譯者注:本文在網上已經有幾個譯本,但都不完整,所以我決定自己把它翻譯過來。雖然力求信、雅、達,但鑒於這是我的第一次翻譯經歷,不足之處敬請諒解並指出。
與傳統語言相比,C++的一項革命性創新就是它支持異常處理。傳統的錯誤處理方式經常滿足不了要求,而異常處理則是一個極好的替代解決方案。它將正常代碼和錯誤處理代碼清晰的劃分開來,程序變得非常干淨並且容易維護。本文討論了編譯器如何實現異常處理。我將假定你已經熟悉異常處理的語法和機制。本文還提供了一個用於VC++的異常處理庫,要用庫中的處理程序替換掉VC++提供的那個,你只需要調用下面這個函數:
install_my_handler();
之後,程序中的所有異常,從它們被拋出到堆棧展開(stack unwinding),再到調用catch塊,最後到程序恢復正常運行,都將由我的異常處理庫來管理。
與其它C++特性一樣,C++標准並沒有規定編譯器應該如何來實現異常處理。這意味著每一個編譯器的提供商都可以用它們認為恰當的方式來實現它。下面我會描述一下VC++是怎麼做的,但即使你使用其它的編譯器或操作系統①,本文也應該會是一篇很好的學習材料。VC++的實現方式是以windows系統的結構化異常處理(SEH)②為基礎的。
結構化異常處理—概述
在本文的討論中,我認為異常或者是被明確的拋出的,或者是由於除零溢出、空指針訪問等引起的。當它發生時會產生一個中斷,接下來控制權就會傳遞到操作系統的手中。操作系統將調用異常處理程序,檢查從異常發生位置開始的函數調用序列,進行堆棧展開和控制權轉移。Windows定義了結構“EXCEPTION_REGISTRATION”,使我們能夠向操作系統注冊自己的異常處理程序。
struct EXCEPTION_REGISTRATION
{
EXCEPTION_REGISTRATION* prev;
DWORD handler;
};
注冊時,只需要創建這樣一個結構,然後把它的地址放到FS段偏移0的位置上去就行了。下面這句匯編代碼演示了這一操作:
mov FS:[0], exc_regp
prev字段用於建立一個EXCEPTION_REGISTRATION結構的鏈表,每次注冊新的EXCEPTION_REGISTRATION時,我們都要把原來注冊的那個的地址存到prev中。
那麼,那個異常回調函數長什麼樣呢?在excpt.h中,windows定義了它的原形:
EXCEPTION_DISPOSITION (*handler)(
_EXCEPTION_RECORD *ExcRecord,
void* EstablisherFrame,
_CONTEXT *ContextRecord,
void* DispatcherContext);
不要管它的參數和返回值,我們先來看一個簡單的例子。下面的程序注冊了一個異常處理程序,然後通過除以零產生了一個異常。異常處理程序捕獲了它,打印了一條消息就完事大吉並退出了。
#include <iostream>
#include <windows.h>
using std::cout;
using std::endl;
struct EXCEPTION_REGISTRATION
{
EXCEPTION_REGISTRATION* prev;
DWORD handler;
};
EXCEPTION_DISPOSITION myHandler(
_EXCEPTION_RECORD *ExcRecord,
void * EstablisherFrame,
_CONTEXT *ContextRecord,
void * DispatcherContext)
{
cout << "In the exception handler" << endl;
cout << "Just a demo. exiting..." << endl;
exit(0);
return ExceptionContinueExecution; //不會運行到這
}
int g_div = 0;
void bar()
{
//初始化一個EXCEPTION_REGISTRATION結構
EXCEPTION_REGISTRATION reg, *preg = ®
reg.handler = (DWORD)myHandler;
//取得當前異常處理鏈的“頭”
DWORD prev;
_asm
{
mov EAX, FS:[0]
mov prev, EAX
}
reg.prev = (EXCEPTION_REGISTRATION*) prev;
//注冊!
_asm
{
mov EAX, preg
mov FS:[0], EAX
}
//產生一個異常
int j = 10 / g_div; //異常,除零溢出
}
int main()
{
bar();
return 0;
}
/*-------輸出-------------------
In the exception handler
Just a demo. exiting...
