首先是詞法分析器。我們仍然能夠使用《構造可配置語法分析器》前半部分的方法人腦畫出一張合適的DFA,這個時候我們可以手工來實現。用於詞法分析器的DFA只有兩種狀態,一種是普通狀態,另一種是終結狀態。所以我們可以很機械地將DFA用C++寫出來。
我們要為狀態編號。編號要連續,而且要從0開始,這樣的話C++的編譯器一般都會為switch-case的代碼生成一張表,用於快速跳轉。然後用下面的方法。
1:將輸入的指針Input復制出一個副本,叫Current;給出一個同類型的指針Last,將其賦值為NULL;使用一個變量Status來記錄當前的狀態。初始化狀態,一般為了方便我們把初始狀態編號成0。
2:做一個死循環不斷的計算新Status。對於某個Status我們總是能夠知道輸入什麼字符跳轉到什麼新的Status上去。不同的人寫出來的DFA可能會有所區別。我們首先判斷當前的Status是不是終結狀態,如果是的話將Current賦值給Last,然後繼續往下走。我們從Current指針拿出一個字符,然後計算新Status。如果Current不滿足要求那麼結束循環,如果Current滿足要求那麼改變Status並讓Current指向新的位置。
3:因為字符串總是有限的,所以這個循環總是會結束。結束了之後,我們檢查Last。如果Last仍然是NULL,那麼代表輸入的字符串是有問題的。如果不是,那麼我們所需要的一個記號就從Input開始到Last結束了。如果記號的類型有需要保留的話,那麼我們只需要添加一個新的代表類型的變量,在每一次修改Last的時候修改這個保存類型的變量就行了。因為一個終結狀態只能代表一種類型的結束(反過來不成立,一種類型可能有好幾個終結狀態)。
然後是語法分析。一般來說,使用《如何手寫語法分析器》中描述的方法實現一個語法分析器的話是很容易的,但是一個主要問題就是如果一門語言很復雜,特別是操作符特別多的話,這些函數寫起來會很亂,因此每一個文法產生式的處理函數的命名和注釋就變得相當重要了。為了簡化這件事情,我們還有另一種專門用來處理操作符的方法,而且是高度可配置的。為了簡化,我僅給出二元操作符和前綴操作符的處理方法。後綴操作符不常見,需要的話自己想辦法吧,在上一篇文章中的語法定義中並沒有出現後綴操作符。
在這種方法中,我們把重點放在不包含修改優先級的括號的表達式中。遇到一個用於修改優先級的括號的時候,只要遞歸一下就好了。現在,我們通過詞法分析,已經得到了很多記號,然後就使用以下的方法來生成一顆正確的語法樹:
1:我們需要定義兩個指針,第一個用於保存根節點,第二個用於保存當前節點。在分析的過程中,根節點會經常變化,當前節點也是。
2:取出一個單元。一個單元指的是一個用括號包括起來的完整的表達式、一個函數調用、一個常量或變量和僅由前綴操作符與單元組成的整體。舉個例子,1是單元,a是單元,function(param1,param2+param3)是單元,(a*b+c*d)是單元,-(a+b)也是單元。但是-a+b就不是單元了。單元內部可能有表達式,我們可以遞歸下去。取出單元以後,就把根節點和當前節點指向這個單元。
3:一個正確的表達式總是由單元和二元操作組成的,如果在以下的步驟中出錯的話,那麼可以直接確定輸入的表達式的語法不正確。我們做一個死循環一直到遇到右括號、逗號等這些結束表達式的記號為止,對於每一個輸入執行第4步。
4:取出一個二元操作符和一個單元。然後從當前節點往父節點找,一直到根節點或者父節點優先級比當前的二元操作符小的二元操作符為止。如果找到根節點,那麼整個根節點將作為二元操作符的左操作數,單元作為右操作數,根節點更新,當前節點指向單元。如果不是的話,將找到的節點(這個節點的父節點的優先級比自己小)從父節點脫離,整個節點作為操作符的左操作數,單元作為右操作數,然後用這個二元操作符接上父節點。
5:當3與4進行不下去的時候,我們就得到了一棵完整的表達式語法樹了。當然,如果中間出錯的話,我們應當輸出錯誤信息。這個時候要不要繼續往下走就自己看著辦吧,因為進行錯誤恢復的話,接下去的錯誤信息會很難看,就像VC++一樣。
我給一個例子來說明如何處理這些事情。現在我們要分析1+2*3+4。這個算法將會產生一個正確的語法樹”1”,然後修改為正確的語法樹”1+2”,然後修改為正確的語法樹”1+2*3”,最後產生完整的正確的語法樹。
第一步,產生一個單元的正確的語法樹:
