通過RPC傳送到其實現者主控服務器NameNode那裡, NameNode做相關的處理後(很少...),調用FSNamesystem的相關函數。在FSNamesystem中, 往往是做一些驗證和租約操作,具體的目錄結構操作交由FSDirectory的相應函數來操作。最 後,依次返回,經由RPC傳送回客戶端。具體各操作涉及到的函數和具體步驟,參見下表:
相關操作 ClientProtocol / NameNode FSNamesystem FSDirectory 關鍵步驟 創建文件 create startFile addFile 1. 檢查是否有寫權限;
2. 檢查是否已經存在此文件,如果是覆寫,則先進行刪除操作;
3. 在指定路徑下添加INodeFileUnderConstruction的文件實例;
4. 寫日志;
5. 簽訂租約。
創建目錄 mkdirs mkdirs mkdirs 1. 檢查指定目錄是否是目錄;2. 檢查是否有相關權限;
3. 在指定路徑的INode下,添加子節點;
4. 寫日志。
改名操作 rename renameTo renameTo 1. 檢查相關路徑的權限;2. 從老路徑下移除,在新路徑下添加;
3. 修改相關父路徑的修改時間;
4. 寫日志;
5. 將租約從老路徑移動到新路徑下。
刪除操作 delete delete delete 1. 如果不是遞歸刪除,確認指定路徑是否是空目錄;2. 檢查相關權限;
3. 在目錄結構上移除相關INode;
4. 修改父路徑的修改時間;
5. 將相關的數據塊,放入到廢棄隊列中去,等待處理;
6. 寫日志;
7. 廢棄相關路徑的租約。
設置權限 setPermission setPermission setPermission 1. 檢查owner判斷是否有操作權限;2. 修改指定路徑下INode的權限;
3. 寫日志。
設置用戶 setOwner setOwner setOwner 1. 檢查是否有操作權限;2. 修改指定路徑下INode的權限;
3. 寫日志。
設置時間 setTimes setTimes setTimes 1. 檢查是否有寫權限;2. 修改指定路徑INode的時間信息;
3. 寫日志。
從上表可以看到,其實有的操作本質上還是涉及到了數據服務器,比如文件創建和刪除操 作。但是,之前提到,主控服務器只於數據服務器是一個等待拉取的地位,它們不會主動聯 系數據服務器,將指令傳輸給它們,而是放到相應的數據結構中,等待數據服務器來取。這 樣的設計,可以減少通信的次數,加快操作的執行速度。。。
另,上述步驟中,有些日志和租約相關的操作,從概念上來說,和目錄操作其實沒有任何 聯系,但是,為了滿足分布式系統的需求,這些操作是非常有必要的,在此,按下不表。。 。
2、文件的讀取
不論是文件讀取,還是文件的寫入,主控服務器扮演的都是中介的角色。客戶端把自己的 需求提交給主控服務器,主控服務器挑選合適的數據服務器,介紹給客戶端,讓客戶端和數 據服務器單聊,要讀要寫隨你們便。這種策略類似於DMA,降低了主控服務器的負載,提高了 效率。。。
因此,在文件讀寫操作中,最主要的通信,發生在客戶端與數據服務器之間。它們之間跑 的協議是ClientDatanodeProtocol。從這個協議中間,你無法看到和讀寫相關的接口,因為 ,在Hadoop中,讀寫操作是不走RPC機制的,而是另立門戶,獨立搭了一套通信框架。在數據 服務器一端,DataNode類中有一個DataXceiverServer類的實例,它在一個單獨的線程等待請 求,一旦接到,就啟動一個DataXceiver的線程,處理此次請求。一個請求一個線程,對於數 據服務器來說,邏輯上很簡單。當下,DataXceiver支持的請求類型有六種,具體的請求包和 回復包格式,請參見這裡,這裡,這裡。在Hadoop的實現中,並沒有用類來封裝這些請求, 而是按流的次序寫下來,這給代碼閱讀帶來挺多的麻煩,也對代碼的維護帶來一定的困難, 不知道是出於何種考慮。。。