---------------------------------*/
注意EXCEPTION_REGISTRATION必須定義在棧上,並且必須位於比上一個結點更低的內存地址上,Windows對此有嚴格要求,達不到的話,它就會立刻終止進程。
函數和堆棧
堆棧是用來保存局部對象的連續內存區。更明確的說,每個函數都有一個相關的棧桢(stack frame)來保存它所有的局部對象和表達式計算過程中用到的臨時對象,至少理論上是這樣的。但現實中,編譯器經常會把一些對象放到寄存器中以便能以更快的速度訪問。堆棧是一個處理器(CPU)層次的概念,為了操縱它,處理器提供了一些專用的寄存器和指令。
圖1是一個典型的堆棧,它示出了函數foo調用bar,bar又調用widget時的情景。請注意堆棧是向下增長的,這意味著新壓入的項的地址低於原有項的地址。
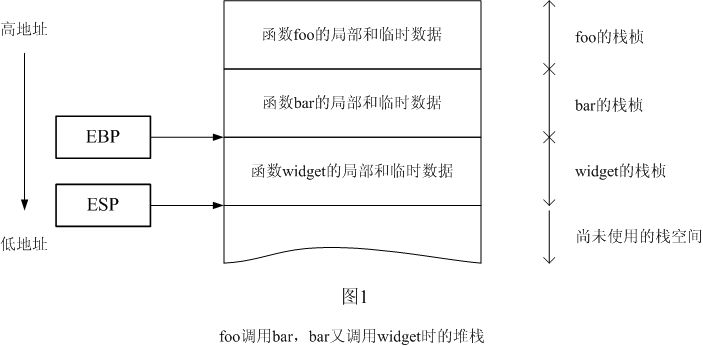
通常編譯器使用EBP寄存器來指示當前活動的棧桢。本例中,CPU正在運行widget,所以圖中的EBP指向了widget的棧桢。編譯器在編譯時將所有局部對象解析成相對於棧桢指針(EBP)的固定偏移,函數則通過棧桢指針來間接訪問局部對象。舉個例子,典型的,widget訪問它的局部變量時就是通過訪問棧桢指針以下的、有著確定位置的幾個字節來實現的,比如說EBP-24。
上圖中也畫出了ESP寄存器,它叫棧指針,指向棧的最後一項。在本例中,ESP指著widget的棧桢的末尾,這也是下一個棧桢(如果它被創建的話)的開始位置。
處理器支持兩種類型的棧操作:壓棧(push)和彈棧(pop)。比如,
pop EAX
的作用是從ESP所指的位置讀出4字節放到EAX寄存器中,並把ESP加上(記住,棧是向下增長的)4(在32位處理器上);類似的,
push EBP
的作用是把ESP減去4,然後將EBP的值放到ESP指向的位置中去。
編譯器編譯一個函數時,會在它的開頭添加一些代碼來為其創建並初始化棧桢,這些代碼被稱為序言(prologue);同樣,它也會在函數的結尾處放上代碼來清除棧桢,這些代碼叫做尾聲(epilogue)。
一般情況下,序言是這樣的:
Push EBP ; 把原來的棧桢指針保存到棧上
Mov EBP, ESP ; 激活新的棧桢
Sub ESP, 10 ; 減去一個數字,讓ESP指向棧桢的末尾
第一條指令把原來的棧桢指針EBP保存到棧上;第二條指令通過讓EBP指向主調函數的EBP的保存位置來激活被調函數的棧桢;第三條指令把ESP減去了一個數字,這樣ESP就指向了當前棧桢的末尾,而這個數字是函數要用到的所有局部對象和臨時對象的大小。編譯時,編譯器知道函數的所有局部對象的類型和“體積”,所以,它能很容易的計算出棧桢的大小。
尾聲所做的正好和序言相反,它必須把當前棧桢從棧上清除掉:
Mov ESP, EBP
Pop EBP ; 激活主調函數的棧桢
Ret ; 返回主調函數
它讓ESP指向主調函數的棧桢指針的保存位置(也就是被調函數的棧桢指針指向的位置),彈出EBP從而激活主調函數的棧桢,然後返回主調函數。
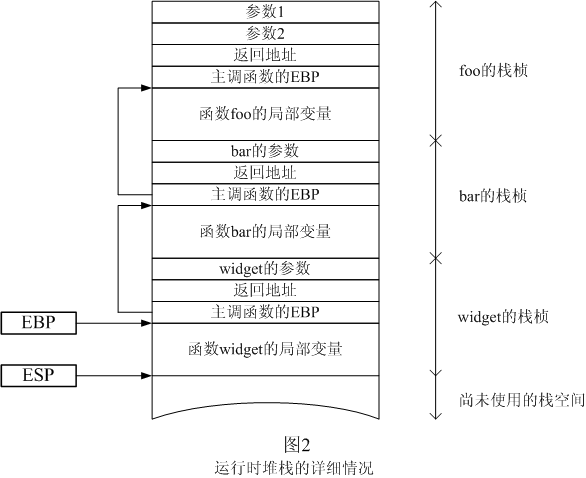
一旦CPU遇到返回指令,它就要做以下兩件事:把返回地址從棧中彈出,然後跳轉到那個地址去。返回地址是主調函數執行call指令調用被調函數時自動壓棧的。Call指令執行時,會先把緊隨在它後面的那條指令的地址(被調函數的返回地址)壓入棧中,然後跳轉到被調函數的開始位置。圖2更詳細的描繪了運行時的堆棧。如圖所示,主調函數把被調函數的參數也壓進了堆棧,所以參數也是棧桢的一部分。函數返回後,主調函數需要移除這些參數,它通過把所有參數的總體積加到ESP上來達到目的,而這個體積可以在編譯時知道:
Add ESP, args_size
當然,也可以把參數的總體積寫在被調函數的返回指令的後面,讓被調函數去移除參數,下面的指令就在返回主調函數前從棧中移去了24個字節:
Ret 24
取決於被調函數的調用約定(call convention),這兩種方式每次只能用一個。你還要注意的是每個線程都有自己獨立的堆棧。
C++和異常
回憶一下我在第一節中介紹的EXCEPTION_REGISTRATION結構,我們曾用它向操作系統注冊了發生異常時要被調用的回調函數。VC++也是這麼做的,不過它擴展了這個結構的語義,在它的後面添加了兩個新字段:
struct EXCEPTION_REGISTRATION
{
EXCEPTION_REGISTRATION* prev;
DWORD handler;
int id;
DWORD ebp;
};
VC++會為絕大部分函數③添加一個EXCEPTION_REGISTRATION類型的局部變量,它的最後一個字段(ebp)與棧桢指針指向的位置重疊。函數的序言創建這個結構並把它注冊給操作系統,尾聲則恢復主調函數的EXCEPTION_REGISTRATION。id字段的意義我將在下一節介紹。
VC++編譯函數時會為它生成兩部分數據:
a)異常回調函數
b)一個包含函數重要信息的數據結構,這些信息包括catch塊、這些塊的地址和這些塊所關心的異常的類型等等。我把這個結構稱為funcinfo,有關它的詳細討論也在下一節。
圖3是考慮了異常處理之後的運行時堆棧。widget的異常回調函數位於由FS:[0]指向的異常處理鏈的開始位置(這是由widget的序言設置的)。異常處理程序把widget的funcinfo結構的地址交給函數__CxxFrameHandler,__CxxFrameHandler會檢查這個結構看函數中有沒有catch塊對當前的異常感興趣。如果沒有的話,它就返回ExceptionContinueSearch給操作系統,於是操作系統會從異常處理鏈表中取得下一個結點,並調用它的異常處理程序(也就是調用當前函數的那個函數的異常處理程序)。
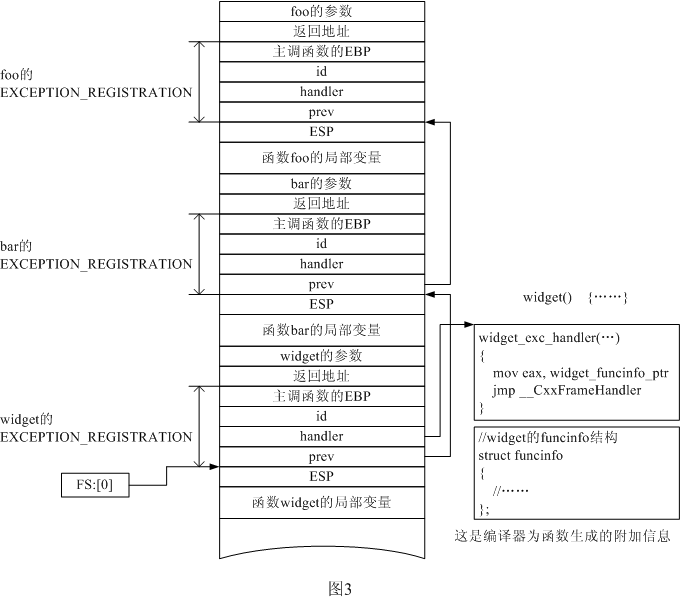
這一過程將一直進行下去——直到處理程序找到一個能處理當前異常的catch塊為止,這時它就不再返回操作系統了。但是在調用catch塊之前(由於有funcinfo結構,所以知道catch塊的入口,參見圖3),必須進行堆棧展開,也就是清理掉當前函數的棧桢下面的所有其他的棧桢。這個操作稍微有點復雜,因為:異常處理程序必須找到異常發生時生存在這些棧桢上的所有局部對象,並依次調用它們的析構函數。後面我將對此進行詳細介紹。
異常處理程序把這項工作委托給了各個棧桢自己的異常處理程序。從FS:[0]指向的異常處理鏈的第一個結點開始,它依次調用每個結點的處理程序,告訴它堆棧正在展開。與之相呼應,這些處理程序會調用每個局部對象的析構函數,然後返回。此過程一直進行到與異常處理程序自身相對應的那個結點為止。
由於catch塊是函數的一部分,所以它使用的也是函數的棧桢。因此,在調用catch塊之前,異常處理程序必須激活它所隸屬的函數的棧桢。
其次,每個catch塊都只接受一個參數,其類型是它希望捕獲的異常的類型。異常處理程序必須把異常對象本身或者是異常對象的引用拷貝到catch塊的棧桢上,編譯器在funcinfo中記錄了相關信息,處理程序根據這些信息就能知道到哪去拷貝異常對象了。