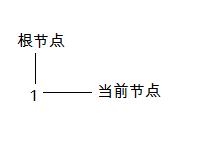
第二步,獲得一個二元操作符,並產生一個單元的語法樹”2”。因為當前節點往上就沒有了,所以執行4中的第一種情況:
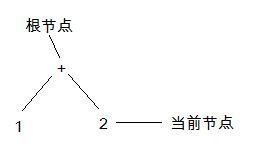
第三步,獲得操作符”*”和一個單元的語法樹”3”。因為2的父節點的優先級比”*”小,因此執行4的第二種情況:
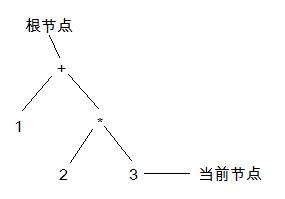
第四步,獲得操作符”+”和一個單元的語法樹”4”。這個時候3的父節點的優先級大於或等於”+”的優先級,因此一直往上找,一直到根節點。因為根節點的優先級仍然大於或等於”+”的優先級,因此再也上不了了,執行4的第一種情況:
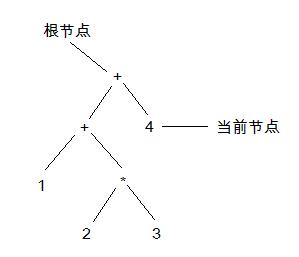
字符串結束了,中間也沒有出錯,代表輸入的表達式”1+2*3+4”是正確的,我們也得到了一棵正確的語法樹。
通過之前的文章與上述兩種簡單的方法的學習,我想分析一門語言的語法也就沒什麼困難的了。不過分析字符串是次要的,得到語法樹才是主要的。就算用了一種猥瑣的處理字符串的辦法得到了語法樹,那也沒關系,以後有時間再改就行了。現在我們要討論一下語法樹的數據結構問題。
在這裡我們需要大膽地使用虛函數。使用單一的一個class來表達整棵語法樹是不好的,因為我們的語法樹要表達unit、表達類型聲明、函數聲明、還有各種復雜的語句。類型是遞歸的,語句是遞歸的,表達式也是遞歸的。對於一組遞歸的結構,我們要定義一個幾類,並派生出各種子類來表達各種類型的結構。這樣做的好處是我們可以很方便地處理類型檢查、其它語義分析以及生成指令。多態在這裡是相當好用的,比省掉一點虛函數的空間(若干個同類型的對象只共享一張虛函數表)和一點調用的時候犧牲的速度好多了。我想用復雜的if或函數指針來代替多態估計也沒有多態快。
因為類型、表達式和語句的處理方式是類似的,因此我只為表達式建模。我們的表達式有四則運算、數組訪問以及函數調用。首先我們給出一個基類ExpBase:
class ExpBase
{
public:
TypeBase* GetType(vector<ErrorMessage>& Errors);
};
我們拿到了一個表達式之後,轉換成表達式樹,就會得到一個ExpBase了,這個時候我們進行類型檢查,只需要調用GetType就行了。各種不同的檢查由子類實現。
然後我們為運算符定義表達式節點:
enum BinOpType
{
Plus,
Minus,
Multiply,
Division,
……
};
enum SinOpType
{
Negative,
Not,
……
};
class ExpBinOp : public ExpBase
{
public:
ExpBase* ParamA;
ExpBase* ParamB;
BinOpType Operator;
};
class ExpSinOp : public ExpBase
{
public:
ExpBase* Param;
SinOpType Operator;
};
數組訪問可以加進二元操作符也可以不加,不過我個人還是傾向於不加的,因為後續的處理邏輯有很大的不同。
接下來是函數調用的表達式節點:
class ExpInvoke : public ExpBase
{
public:
ExpBase* Name;
vector<ExpBase*> Params;
};
所有的符合表達式就構造完了,但是我們仍然需要一個代表單一記號的表達式,譬如變量名啊數字等等。我們直接把一個記號放進去就好了,因為記號裡面有常量的類型信、也有變量名:
class ExpToken : public ExpBase
{
public:
Token* Content;
};
表達式的數據結構就構造完了,然後我們把剩下的類型信息與語句構造萬,給出單元結構以後就結束了。
鑒於實習期間較忙,自己的時間不多,完整的代碼我就不給出來了。要是大家願意的話可以去這裡看Vczh Free Script 2.0 beta的語法樹結構。雖然少了類型族,但也還是能看得。
下一篇文章講述語義分析以及符號表的事情。語法樹不僅要代表源代碼,還需要附帶額外的信息,譬如表達式的類型、重載的選擇等等。這些在語法分析的時候很難一起產生,所以我們借助多態來簡化這個任務。