概要 :
隨著Intel Pentium III處理器的發布,給程序設計人員又帶來了許多新的特性。利用這些新特性,程序員可以為用戶創造出更好的產品. Pentium III和Pentium III Xeon(至強處理器)的許多新特性,可以使她能夠比Pentium II和Pentium II Xeon處理器有更快的運行速度,這些新特性包括一個處理器序列號(unique processor ID)和新增SSE處理器指令集,這些新的指令集就像Pentium II在經典Pentium的基礎上添加的MMX指令集.
1. Data Swizzling
要利用Pentium III處理器SSE指令的加速功能也是要有一定的代價的.因為SSE指令只能操作她定義的新數據類型(128位).如果應用程序使用自己的數據類型格式,那麼在進行SSE指令操作之前要將他轉換為這種新數據類型,操作完成之後又要把他轉換回來.
這種把一種數據格式轉換到另一種數據格式的操作就稱為"data swizzling".
這種轉換是需要時間和耗費處理器核心周期的.如果一個應用程序頻繁的進行數據格式轉換,處理器核心周期的浪費是很嚴重的.因此,這種數據格式的轉換是必須得到關注的.
1.1 數據組織
通常,3D應用程序將一個頂點保存在一個和他相配的數據結構中.當表達多個頂點時,應用程序使用這個結構的數組,也叫做AoS來表示.一個典型的操作是對表示頂點的x、y和z坐標進行的.下面的代碼就給出了這樣一個表示3D頂點的數據結構.如果要表示大量的這樣的頂點,就要用到這個結構的一個數組了,如圖9所示.
struct point {
float x, y, z;
};
...
point dataset[...];
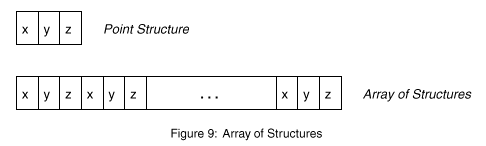
圖九 :結構數組
SSE的優點,就是可以同時對多個頂點的進行處理.這樣我們就必須要能夠方便的處理到表示多個頂點的數據(比如表示4個頂點x坐標的4個浮點數).這是可以實現的,我們可以把表示一個頂點的x、y和z三個坐標值分別集合在一起,然後應用程序對他們進行處理.要實現這些,應用程序必須重新組織數據到三個單獨的數組中,或者創建一個數組結構,結構中每個數組對應一個這樣的坐標值數組.這個數據結構也稱為SoA結構.(我是這樣理解的: 在不用SSE時是把表示一個頂點的三個坐標值組合到一個數據結構中,處理時一個值一個值的進行.而使用SSE以後,可以把所有點的各坐標值分別組合到3個數組中,處理時取出這樣一個數組的4個值同時執行).
下面的代碼就定義了這樣的一個數組結構,如圖10用圖表來表示的數組結構.
struct point {
float *x, *y, *z;
};
圖十: 數組結構
2. 內存問題
2.1 對齊
簡單的處理和使用新數據類型變量是沒有問題的.然而,一個推薦的做法是使用16字節邊界對齊來定義新數據類型變量.可以通過設置一個特定的編譯器參數或者在變量聲名時顯式的使用一個對齊標記來實現.
聲名變量時可以指定__declspec編譯器標記來強制變量使用16字節邊界對齊,就像下面的例子代碼所示.下面的變量myVar在使用這個對齊標記以後將被強制到16字節邊界對齊.但當在直接聲明這個新數據類型變量(也就是SSE定義的128位新數據類型)時就不需要指定這個對齊標記了,編譯器會在遇到這個新數據類型時自動按16字節對齊.下面是對齊標記的用法 :
__declspec(align(16)) float[4] myVar;
2.2 動態分配
由於新數據類型要求的16字節邊界對齊,使得在動態分配內存或者用指針來分配內存時會產生問題.
當使用指針訪問數組時,我們必須保證這個指針是16字節邊界對齊的.
在運行時分配內存可以使用malloc或者new命令.默認情況下這兩種方法分配的指針都不是16字節邊界對齊的.因此我們必須把這個分配得到的指針轉換到16字節對齊,或者使用_mm_malloc函數來分配內存.使用_mm_malloc函數分配的內存塊是按16字節邊界對齊的. 和malloc函數有一個free函數一樣,_mm_malloc函數也有一個對應的函數_mm_free.分配內存塊使用_mm_malloc函數而清除(free)內存塊用_mm_free函數.