拷貝完異常並激活棧桢後,處理程序將調用catch塊。而catch塊將把控制權下一步要轉移到的地址返回來。請注意:雖然這時堆棧已經展開,棧桢也都被清除了,但它們占據的內存空間並沒有被覆蓋,所有的數據都還好好的待在棧上。這是因為異常處理程序仍在執行,象其他函數一樣,它也需要棧來存放自己的局部對象,而其棧桢就位於發生異常的那個函數的棧桢的下面。catch塊返回以後,異常處理程序需要“殺掉”異常對象。此後,它讓ESP指向目標函數(控制權要轉移到的那個函數)的棧桢的末尾——這樣就把(包括它自己的在內的)所有棧桢都刪除了,然後再跳轉到catch塊返回的那個地址去,就勝利的完成整個異常處理任務了。但它怎麼知道目標函數的棧桢末尾在哪呢?事實上它沒法知道,所以編譯器把這個地址保存到了棧桢上(由前言來完成),如圖3所示,棧桢指針EBP下面第16個字節就是。
當然,catch塊也可能拋出新異常,或者是將原來的異常重新拋出。處理程序必須對此有所准備。如果是拋出新異常,它必須殺掉原來的那個;而如果是重新拋出原來的異常,它必須能繼續傳播(propagate)這個異常。
這裡我要特別強調一點:由於每個線程有自己獨立的堆棧,所以每個線程也都有自己獨立的、由FS:[0]指向的EXCEPTION_REGISTRATION鏈。
C++和異常—2
圖4是funcinfo的布局,注意這裡的字段名可能與VC++編譯器實際使用的不完全一致,而且我也只給出了和我們的討論相關的字段。堆棧展開表(unwind table)的結構留到下節再討論。
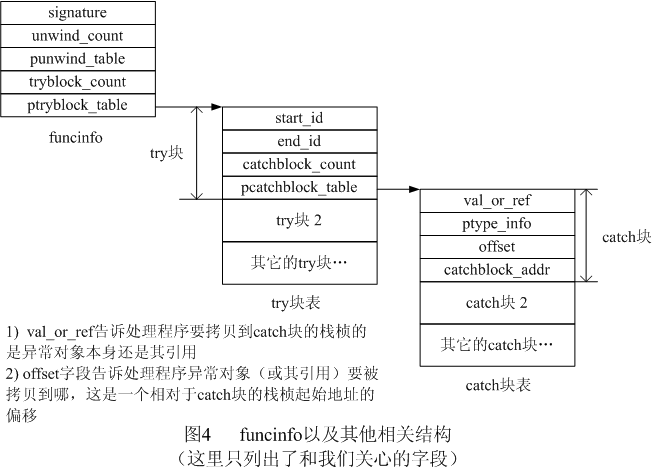
異常處理程序在函數中查找catch塊時,它首先要判斷異常發生的位置是否在當前函數(發生異常的那個函數)的一個try塊中。是則查找與此try塊相關的catch塊表,否則直接返回。
先來看看它怎樣找try塊。編譯時,編譯器給每個try塊都分配了start id和end id。通過funcinfo結構,異常處理程序可以訪問這兩個id,見圖4。編譯器為函數中的每個try塊都生成了相關的數據結構。
上一節中,我說過VC++給EXCEPTION_REGISTRATION結構加上了一個id字段。回憶一下圖3,這個結構位於函數的棧桢上。異常發生時,處理程序讀出這個值,看它是否在try塊的兩個id確定的區間[start id,end id]中。是的話,異常就發生在這個try塊中;否則繼續查看try塊表中的下一個try塊。
誰負責更新id的值,它的值又應該是什麼呢?原來,編譯器會在函數的多個位置安插代碼來更新id的值,以反應程序的實時運行狀態。比如說,編譯器會在進入try塊的地方加上一條語句,把try塊的start id寫到棧桢上。
找到try塊後,處理程序就遍歷與其關聯的catch塊表,看是否有對當前異常感興趣的catch塊。在try塊發生嵌套時,異常將既源於內層try塊,也源於外層try塊。這種情況下,處理程序應該按先內後外的順序查找catch塊。但它其實沒必要關心這些,因為,在try塊表中,VC++總是把內層try塊放在外層try塊的前面。
異常處理程序還有一個難題就是“如何根據catch塊的相關數據結構判斷這個catch塊是否願意處理當前異常”。這是通過比較異常的類型和catch塊的參數的類型來完成的。例如下面這個程序:
void foo()
{
try
{
throw E();
}
catch(H)
{
//.
}
}