相比於寫,文件的讀取實在是一個簡單的過程。在客戶端DFSClient中,有一個 DFSClient.DFSInputStream類。當需要讀取一個文件的時候,會生成一個DFSInputStream的 實例。它會先調用ClientProtocol定義getBlockLocations接口,提供給NameNode文件路徑、 讀取位置、讀取長度信息,從中取得一個LocatedBlocks類的對象,這個對象包含一組 LocatedBlock,那裡面有所規定位置中包含的所有數據塊信息,以及數據塊對應的所有數據 服務器的位置信息。當讀取開始後,DFSInputStream會先嘗試從某個數據塊對應的一組數據 服務器中選出一個,進行連接。這個選取算法,在當下的實現中,非常簡單,就是選出第一 個未掛的數據服務器,並沒有加入客戶端與數據服務器相對位置的考量。讀取的請求,發送 到數據服務器後,自然會有DataXceiver來處理,數據被一個包一個包發送回客戶端,等到整 個數據塊的數據都被讀取完了,就會斷開此鏈接,嘗試連接下一個數據塊對應的數據服務器 ,整個流程,依次如此反復,直到所有想讀的都讀取完了為止。。。
3、文件的寫入
文件讀取是一個一對一的過程,一個客戶端,只需要與一個數據服務器聯系,就可以獲得 所需的內容。但是,寫入操作,則是一個一對多的流程。一次寫入,需要在所有存放相關數 據塊的數據服務器都保持同步的更新,有任何的差池,整個流程就告失敗。。。
在分布式系統中,一旦涉及到寫入操作,並發處理難免都會淪落成為一個變了相的串行操 作。因為,如果不同的客戶端如果是任意時序並發寫入的話,整個寫入的次序無法保證,可 能你寫半條記錄我寫半條記錄,最後出來的結果亂七八糟不可估量。在HDFS中,並發寫入的 次序控制,是由主控服務器來把握的。當創建、續寫一個文件的時候,該文件的節點類,由 INodeFile升級成為INodeFileUnderConstruction,INodeFileUnderConstruction是 INodeFile的子類,它起到一個鎖的作用。如果當一個客戶端想創建或續寫的文件是 INodeFileUnderConstruction,會引發異常,因為這說明這個此處有爺,請另尋高就,從而 保持了並發寫入的次序性。同時,INodeFileUnderConstruction有包含了此時正在操作它的 客戶端的信息以及最後一個數據塊的數據服務器信息,當追加寫的時候可以更快速的響應。 。。
與讀取類似,DFSClient也有一個DFSClient.DFSOutputStream類,寫入開始,會創建此類 的實例。DFSOutputStream會從NameNode上拿一個LocatedBlock,這裡面有最後一個數據塊的 所有數據服務器的信息。這些數據服務器每一個都需要能夠正常工作(對於讀取,只要還有 一個能工作的就可以實現...),它們會依照客戶端的位置被排列成一個有著最近物理距離和 最小的序列(物理距離,是根據機器的位置定下來的...),這個排序問題類似於著名旅行商 問題,屬於NP復雜度,但是由於服務器數量不多,所以用最粗暴的算法,也並不會看上去不 美。。。