2.3 自定義數據類型
指針必須是16字節邊界對齊的限制很麻煩,如果能夠不理睬這種限制就好了.
在使用128位新數據類型時,我們經常需要去訪問儲存在裡面的(4個)浮點數.在使用匯編語言時我們沒有許多的選擇.但在使用C或者C++和intrinsics庫時,我們總是用__mm128數據類型來表示這個128位的數據.使用這種數據類型(__mm128)時,一旦這個數值被設置以後,我們就不大可能直接去訪問存儲在裡面的單獨的浮點數了.有一個途徑是把存儲在裡面的浮點數轉移到一個浮點數數組裡面,修改他們的數值以後再把他們轉換回去.另一種途徑是把這個新的數據類型映射到一個浮點數數組的方法來訪問這些必要的元素.上面的第一種方法比較浪費時間而第二種方法如果使用不當則會發生問題.
定義一個自定義的數據類型能夠避免這個問題.這個自定義的數據類型用聯合(union)的方法把新數據類型(__mm128)和一個4個元素的浮點數數組關聯起來.下面給出代碼,現在可以用sse4來聲名新數據類型了.
union sse4 {
__m128 m;
float f[4];
};
使用上面定義的數據類型,聲明變量時不必使用對齊標記來強制16字節對齊,因為編譯器在遇到這個數據聯合裡面的__m128數據類型時會自動按16字節對齊來分配內存的.這個數據類型的一個好處就是可以直接訪問到存儲在裡面的單獨的浮點數.
2.4 偵測CPU
使用SSE指令集需要有Pentium III處理器,應用程序一個首要的任務就是要去檢查有沒有Pentium III芯片.這可以用cpuid的指令完成.
想要cpuid工作,需要把eax寄存器設置為特定的值.這裡我們只想得到CPU的ID,需要把eax寄存器置為1然後調用cpuid指令. 下面給出檢查PentiumIII處理器是否存在的代碼.要想使下面的代碼工作,還必須包含fvec.h頭文件.
BOOL CheckP3HW()
{
BOOL SSEHW = FALSE;
_asm {
// Move the number 1 into eax - this will move the
// feature bits into EDX when a CPUID is issued, that
// is, EDX will then hold the key to the cpuid
mov eax, 1
// Does this processor have SSE support?
cpuid
// Perform CPUID (puts processor feature info in EDX)
// Shift the bits in edx to the right by 26, thus bit 25
// (SSE bit) is now in CF bit in EFLAGS register.
shr edx,0x1A
// If CF is not set, jump over next instruction
jnc nocarryflag
// set the return value to 1 if the CF flag is set
mov [SSEHW], 1
nocarryflag:
}
return SSEHW;
}
SSE SDK還有一個Pentium III和SSE寄存器的異常模式.用下面的代碼也可以用來檢查是否有Pentium III處理器.要編譯下面的代碼,需要包含fvec.h頭文件.
// Checking for SSE emulation support
BOOL CheckP3Emu()
{
BOOL SSEEmu = TRUE;
Fvec32 pNormal = (1.0, 2.0, 3.0, 4.0);
Fvec32 pZero = 0.0;
// Checking for SSE HW emulation
__try {
_asm {
// Issue a move instruction that will cause exception
// w/out HW support emulation
movups xmm1, [pNormal]
// Issue a computational instruction that will cause
// exception w/out HW support emulation
divps xmm1, [pZero]
}
}
// If there''s an exception, set emulation variable to false
__except(EXCEPTION_EXECUTE_HANDLER){
SSEEmu = FALSE;
}
return SSEEmu;
}
3. 參考
For more details about the architecture of the Pentium III, refer [11], [12], [13] and [10].
For more information about Processor identification and CPUID, refer [15] and [7].
For more information about the Streaming SIMD Extensions, refer [19].
For more information about the programming issue, the software conventions and the software development strategies, refer [9], [16] and [17] respectively.
For more about application tuning for SSE and the VTune performance enhancement application, refer [1] and [8] respectively.
For more details about VTune and the Intel C/C++ Compiler, refer [3] and [2] respectively.
For additional information about the Pentium III processor and its capabilities, refer [14], [18], [20], [6], [5] and [4].
4. 附加示例
在這一節,我們將向你介紹幾個SSE指令集(Streaming SIMD Extensions)使用的例子.
4.1 數組操作
下面的例子中,我們創建了兩個數組,每個包含400個浮點數.將兩個數組的每個元素相乘,結果保存在第三個數組中.前面兩個數組作為操作數A和B,保存結果的數組為C.下面給出所有的代碼.