如果H和E的類型完全相同的話,catch塊就要捕獲這個異常。這意味著處理程序必須在運行時進行類型比較,對C等語言來說,這是不可能的,因為它們無法在運行時得到對象的類型。C++則不同,它有了運行時類型識別(runtime type identification,RTTI),並提供了運行時類型比較的標准方法。C++在標准頭文件中定義了type_info類,它能在運行時代表一個類型。catch塊數據結構的第二個字段(ptype_info,見圖4)是一個指向type_info結構的指針,它在運行時就代表catch塊的參數類型。type_info也重載了==運算符,能夠指出兩種類型是否完全相同。這樣,異常處理程序只要比較(調用==運算符)catch塊參數的type_info(可以通過catch塊的相關數據結構來訪問)和異常的type_info是否相同,就能知道catch塊是不是願意捕獲當前異常了。
catch塊的參數類型可以通過funcinfo結構得到,但異常的type_info從哪來呢?當編譯器碰到
throw E();
這條語句時,它會為異常生成一個excpt_info結構,如圖5所示。還是要提醒你注意這裡用的名字可能與VC++使用的不一致,而且仍然只有與我們的討論相關的字段。從圖中可以看出,異常的type_info可以通過excpt_info結構得到。由於異常處理程序需要拷貝異常對象(在調用catch塊之前),也需要消除掉它(在調用catch塊之後),所以編譯器在這個結構中同時提供了異常的拷貝構造函數、大小和析構函數的信息。
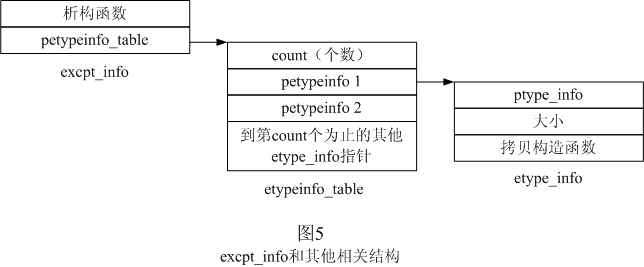
在catch塊的參數是基類,而異常是派生類時,異常處理程序也應該調用catch塊。然而,這種情況下,比較它們的type_info絕對是不相等,因為它們本來就不是相同的類型。而且,type_info類也沒有提供任何其他函數或運算符來指出一個類是另一個類的基類。但異常處理程序還必須得去調用catch塊!為了解決這個問題,編譯器只能為處理程序提供更多的信息:如果異常是派生類,那麼etypeinfo_table(通過excpt_info訪問)將包含多個指向etype_info(擴展了type_info,這個名字是我啟的)的指針,它們分別指向了各個基類的etype_info。這樣,處理程序就可以把catch塊的參數和所有這些type_info比較,只要有一個相同,就調用catch塊。
在結束這一部分之前,還有最後一個問題:異常處理程序是怎麼知道異常和excpt_info結構的?下面我就要回答這個問題。
VC++會把throw語句翻譯成下面的樣子:
//throw E(); //編譯器會為E生成excpt_info結構
E e = E(); //在棧上創建異常
_CxxThrowException(&e, E_EXCPT_INFO_ADDR);
__CxxThrowException會把控制權連帶它的兩個參數都交給操作系統(控制權轉移是通過軟件中斷實現的,請參見RaiseException)。而操作系統,在為調用異常回調函數做准備時,會把這兩個參數打包到一個_EXCEPTION_RECORD結構中。接著,它從EXCEPTION_REGISTRATION鏈表的頭結點(由FS:[0]指向)開始,依次調用各節點的異常處理程序。而且,指向當前EXCEPTION_REGISTRATION結構的指針也會作為異常處理程序的第二個參數出現。前面已經說過,VC++中的每個函數都在棧上創建並注冊了EXCEPTION_REGISTRATION結構。