文件寫入,就是在這一組數據服務器上構造成數據流的雙向流水線。DFSOutputStream, 會與序列的第一個數據服務器建立Socket連接,發送請求頭,然後等待回應。DataNode同樣 是建立DataXceiver來處理寫消息,DataXceiver會依照包中傳過來的其他服務器的信息,建 立與下一個服務器的連接,並生成類似的頭,發送給它,並等待回包。此流程依次延續,直 到最後一級,它發送回包,反向著逐級傳遞,再次回到客戶端。如果一切順利,那麼此時, 流水線建立成功,開始正式發送數據。數據是分成一個個數據包發送的,所有寫入的內容, 被緩存在客戶端,當寫滿64K,會被封裝成DFSOutputStream.Packet類實例,放入 DFSOutputStream的dataQueue隊列。DFSOutputStream.DataStreamer會時刻監聽這個隊列, 一旦不為空,則開始發送,將位於dataQueue隊首的包移動到ackQueue隊列的隊尾,表示已發 送但尚未接受回復的包隊列。同時啟動ResponseProcessor線程監聽回包,直到收到相應回包 ,才將發送包從ackQueue中移除,表示成功。每一個數據服務器的DataXceiver收到了數據包 ,一邊寫入到本地文件中去,一邊轉發給下一級的數據服務器,等待回包,同前面建立流水 線的流程。。。
當一個數據塊寫滿了之後,客戶端需要向主控服務器申請追加新的數據塊。這個會引起一 次數據塊的分配,成功後,會將新的數據服務器組返還給客戶端。然後重新回到上述流程, 繼續前行。。。
關於寫入的流程,還可以參見這裡。此外,寫入涉及到租約問題,後續會仔細的來說。。 。
IV. 分布式支持
如果單機的文件系統是田裡勤懇的放牛娃,那麼分布式文件系統就是刀尖上討飯吃的馬賊 了。在分布式環境中,有太多的意外,數據隨時傳輸錯誤,服務器時刻准備犧牲,很多平常 稱為異常的現象,在這裡都需要按照平常事來對待。因此,對於分布式文件系統而言,僅僅 是滿足了正常狀況下文件系統各項服務還不夠,還需要保證分布式各種意外場景下健康持續 的服務,否則,將一無是處。。。
1、服務器的錯誤恢復
在分布式環境中,哪台服務器犧牲都是常見的事情,犧牲不可怕,可怕的是你都沒有時刻 准備好它們會犧牲。作為一個合格的分布式系統,HDFS當然時刻准備好了前赴後繼奮勇向前 。HDFS有三類服務器,每一類服務器出錯了,都有相應的應急策略。。。
a. 客戶端
生命最輕如鴻毛的童鞋,應該就是客戶端了。畢竟,做為一個文件系統的使用者,在整個 文件系統中的地位,難免有些歸於三流。而作為客戶端,大部分時候,犧牲了就犧牲了,沒 人哀悼,無人同情,只有在在辛勤寫入的時候,不幸辭世(機器掛了,或者網絡斷了,諸如 此類...),才會引起些恐慌。因為,此時此刻,在主控服務器上對應的文件,正作為 INodeFileUnderConstruction活著,僅僅為占有它的那個客戶端服務者,做為一個專一的文 件,它不允許別的客戶端染指。這樣的話,一旦占有它的客戶端服務者犧牲了,此客戶端會 依然占著茅坑不拉屎,讓如花似玉INodeFileUnderConstruction孤孤單單守寡終身。這種事 情當然無法容忍,因此,必須有辦法解決這個問題,辦法就是:租約。。。
租約,顧名思義,就是當客戶端需要占用某文件的時候,與主控服務器簽訂的一個短期合 同。這個合同有一個期限,在這個期限內,客戶端可以延長合同期限,一旦超過期限,主控 服務器會強行終止此租約,將這個文件的享用權,分配給他人。。。
在打開或創建一個文件,准備追加寫之前,會調用LeaseManager的addLease方法,在指定 的路徑下與此客戶端簽訂一份租約。客戶端會啟動DFSClient.LeaseChecker線程,定時輪詢 調用ClientProtocol的renewLease方法,續簽租約。在主控服務器一端,有一個 LeaseManager.Monitor線程,始終在輪詢檢查所有租約,查看是否有到期未續的租約。如果 一切正常,該客戶端完成寫操作,會關閉文件,停止租約,一旦有所意外,比如文件被刪除 了,客戶端犧牲了,主控服務器都會剝奪此租約,如此,來避免由於客戶端停機帶來的資源 被長期霸占的問題。。。