#include < FVEC.H >
#define ARRSIZE 400
__declspec(align(16)) float a[ARRSIZE], b[ARRSIZE], c[ARRSIZE];
4.1.1 Assembly Language
_asm{
push esi;
push edi;
mov edi, a;
mov esi, b;
mov edx, c;
mov ecx, 100;
loop:
movaps xmm0, [edi];
movups xmm1, [esi];
mulps xmm0, xmm1;
movups [edx], xmm0;
add edi, 16;
add esi, 16;
add edx, 16;
dec ecx;
jnz loop;
pop edi;
pop esi;
}
4.1.2 Intrinsics
__m128 m1, m2, m3;
for ( int i = 0; i < ARRSIZE; i += 4 )
{
m1= _mm_loadu_ps(a+i);
m2= _mm_loadu_ps(b+i);
m3= _mm_mul_ps(m1,m2);
_mm_storeu_ps(c+i, m3);
}
4.1.3 C++
F32vec4 f1, f2, f3;
for ( int i = 0; i < ARRSIZE; i +=4 )
{
loadu(f1, a+i);
loadu(f2, b+i);
f3 = f1 * f2;
storeu(c+i, f3);
}
4.2 矢量3D
下面的例子介紹3D矢量.矢量被封裝在一個類中.在下面類的函數裡面調用了intrinsics庫.
類聲明.
union sse4 {
__m128 m;
float f[4];
};
class sVector3 {
protected:
sse4 val;
public:
sVector3(float, float, float);
float& operator [](int);
sVector3& operator +=(const sVector3&);
float length() const;
friend float dot(const sVector3&, const sVector3&);
};
類實現.
sVector3::sVector3(float x, float y, float z) {
val.m = _mm_set_ps(0, z, y, x);
}
float& sgmVector3::operator [](int i) {
return val.f[i];
}
sVector3& sVector3::operator +=(const sVector3& v) {
val.m = _mm_add_ps(val.m, v.val.m);
return *this;
}
float sVector3::length() const {
sse4 m1;
m1.m = _mm_sqrt_ps(_mm_mul_ps(val.m, val.m));
return m1.f[0] + m1.f[1] + m1.f[2];
}
float dot(const sVector3& v1, const sVector3& v2) {
sVector3 v(v1);
v.val.m = _mm_mul_ps(v.val.m, v2.val.m);
return v.val.f[0] + v.val.f[1] + v.val.f[2];
}
4.3 4x4矩陣
下面的例子介紹一個4x4的矩陣.矩陣被封裝在一個類中.在下面類的函數裡面調用了intrinsics庫.
類聲明.
float const sEPSILON = 1.0e-10f;
union sse16 {
__m128 m[4];
float f[4][4];
};
class sMatrix4 {
protected:
sse16 val;
sse4 sFuzzy;
public:
sMatrix4(float*);
float& operator()(int, int);
sMatrix4& operator +=(const sMatrix4&);
bool operator ==(const sMatrix4&) const;
sVector4 operator *(const sVector4&) const;
private:
float RCD(const sMatrix4& B, int i, int j) const;
};
類實現.