所以傳遞這個參數可以讓處理程序知道很多重要信息,比如說:EXCEPTION_REGISTRATION的id字段(用於查找catch塊)、函數的棧桢(用於清理棧桢)和EXCEPTION_REGISTRATION結點在異常鏈表中的位置(用於堆棧展開)等。第一個參數是指向_EXCEPTION_RECORD結構的指針,通過它可以找到異常和它的excpt_info結構。下面是excpt.h中定義的異常回調函數的原型:
EXCEPTION_DISPOSITION (*handler)(
_EXCEPTION_RECORD* ExcRecord,
void* EstablisherFrame,
_CONTEXT *ContextRecord,
void* DispatcherContext);
後兩個參數和我們的討論關系不大。函數的返回值是一個枚舉類型(也在excpt.h中定義),我前面已經說過,如果處理程序找不到catch塊,它就會向系統返回ExceptionContinueSearch,對本文而言,我們只要知道這一個返回值就行了。_EXCEPTION_RECORD結構是在winnt.h中定義的:
struct _EXCEPTION_RECORD
{
DWORD ExceptionCode;
DWORD ExceptionFlags;
_EXCEPTION_RECORD* ExcRecord;
PVOID ExceptionAddress;
DWORD NumberParameters;
DWORD ExceptionInformation[15];
}EXCEPTION_RECORD;
ExceptionInformation數組中元素的個數和類型取決於ExceptionCode字段。如果是C++異常(異常代碼是0xe06d7363,源於throw語句),那麼數組中將包含指向異常和excpt_info結構的指針;如果是其他異常,那數組中基本上就不會有什麼內容,這些異常包括除零溢出、訪問違例等,你可以在winnt.h中找到它們的異常代碼。
ExceptionFlags字段用於告訴異常處理程序應該采取什麼操作。如果它是EH_UNWINDING(見Except.inc),那是說堆棧正在展開,這時,處理程序要清理棧桢,然後返回。否則處理程序應該在函數中查找catch塊並調用它。清理棧桢意味著必須找到異常發生時生存在棧桢上的所有局部對象,並調用其析構函數,下一節我們將就此進行詳細討論。
清理棧桢
C++標准明確指出:堆棧展開工作必須調用異常發生時所有生存的局部對象的析構函數。如下面的代碼:
int g_i = 0;
void foo()
{
T o1, o2;
{
T o3;
}
10/g_i; //這裡會發生異常
T o4;
//...
}
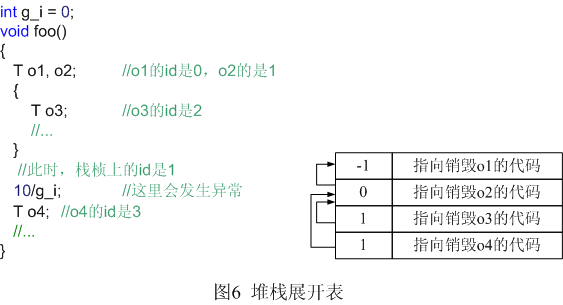
foo有o1、o2、o3、o4四個局部對象,但異常發生時,o3已經“死亡”,o4還未“出生”,所以異常處理程序應該只調用o1和o2的析構函數。
前面已經說過,編譯器會在函數的很多地方安插代碼來記錄當前的運行狀態。實際上,編譯器在函數中設置了一些關鍵區域,並為它們分配了id,進入關鍵區域時要記錄它的id,退出時恢復前一個id。try塊就是一個例子,其id就是start id。所以,在try塊的入口,編譯器會把它的start id記到棧桢上去。局部對象從創建到銷毀也確定了一個關鍵區域,或者,換句話說,編譯器給每個局部對象分配了唯一的id,例如下面的程序:
void foo()
{
T t1;
//.