b. 數據服務器
當然,會掛的不只是客戶端,海量的數據服務器是一個更不穩定的因素。一旦某數據服務 器犧牲了,並且主控服務器被蒙在鼓中,主控服務器就會變相的欺騙客戶端,給它們無法連 接的讀寫服務器列表,導致它們處處碰壁無法工作。因此,為了整個系統的穩定,數據服務 器必須時刻向主控服務器匯報,保持主控服務器對其的完全了解,這個機制,就是心跳消息 。在HDFS中,主控服務器NameNode實現了DatanodeProtocol接口,數據服務器DataNode會在 主循環中,不停的調用該協議中的sendHeartbeat方法,向NameNode匯報狀況。在此調用中, DataNode會將其整體運行狀況告知NameNode,比如:有多少可用空間、用了多大的空間,等 等之類。NameNode會記住此DataNode的運行狀況,作為新的數據塊分配或是負載均衡的依據 。當NameNode處理完成此消息後,會將相關的指令封裝成一個DatanodeCommand對象,交還給 DataNode,告訴數據服務器什麼數據塊要刪除什麼數據塊要新增等等之類,數據服務器以此 為自己的行動依據。。。
但是,sendHeartbeat並沒有提供本地的數據塊信息給NameNode,那麼主控服務器就無法 知道此數據服務器應該分配什麼數據塊應該刪除什麼數據塊,那麼它是如何決定的呢?答案 就是DatanodeProtocol定義的另一個方法,blockReport。DataNode也是在主循環中定時調用 此方法,只是,其周期通常比調用sendHeartbeat的更長。它會提交本地的所有數據塊狀況給 NameNode,NameNode會和本地保存的數據塊信息比較,決定什麼該刪除什麼該新增,並將相 關結果緩存在本地對應的數據結構中,等待此服務器再發送sendHeartbeat消息過來的時候, 依照這些數據結構中的內容,做出相應的DatanodeCommand指令。blockReport方法同樣也會 返回一個DatanodeCommand給DataNode,但通常,只是為空(只有出錯的時候不為空),我想 ,增加緩存,也許是為了確保每個指令都可以重復發送並確定被執行。。。
c. 主控服務器
當然,作為整個系統的核心和單點,含辛茹苦的主控服務器含淚西去,整個分布式文件服 務集群將徹底癱瘓罷工。如何在主控服務器犧牲後,提拔新的主控服務器並迅速使其進入工 作角色,就成了系統必須考慮的問題。解決策略就是:日志。。。
其實這並不是啥新鮮東西,一看就知道是從數據庫那兒偷師而來的。在主控服務器上,所 有對文件目錄操作的關鍵步驟(具體文件內容所處的數據服務器,是不會被寫入日志的,因 為這些內容是動態建立的...),都會被寫入日志。另外,主控服務器會在某些時刻,將當下 的文件目錄完整的序列化到本地,這稱為鏡像。一旦存有鏡像,鏡像前期所寫的日志和其他 鏡像,都純屬冗余,其歷史使命已經完成,可以報廢刪除了。在主控服務器不幸犧牲,或者 是戰略性的停機修整結束,並重新啟動後,主控服務器會根據最近的鏡像 + 鏡像之後的所有 日志,重建整個文件目錄,迅速將服務能力恢復到犧牲前的水准。。。
對於數據服務器而言,它們會通過一些手段,迅速得知頂頭上司的更迭消息。它們會立刻 轉投新東家的名下,在新東家旗下注冊,並開始向其發送心跳消息,這個機制,可能用分布 式協同服務來實現,這裡不說也罷。。。