sMatrix4::sMatrix4(float* fv) {
val.m[0] = _mm_set_ps(fv[3], fv[2], fv[1], fv[0]);
val.m[1] = _mm_set_ps(fv[7], fv[6], fv[5], fv[4]);
val.m[2] = _mm_set_ps(fv[11], fv[10], fv[9], fv[8]);
val.m[3] = _mm_set_ps(fv[15], fv[14], fv[13], fv[12]);
float f = sEPSILON;
sFuzzy.m = _mm_set_ps(f, f, f, f);
}
float& sMatrix4::operator()(int i, int j) {
return val.f[i][j];
}
sMatrix4& sMatrix4::operator +=(const sMatrix4& M) {
val.m[0] = _mm_add_ps(val.m[0], M.val.m[0]);
val.m[1] = _mm_add_ps(val.m[1], M.val.m[1]);
val.m[2] = _mm_add_ps(val.m[2], M.val.m[2]);
val.m[3] = _mm_add_ps(val.m[3], M.val.m[3]);
return *this;
}
bool sMatrix4::operator ==(const sMatrix4& M) const {
int res[4];
res[0] = res[1] = res[2] = res[3] = 0;
res[0] = _mm_movemask_ps(_mm_cmplt_ps(_mm_sub_ps(
_mm_max_ps(val.m[0], M.val.m[0]),
_mm_min_ps(val.m[0], M.val.m[0])), sFuzzy.m));
res[1] = _mm_movemask_ps(_mm_cmplt_ps(_mm_sub_ps(
_mm_max_ps(val.m[1], M.val.m[1]),
_mm_min_ps(val.m[1], M.val.m[1])), sFuzzy.m));
res[2] = _mm_movemask_ps(_mm_cmplt_ps(_mm_sub_ps(
_mm_max_ps(val.m[2], M.val.m[2]),
_mm_min_ps(val.m[2], M.val.m[2])), sFuzzy.m));
res[3] = _mm_movemask_ps(_mm_cmplt_ps(_mm_sub_ps(
_mm_max_ps(val.m[3], M.val.m[3]),
_mm_min_ps(val.m[3], M.val.m[3])), sFuzzy.m));
if ( (15 == res[0]) && (15 == res[1])
&& (15 == res[2]) && (15 == res[3]) )
return 1;
return 0;
}
sVector4 sMatrix4::operator *(const sVector4& v) const {
return sVector4(
val.f[0][0] * v[0] + val.f[0][1] * v[1]
+ val.f[0][2] * v[2] + val.f[0][3] * v[3],
val.f[1][0] * v[0] + val.f[1][1] * v[1]
+ val.f[1][2] * v[2] + val.f[1][3] * v[3],
val.f[2][0] * v[0] + val.f[2][1] * v[1]
+ val.f[2][2] * v[2] + val.f[2][3] * v[3],
val.f[3][0] * v[0] + val.f[3][1] * v[1]
+ val.f[3][2] * v[2] + val.f[3][3] * v[3]);
}
float sMatrix4::RCD(const sMatrix4& B, int i, int j) const {
return val.f[i][0] * B.val.f[0][j] + val.f[i][1] * B.val.f[1][j]
+ val.f[i][2] * B.val.f[2][j] + val.f[i][3] * B.val.f[3][j];
}
[參考書目]
[1] James Abel, Kumar Balasubramanian, Mike Bargeron, Tom Craver, and Mike Phlipot. Applications tuning for streaming simd extensions. Technical report, Intel Corporation, 1999.
[2] Intel Corporation. Intel C/C++ Compiler Web Site. http://developer.intel.com/vtune/icl.
[3] Intel Corporation. Vtune Performance Analyzer Web Site. http://developer.intel.com/vtune/performance.
[4] Intel Corpotation. Developer Relations Group Web Site. http://developer.intel.com/drg.
[5] Intel Corpotation. Intel Developer Web Site. http://developer.intel.com.
[6] Intel Corpotation. Web site. http://www.intel.com.
[7] Stephan Fischer, James Mi, and Albert Tang. Pentium iii processor serial number feature and applications. Technical report, Intel Corporation, 1999.
[8] Joe Wolf III. Programming methods for the pentium iii processor streaming simd extensions using the vtune performance enhancement environment. Technical report, Intel Corporation, 1999.
[9] Intel Corporation. Data Alignment and Programming Issues for the Streaming SIMD Extensions with the Intel C/C++ Compiler, 1999. App Note ap833.
[10] Intel Corporation. Intel Architecture Optimization Reference Manual, 1999.
[11] Intel Corporation. Intel Architecture Software Development Manual. Volume 1: Basic Architecture, 1999.
[12] Intel Corporation. Intel Architecture Software Development Manual. Volume 2: Instruction Set Reference, 1999.
[13] Intel Corporation. Intel Architecture Software Development Manual. Volume 3: Systems Programming Guide, 1999.
[14] Intel Corporation. Intel Pentium III Processor Performance Brief, 1999.
[15] Intel Corporation. Intel Processor Identification and CPUID Instruction, 1999. App Note Ap-485.
[16] Intel Corporation. Software Conventions for Streaming SIMD Extensions, 1999. App Note AP589.
[17] Intel Corporation. Software Development Strategies for Streaming SIMD Extensions, 1999. App Note AP814.
[18] Jagannath Keshavan and Vladimir Penkovski. Pentium iii processor implementation trade-offs. Technical report, Intel Corporation, 1999.
[19] Shreekant Thakkar and Tom Huff. Internet streaming simd extensions. Technical report, Intel Corporation, 1999.
[20] Paul Zagacki, Deep Duch, Emil Hsiech, Daniel Melaku, and Vladimir Pentkovski. Architecture of 3d software stack for peak pentium iii processor performance. Technical report, Intel Corporation, 1999.