}
編譯器會在t1的定義後面(也就是t1創建以後),把它的id寫到棧桢上:
void foo()
{
T t1;
_id = t1_id; //編譯器插入的語句
//.
}
上面的_id是編譯器偷偷創建的局部變量,它的位置與EXCEPTION_REGISTRATION的id字段重疊。類似的,在調用對象的析構函數前,編譯器會恢復前一個關鍵區域的id。
清理棧桢時,異常處理程序讀出id的值(通過EXCEPTION_REGISTRATION結構的id字段或棧桢指針EBP下面的4個字節來訪問)。這個id可以表明,函數在運行到與它相關聯的那個點之前沒有發生異常。所有在這一點之前定義的對象都已初始化,應該調用這些對象中的一部分或全部對象的析構函數。請注意某些對象是屬於子塊(如前面代碼中的o3)的,發生異常時可能已經銷毀了,不應該調用它們的析構函數。
編譯器還為函數生成了另一個數據結構——堆棧展開表(unwindtable,我啟的名字),它是一個unwind結構的數組,可通過funcinfo來訪問,如圖4所示。函數的每個關鍵區域都有一個unwind結構,這些結構在展開表中出現的次序和它們所對應的區域在函數中的出現次序完全相同。一般unwind結構也會關聯一個對象(別忘了,每個對象的定義都開辟了關鍵區域,並有id與其對應),它裡面有如何銷毀這個對象的信息。每當編譯器碰到對象定義,它就生成一小段代碼,這段代碼知道對象在棧桢上的地址(就是它相對於棧桢指針的偏移),並能銷毀它。unwind結構中有一個字段用於保存這段代碼的入口地址:
typedef void (*CLEANUP_FUNC)();
struct unwind
{
int prev;
CLEANUP_FUNC cf;
};
try塊對應的unwind結構的cf字段是空值NULL,因為沒有與它對應的對象,所以也沒有東西需要它去銷毀。通過prev字段,這些unwind結構也形成了一個鏈表。異常處理程序清理棧桢時,會讀取當前的id值,以它為索引取得展開表中對應的項,並調用其第二個字段指向的清理代碼,這樣,那個與之關聯的對象就被銷毀了。然後,處理程序將以當前unwind結構的prev字段為索引,繼續在展開表中找下一個unwind結構,調用其清理代碼。這一過程將一直重復,直到鏈表的結尾(prev的值是-1)。圖6畫出了本節開始時提到的那段代碼的堆棧展開表。
現在把new運算符也加進來,對於下面的代碼:
T* p = new T();
系統會首先為T分配內存,然後調用它的構造函數。所以,如果構造函數拋出了異常,系統就必須釋放這些內存。因此,動態創建那些擁有“有為的構造函數”的類型時,VC++也為new運算符分配了id,並且堆棧展開表中也有與其對應的項,其清理代碼將釋放分配的內存空間。調用構造函數前,編譯器把new運算符的id存到EXCEPTION_REGISTRATION結構中,構造函數順利返回後,它再把id恢復成原來的值。
更進一步說,構造函數拋出異常時,對象可能剛剛構造了一部分,如果它有子成員對象或子基類對象,並且發生異常時它們中的一部分已經構造完成的話,就必須調用這些對象的析構函數。和普通函數一樣,編譯器也給構造函數生成了相關的數據來幫助完成這個任務。
展開堆棧時,異常處理程序調用的是用戶定義的析構函數,這一點你必須注意,因為它也有可能拋出異常!C++標准規定堆棧展開過程中,析構函數不能拋出異常,否則系統將調用std::terminate。
實現
本節我們討論其他三個有待詳細解釋的問題:
a)如何安裝異常處理程序
b)catch塊重新拋出異常或拋出新異常時應該如何處理
c)如何對所有線程提供異常處理支持
隨同本文,有一個演示項目,查看其中的readme.txt文件可以得到一些編譯方面的幫助①。
第一項任務是安裝異常處理程序,也就是把VC++的處理程序替換掉。從前面的討論中,我們已經清楚地知道__CxxFrameHandler函數是VC++所有異常處理工作的入口。編譯器為每個函數都生成一段代碼,它們在發生異常時被調用,把相應的funcinfo結構的指針交給__CxxFrameHandler。
install_my_handler()函數會改寫__CxxFrameHandler的入口處的代碼,讓程序跳轉到my_exc_handler()函數。不過,__CxxFrameHandler位於只讀的內存頁,對它的任何寫操作都會導致訪問違例,所以必須首先用VirtualProtectEx把該內存頁的保護方式改成可讀寫,等改寫完畢後,再改回只讀。寫入的數據是一個jmp_instr結構。
//install_my_handler.cpp
#include <windows.h>
#include "install_my_handler.h"
//C++默認的異常處理程序
extern "C"
EXCEPTION_DISPOSITION __CxxFrameHandler(
struct _EXCEPTION_RECORD* ExceptionRecord,