在HDFS的實現中,FSEditLog類是整個日志體系的核心,提供了一大堆方便的日志寫入API ,以及日志的恢復存儲等功能。目前,它支持若干種日志類型,都冠以OP_XXX,並提供相關 API,具體可以參見這裡。為了保證日志的安全性,FSEditLog提供了 EditLogFileOutputStream類作為寫入的承載類,它會同時開若干個本地文件,然後依次寫入 ,防止日志的損壞導致不可估量的後果。在FSEditLog上面,有一個FSImage類,存儲文件鏡 像並調用FSEditLog對外提供相關的日志功能。FSImage是Storage類的子類,如果對數據塊的 講述有所印象的話,你可以回憶起來,凡事從此類派生出來的東西,都具有版本性質,可以 進行升級和回滾等等,以此,來實現產生鏡像是對原有日志和鏡像處理的復雜邏輯。。。
目前,在HDFS的日志系統中,有些地方與GFS的描述有所不同。在HDFS中,所有日志文件 和鏡像文件都是本地文件,這就相當於,把日志放在自家的保險箱中,一旦主控服務器掛了 ,別的後繼而上的服務器也無法拿到這些日志和鏡像,用於重振雄風。因此,在HDFS中,運 行著一個SecondaryNameNode服務器,它做為主控服務器的替補,隱忍厚積薄發為篡位做好准 備,其中,核心內容就是:定期下載並處理日志和鏡像。SecondaryNameNode看上去像客戶端 一樣,與NameNode之間,走著NamenodeProtocol協議。它會不停的查看主控服務器上面累計 日志的大小,當達到阈值後,調用doCheckpoint函數,此函數的主要步驟包括:
首先是調用startCheckpoint做一些本地的初始化工作;
然後調用rollEditLog,將NameNode上此時操作的日志文件從edit切到edit.new上來,這 個操作瞬間完成,上層寫日志的函數完全感覺不到差別;
接著,調用downloadCheckpointFiles,將主控服務器上的鏡像文件和日志文件都下載到 此候補主控服務器上來;
並調用doMerge,打開鏡像和日志,將日志生成新的鏡像,保存覆蓋;
下一步,調用putFSImage把新的鏡像上傳回NameNode;
再調用rollFsImage,將鏡像換成新的,在日志從edit.new改名為edit;
最後,調用endCheckpoint做收尾工作。
整個算法涉及到NameNode和SecondaryNameNode兩個服務器,最終結果是NameNode和 SecondaryNameNode都依照算法進行前的日志生成了鏡像。而兩個服務器上日志文件的內容, 前者是整個算法進行期間所寫的日志,後者始終不會有任何日志。當主控服務器犧牲的時候 ,運行SecondaryNameNode的服務器立刻被扶正,在其上啟動主控服務,利用其日志和鏡像, 恢復文件目錄,並逐步接受各數據服務器的注冊,最終向外提供穩定的文件服務。。。
同樣的事情,GFS采用的可能是另外一個策略,就是在寫日志的時候,並不局限在本地, 而是同時書寫網絡日志,即在若干個遠程服務器上生成同樣的日志。然後,在某些時機,主 控服務器自己,生成鏡像,降低日志規模。當主控服務器犧牲,可以在擁有網絡日志的服務 器上啟動主控服務,升級成為主控服務器。。。
GFS與HDFS的策略相比較,前者是化整為零,後者則是批量處理,通常我們認為,批量處 理的平均效率更高一些,且相對而言,可能實現起來容易一些,但是,由於有間歇期,會導 致日志的丟失,從而無法100%的將備份主控服務器的狀態與主控服務器完全同步。。。
2、數據的正確性保證
在復雜紛繁的分布式環境中,我們堅定的相信,萬事皆有可能。哪怕各個服務器都舒舒服 服的活著,也可能有各種各樣的情況導致網絡傳輸中的數據丟失或者錯誤。並且在分布式文 件系統中,同一份文件的數據,是存在大量冗余備份的,系統必須要維護所有的數據塊內容 完全同步,否則,一人一言,不同客戶端讀同一個文件讀出不同數據,用戶非得瘋了不可。 。。
