腳本引擎的作用在於增強程序的可配置性。從游戲到管理系統都需要腳本,甚至連工業級產品的Office、3DS Max以及AutoCAD等都添加了屬於自己的腳本語言。DHTML的出現讓我們可以在網頁代碼中嵌入腳本語言,PHP和ASP等技術的出現讓我們可以將一個應用程序的界面換成網頁,而邏輯使用腳本語言編寫。現在腳本語言的種類繁多,Python的發展讓BOOST庫擁有了對Python的支持,Rails框架的出現壯大了Ruby的實力,LUA更是被大量應用在游戲開發中。Windows甚至提供了wscript以便讓我們能夠調用javascript和vbscript的代碼。
既然有了這麼多可供選擇的腳本引擎,為什麼我們仍然要開發自己的腳本引擎呢?首先,我們並不能保證現有的腳本引擎能夠滿足我們做出來的系統。因為我們所需要的腳本可能很簡單,用現有的腳本引擎比較浪費。或者我們的腳本復雜,但是功能比較“神奇”(譬如SQL)以至於沒有能夠滿足我們需要的腳本引擎。因為腳本並不一定是通用語言,腳本僅僅是為了滿足我們增強系統的可配置性而出現的。其次,腳本引擎足夠復雜,可以訓練我們的編程能力。在我們的業余時間裡面開發出來的程序並不完全是為了滿足某個應用的需要而產生的,有可能是我們為了自身的提高而進行的摸索。開發腳本引擎足以成為鍛煉的方法之一。
計算機語言作為一個計算的定義,在我們開發腳本引擎之前需要先進行了解。對於目前流行的若干種語言,我們可以抽象出一組正交屬性來描述他們。
一、命令式與描述式
一門語言是命令式或者描述式取決於這門語言是用來告訴計算機怎樣做還是做什麼的。舉個例子,SQL和Prolog是描述式語言,而C++、C#等則是命令式語言。我們在使用SQL的時候告訴服務器的是我們需要滿足什麼條件的數據項,而不是告訴服務器我們需要通過什麼計算來獲得自己所需要的數據項。描述式的語言的優點在於其可讀性好。C# 3.0為數據查詢加入了LINQ讓我們可以在C#中書寫類似SQL的代碼查詢數據。
另一個比較模糊的例子則是Haskell。Haskell很難區分是命令式語言還是描述式語言。因為從形式上來說我們告訴編譯器的是我們想做什麼而不是我們想怎麼做,但是Haskell給我們的工具的粒度太細以至於我們為了告訴編譯器做什麼的同時仍然需要考慮一個問題是如何被解決的。
二、按值計算與惰性計算
惰性計算的語言很少出現以至於可能很多人都不知道“原來語言可以是這個樣子的”。惰性計算的精神是不去執行沒用的代碼。什麼是沒用的代碼呢?只要是這段代碼的值不對外界產生任何影響,譬如沒有往屏幕、硬盤或者是其他什麼地方寫點什麼數據,就是沒有用的。當然,至於這段代碼中間做了些什麼事情那是不管的。
舉一個比較簡單的例子,假設現在有如下代碼:
function PrintAndReturn(Message,Result)
{
Print(Message);
return Result;
}
function DoSomething(BoolA,BoolB)
{
If(BoolA || BoolB) Print(“!”);
}
DoSomething(PrintAndReturn(“Hello”,true),PrintAndReturn(“World”,false));
DoSomething函數傳入兩個參數,都是布爾類型的。如果這兩個參數其中有一個是true的話那麼就往屏幕上打出一個感歎號。PrintAndReturn函數接受兩個參數,往屏幕上打出第一個參數,函數返回第二個參數。
對於一門按值計算的語言,也就是我們平常見到的那種,執行的結果是“HelloWorld!”。因為為了調用DoSomething我們需要首先獲得兩個布爾值。
對於一門惰性計算的語言,執行的結果是“Hello!”。因為DoSomething在對BoolA || BoolB進行求值的時候計算了BoolA,發現是true,於是BoolB這個參數就沒有用了,因此PrintAndReturn(“World”,false)也就不會執行了,導致“World”不會顯示在屏幕上。
