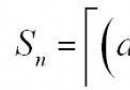隨機抽題是很多有關考試軟件經常會遇到的問題,設相關題庫中有n道題,要從中抽取m ( m<=n ) 道題,這要首先產生m個隨機數。在C語言中,一般的做法是:
int *intArray;這樣,就可以產生m個隨機數,方法很簡單,並且利用了當前時間作為隨機數的種子,盡量地避免了出現重復抽題。但仔細一分析,重復抽題並未完全避免,同時是否已抽題不影響今後的抽取,將導致各個試題被抽取的幾率不等。修正的方法有檢查新抽取的題是否重復,若重復則重抽,這樣做的方法很簡單,僅僅在上面的程序中加入判斷重復的語句,但各個試題被抽取的幾率仍然不等。怎樣辦呢?
int i;
time_t t;
intArray = malloc(m*sizeof(int));
/*time(&t)將獲取當前時間,srand把當前時間作為隨機數的種子*/
srand((unsigned) time(&t));
/*依次產生m個隨機數*/
for(i=0; i<m; i++)
intArray[i] = rand() %n;
……
free(intArray);
我們可以將1到n的n個數看成是n個人圍成一個圓形,先產生一個隨機數round,從1開始數(超過n有將是1),當數到round時,round號人退出(以後數到round時將跳過);接著又產生一個隨機數round1,從前面的round一直數到round1(依次往下數,若經過round時將跳過),…,如此下去,一直到m個題都被抽取。
此方法表面看來很難,要設一個有n個元的集合,已被數到的元素將被刪除,直到m個元素都被抽取為止,這樣要有一個n(一般n>>m)個元的集合,將消耗較多的時間和空間資源。有沒有更簡單的方法呢?
先分析“退出”的影響。round退出後,小於round的編號不變,大於round的編號減一;round1退出後,小於round1的編號不變,大於round1的編號又要減一;…,這樣就可以很簡單的分析出一個簡單的算法:依舊按前面所述的方法抽取隨機數roundk,將roundk按n求余數,再將roundk與round1, round2, …, roundk-1(此k-1個數已增序排列,roundk-1為前k-1次得到的隨機數最大者)相比較,然後進入比較程序,先與round1比較,若roundk>= round1,則roundk增一,再與round2比較,若roundk>= round2,則roundk再增一,…,這樣就可以很簡單地實現了無重復而且各個試題被抽取的幾率相同的隨機抽題算法。具體的做法是:int *intArray;上述做法的好處在於,沒有任何附加存儲空間,運算的復雜性大致上等於一個插入排序算法,但原始產生的題號順序已經“被忽略了”,添加一個有m個元素的附加數組,就可以保留原始產生的題號順序,例如intRandArray是一個有m個元素的附加數組,將①改為:
int i,j,k,temp;
time_t t;
intArray = malloc(m*sizeof(int));
srand((unsigned) time(&t));
/*依次產生m個隨機數*/
for(i=0; i<m; i++){
temp= rand() %n;
/*查找temp原先的“真實”編號*/
for(j=0; j<i; j++)
if(temp>= intArray[j])
temp++;
else{
/*temp應插在k位置處, 這樣數組intArray就實現了排序,同時得到了temp原先的編號*/
k=j-1;
break;
}
for(j=i-1;j>k;j--)
intArray [j+1]= intArray [j];
intArray [k] =temp; ①
/*以下根據題號產生題庫部分省略*/
……
}
free(intArray);intRandArray[i] =intArray [k]= temp;如此我們就可以已很小的時間與空間代價,實現了無重復而且各個試題被抽取的幾率相同的隨機抽題算法。但C語言中rand()一直飽受垢病,專業人員一直尋求更好的隨機數生成算法,這方面有很多參考資料,請讀者查閱,本文不再贅述。讀者可考慮將隨機數生成算法整合到本文的隨機抽題算法中,以獲得更好的隨機抽題算法。