在HDFS中,為了保證數據的正確性和同一份數據的一致性,做了大量的工作。首先,每一 個數據塊,都有一個版本標識,在Block類中,用一個長整型的數generationStamp來表示版 本信息(Block類是所有表示數據塊的數據結構的基類),一旦數據塊上的數據有所變化,此 版本號將向前增加。在主控服務器上,保存有此時每個數據塊的版本,一旦出現數據服務器 上相關數據塊版本與其不一致,將會觸發相關的恢復流程。這樣的機制保證了各個數據服務 器器上的數據塊,在基本大方向上都是一致的。但是,由於網絡的復雜性,簡單的版本信息 無法保證具體內容的一致性(因為此版本信息與內容無關,可能會出現版本相同,但內容不 同的狀況)。因此,為了保證數據內容上的一致,必須要依照內容,作出簽名。。。
當客戶端向數據服務器追加寫入數據包時,每一個數據包的數據,都會切分成512字節大 小的段,作為簽名驗證的基本單位,在HDFS中,把這個數據段稱為Chunk,即傳輸塊(注意, 在GFS中,Chunk表達的是數據塊...)。在每一個數據包中,都包含若干個傳輸塊以及每一個 傳輸塊的簽名,當下,這個簽名是根據Java SDK提供的CRC算法算得的,其實就是一個奇偶校 驗。當數據包傳輸到流水線的最後一級,數據服務器會對其進行驗證(想一想,為什麼只在 最後一級做驗證,而不是每級都做...),一旦發現當前的傳輸塊簽名與在客戶端中的簽名不 一致,整個數據包的寫入被視為無效,Lease Recover(租約恢復)算法被觸發。。。
從基本原理上看,這個算法很簡單,就是取所有數據服務器上此數據塊的最小長度當作正 確內容的長度,將其他數據服務器上此數據塊超出此長度的部分切除。從正確性上看,此算 法無疑是正確的,因為至少有一個數據服務器會發現此錯誤,並拒絕寫入,那麼,如果寫入 了的,都是正確的;從效率上看,此算法也是高效的,因為它避免了重復的傳輸和復雜的驗 證,僅僅是各自刪除尾部的一些內容即可。但從具體實現上來看,此算法稍微有些繞,因為 ,為了降低本已不堪重負的主控服務器的負擔,此算法不是由主控服務器這個大腦發起的, 而是通過選舉一個數據服務器作為Primary,由Primary發起,通過調用與其他各數據服務器 間的InterDatanodeProtocol協議,最終完成的。具體的算法流程,參見LeaseManager類上面 的注釋。需要說明的是此算法的觸發時機和發起者。此算法可以由客戶端或者是主控服務器 發起,當客戶端在寫入一個數據包失敗後,會發起租約恢復。因為,一次寫入失敗,不論是 何種原因,很有可能就會導致流水線上有的服務器寫了,有的沒寫,從而造成不統一。而主 控服務器發起的時機,則是在占有租約的客戶端超出一定時限沒有續簽,這說明客戶端可能 掛了,在臨死前可能干過不利於數據塊統一的事情,作為監督者,主控服務器需要發起一場 恢復運動,確保一切正確。。。
3、負載均衡
負載的均衡,是分布式系統中一個永恆的話題,要讓大家各盡其力齊心干活,發揮各自獨 特的優勢,不能忙得忙死閒得閒死,影響戰斗力。而且,負載均衡也是一個復雜的問題,什 麼是均衡,是一個很模糊的概念。比如,在分布式文件系統中,總共三百個數據塊,平均分 配到十個數據服務器上,就算均衡了麼?其實不一定,因為每一個數據塊需要若干個備份, 各個備份的分布應該充分考慮到機架的位置,同一個機架的服務器間通信速度更快,而分布 在不同機架則更具有安全性,不會在一棵樹上吊死。。。
在這裡說的負載均衡,是寬泛意義上的均衡過程,主要涵蓋兩個階段的事務,一個是在任 務初始分配的時候盡可能合理分配,另一個是在事後時刻監督及時調整。。。