當然,對於上面舉的這個例子來說,這種語言有著惰性計算的屬性並不合理。一門語言為了不具有二義性,在存在惰性計算的同時必須對自己的類型系統進行改造。關於這方面的資料可以查閱Haskell語言中Monad的原理。Haskell作為一門惰性計算的語言,在不關心求值順序的同時,仍然保證結果的一致性。上面這個例子,如果程序對||的求值是從右操作數開始的話,那麼輸出的結果就變成“HelloWorld!”了。惰性計算的好處在於可以在邏輯上表達無窮大的對象,而在實際的計算過程中並不需要將這個無窮大的對象一次性計算出來,而是需要哪裡算到哪裡。舉個例子:
function MakeArray(Index)
{
return [Index]++MakeArray(Index+1);
}
function Sum(Array,Count)
{
Result=0;
for i=0 to Count-1
Result+=Array[i];
return Result;
}
Print(Sum(MakeArray(1),10));
在這個例子中,[Index]代表一個只有一個元素的數組,其內容是Index,而++操作符將兩個數組接起來。於是MakeArray(1)就產生了一個無窮長的數組,其內容是[1,2,3,4,…]。Sum計算數組的前若干個數字的和。對於一門惰性計算的語言,這個例子將輸出55,因為我們需要的僅僅是前10個數字,因此MakeArray只需要遞歸10次就自動挺下來了。而對於一門按值計算的語言來說,將發生死循環而出現不可停機現象。
三、強類型、弱類型與無類型
一門語言是無類型當且僅當一個固定的符號的類型可以在運行時改變。譬如如下代碼:
TheVariable=1;
TheVariable=”I am a string!”;
第一行創建了一個int類型的TheVariable變量,而第二行則將TheVariable修改成了字符串類型。一門無類型語言的對象類型可以是數值、字符串、數組、類、閉包、函數指針等等的東西。
只要不是無類型的,那必然就是強類型或者弱類型的了。強類型與弱類型的分界線比較明顯。只要存在隱式類型轉換的語言則是弱類型的,譬如C語言能將int隱式轉換為double。不存在隱式轉換的語言也是存在的,譬如Haskell。在Haskell裡面不能創建一個實數類型的名字但是綁定一個整數的值上去。因為整數跟實數的類型是不同的,而且不存在隱式轉換。
四、函數與閉包
凡是支持閉包的語言必然是支持函數的,但是並不是所有支持函數的語言都支持閉包,而且也並不是所有的語言都有函數。Windows的批處理文件所能理解的語言就是不支持函數的語言的一個例子。
至於什麼是閉包呢?閉包就是可以保持函數執行的上下文的一種強大的函數指針。舉個例子:
function Add(a)
{
return function(b)
{
Return a+b;
}
}
Inc=Add(1);
Inc10=Add(10);
Print(Inc(5));
Print(Inc10(5));
這個例子將輸出6和15。執行Inc=Add(1);的時候,Add函數返回了一個新的函數,這個函數接受參數b並返回參數a和b相加的結果。返回的這個函數將參數a記了下來。所以Inc和Inc10在執行的時候,雖然執行的是同一個函數,但是這個函數所看到的a確是不同的。a的值的不同代表著Inc和Inc10執行函數的不同。這也就是閉包是可以保持函數執行的上下文的由來了。當然,一門不支持閉包的語言是不能允許上面這種寫法的。
這四種屬性是區分語言特征的重要屬性。至於一門語言是否支持面向對象的寫法或者支持元編程或者泛型之類的東西,並不是十分重要的特性,雖然我們使用起來的感覺非常不同。