在HDFS中,ReplicationTargetChooser類,是負責實現為新分配的數據塊尋找婆家的。基 本上來說,數據塊的分配工作和備份的數量、申請的客戶端地址(也就是寫入者)、已注冊 的數據服務器位置,密切相關。其算法基本思路是只考量靜態位置信息,優先照顧寫入者的 速度,讓多份備份分配到不同的機架去。具體算法,自行參見源碼。此外,HDFS的Balancer 類,是為了實現動態的負載調整而存在的。Balancer類派生於Tool類,這說明,它是以一個 獨立的進程存在的,可以獨立的運行和配置。它運行有NamenodeProtocol和ClientProtocol 兩個協議,與主控服務器進行通信,獲取各個數據服務器的負載狀況,從而進行調整。主要 的調整其實就是一個操作,將一個數據塊從一個服務器搬遷到另一個服務器上。Balancer會 向相關的目標數據服務器發出一個DataTransferProtocol.OP_REPLACE_BLOCK消息,接收到這 個消息的數據服務器,會將數據塊寫入本地,成功後,通知主控服務器,刪除早先的那個數 據服務器上的同一塊數據塊。具體的算法請自行參考源碼。。。
4、垃圾回收
對於垃圾,大家應該耳熟能詳了,在分布式文件系統而言,沒有利用價值的數據塊備份, 就是垃圾。在現實生活中,我們提倡垃圾分類,為了更好的理解分布式文件系統的垃圾收集 ,搞個分類也是很有必要的。基本上,所有的垃圾都可以視為兩類,一類是由系統正常邏輯 產生的,比如某個文件被刪除了,所有相關的數據塊都淪為垃圾了,某個數據塊被負載均衡 器移動了,原始數據塊也不幸成了垃圾了。此類垃圾最大的特點,就是主控服務器是生成垃 圾的罪魁禍首,也就是說主控服務器完全了解有哪些垃圾需要處理。另外還有一類垃圾,是 由於系統的一些異常症狀產生的,比如某個數據服務器停機了一段,重啟之後發現其上的某 個數據塊已經在其他服務器上重新增加了此數據塊的備份,它上面的那個備份過期了失去價 值了,需要被當作垃圾來處理了。此類垃圾的特點恰恰相反,主控服務器無法直接了解到垃 圾狀況,需要曲線救國。。。
在HDFS中,第一類垃圾的判定自然很容易,在一些正常的邏輯中產生的垃圾,全部被塞進 了FSNamesystem的recentInvalidateSets這個Map中。而第二類垃圾的判定,則放在數據服務 器發送其數據塊信息來的過程中,經過與本地信息的比較,可以斷定,此數據服務器上有哪 些數據塊已經不幸淪為垃圾。同樣,這些垃圾也被塞到recentInvalidateSets中去。在與數 據服務器進行心跳交流的過程中,主控服務器會將它上面有哪些數據塊需要刪除,數據服務 器對這些數據塊的態度是,直接物理刪除。在GFS的論文中,對如何刪除一個數據塊有著不同 的理解,它覺著應該先緩存起來,過幾天沒人想恢復它了再刪除。在HDFS的文檔中,則明確 表示,在現行的應用場景中,沒有需要這個需求的地方,因此,直接刪除就完了。這說明, 理念是一切分歧的根本:)。。。
V. 總結
整個分布式文件系統,計算系統,數據庫系統的設計理念,基本是一脈相承的。三類服務 器、作為單點存在的核心控制服務器、基於日志的恢復機制、基於租約的保持聯系機制、等 等,在後續分布式計算系統和分布式數據庫中都可以看到類似的影子,在分布式文件系統這 裡,我詳述了這些內容,可能在後續就會默認知道而說的比較簡略了。而刨去這一些,分布 式文件系統中最大特點,就是文件塊的冗余存儲,它直接導致了較為復雜的寫入流程。當然 ,雖說分布式文件系統在分布式計算和數據庫中都有用到,但如果對其機理沒有興趣,只要 把它當成是一個可以在任何機器上使用的文件系統,就不會對其他上層建築的理解產生障礙 。