那麼我們如何選擇我們所需要的特性呢?對於一個簡單的事務腳本來說,我們只需要非常簡單的特性諸如選擇結構和循環結構,和簡單的計算功能。計算功能可以支持表達式也可以不支持表達式。一門不支持表達式的語言看起來就像MASM支持的那種有宏的匯編語言。就像前些日子CSDN抄得很熱的概念DSL一樣,我們在設計一門腳本語言的時候,想的不應該是這門語言如何如何強大,而應該是這門語言應該如何更好地表達領域相關的信息。
下面這幅圖片顯示的是筆者在高中的時候開發的一款RPG的地圖編輯器。眾所周知,RPG是需要劇情的,因此編輯器需要在地板上或人物上設置陷阱引發腳本的執行。
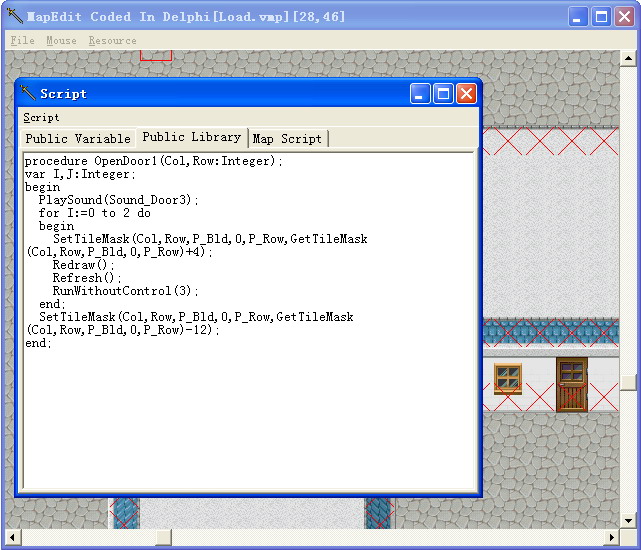
RPG由於劇情復雜,需要的控制方法也就很多,因此供給RPG使用的腳本至少應該支持選擇和循環等。而且有的時候需要使用腳本來完成某些動畫(譬如上圖中的開門腳本),因此腳本也就需要函數了。至於為什麼上面的腳本使用Pascal的語法僅僅是因為筆者當時Delphi用得比較多。這也是筆者第一次實現的一款腳本引擎。
那麼,我們如何選擇腳本語言的特性呢?我們要考慮一下系統的復雜度,因為腳本語言的特性跟我們想提供給腳本語言的庫是有很大關系的。
舉個例子,如果提供給腳本的庫經常需要調用到腳本的函數的話(比如GUI,比如可以給腳本用的類似YACC的東西等),那麼腳本最好具有閉包的特性,沒有的話至少也得有函數指針這種類型。如果提供給腳本的庫的大部分函數都可以接受很多種不同類型的對象的話,那麼腳本最好是無類型的。如果庫很龐大,大到不得不用命名空間和類來提供的話,那腳本無論如何都要有類的。
對於某些專用領域的語言,一般都采用類似自然語言(但是具有嚴格定義)的外觀來組織腳本,最好的例子就是SQL了。如果從語言的角度看,SQL的select是一個具有很多參數,而且大部分參數都具有缺省值的函數,而且大部分函數都是一些lambda表達式。因為lambda表達式出現得太多,因此就需要簡化lambda表達式的語法了。所以最終出現在我們面前的語法就是select中到處都可以寫有參數的表達式,而且這些參數來自於select的表名和重命名。
如果腳本本身需要非常快的話,那麼最好使用強類型或者弱類型。因為這兩種特性的語言的每一個符號都是有確定的類型的,虛擬機的開發不僅有很多方法,而且還有可能做成JIT(也就是編譯成機器碼)。在這種情況下,庫的供給就要非常注意了。因為在大部分情況下腳本都是在跟庫打交道的,所以交互的部分要詳細考慮。
如果腳本僅僅是用來做一些簡單的配置工作的話,那麼表達式可以全免,用命令的外觀設計語法。而且在大多數情況下連函數都可以免。這樣的話這門語言就剩下變量、分支和循環了,就跟Windows的批處理一樣。
最後一個需要提及但是大部分情況下不用管的屬性就是腳本的計算能力。這個計算能力說的不是計算的速度,而是解決的問題的范圍。這個屬性就是圖靈完備了。通俗地講,對於任何一個數學問題,如果只要C語言算得出來腳本語言都算得出來的話,那麼這門腳本語言就是圖靈完備的了。當然,因為C語言也是圖靈完備的,而且圖靈完備的計算能力在有限線程的計算機中是最高的,因此不存在一個數學問題,某種語言算得出來而C語言算不出來。那麼如何判斷一門語言是不是圖靈完備的呢?
簡單的來說,有數組的語言就是圖靈完備的,有閉包的語言也是圖靈完備的。如果數組也沒有,閉包也沒有,那麼有結構(C語言的struct和Pascal的record)和有指向結構的指針的語言也是圖靈完備的。因為閉包的內部結構也是一些保留環境的struct,因此只要能表達遞歸數據結構的語言都是圖靈完備的。
這一篇文章就先將到這裡了。下一篇文章將會講述如何實現最簡單的命令型腳本語言,再下一篇文章開始將會有幾篇文章講述如何實現一門有數組和函數的弱類型腳本語言,接著會對這門語言進行擴充。