void* EstablisherFrame,
struct _CONTEXT* ContextRecord,
void* DispatcherContext
);
namespace
{
char cpp_handler_instructions[5];
bool saved_handler_instructions = false;
}
namespace my_handler
{
//我的異常處理程序 EXCEPTION_DISPOSITION
my_exc_handler(
struct _EXCEPTION_RECORD *ExceptionRecord,
void * EstablisherFrame,
struct _CONTEXT *ContextRecord,
void * DispatcherContext
) throw();
#pragma pack(push, 1)
struct jmp_instr
{
unsigned char jmp;
DWORD offset;
};
#pragma pack(pop)
bool WriteMemory(void* loc, void* buffer, int size)
{
HANDLE hProcess = GetCurrentProcess();
//把包含內存范圍[loc,loc+size]的頁面的保護方式改成可讀寫
DWORD old_protection;
BOOL ret = VirtualProtectEx(hProcess, loc, size, PAGE_READWRITE, &old_protection);
if(ret == FALSE)
return false;
ret = WriteProcessMemory(hProcess, loc, buffer, size, NULL);
//恢復原來的保護方式
DWORD o2;
VirtualProtectEx(hProcess, loc, size, old_protection, &o2);
return (ret == TRUE);
}
bool ReadMemory(void* loc, void* buffer, DWORD size)
{
HANDLE hProcess = GetCurrentProcess();
DWORD bytes_read = 0;
BOOL ret = ReadProcessMemory(hProcess, loc, buffer, size, &bytes_read);
return (ret == TRUE && bytes_read == size);
}
bool install_my_handler()
{
void* my_hdlr = my_exc_handler; void* cpp_hdlr = __CxxFrameHandler;
jmp_instr jmp_my_hdlr;
jmp_my_hdlr.jmp = 0xE9;
//從__CxxFrameHandler+5開始計算偏移,因為jmp指令長5字節
jmp_my_hdlr.offset = reinterpret_cast(my_hdlr) - (reinterpret_cast(cpp_hdlr) + 5);
if(!saved_handler_instructions)
{
if(!ReadMemory(cpp_hdlr, cpp_handler_instructions, sizeof(cpp_handler_instructions)))
return false;
saved_handler_instructions = true;
}
return WriteMemory(cpp_hdlr, &jmp_my_hdlr, sizeof(jmp_my_hdlr));
}
bool restore_cpp_handler()
{
if(!saved_handler_instructions)
return false;
else
{
void* loc = __CxxFrameHandler;
return WriteMemory(loc, cpp_handler_instructions, sizeof(cpp_handler_instructions));
}
}
}
編譯指令#pragma pack(push, 1)告訴編譯器不要在jmp_instr結構中填充任何用於對齊的空間。沒有這條指令,jmp_instr的大小將是8字節,而我們需要它是5字節。
現在重新回到異常處理這個主題上來。調用catch塊時,它可能重新拋出異常或拋出新異常。前一種情況下,異常處理程序必須繼續傳播(propagate)當前異常;後一種情況下,它需要在繼續之前銷毀原來的異常。此時,處理程序要面對兩個難題:“如何知道異常是源於catch塊還是程序的其他部分”和“如何跟蹤原來的異常”。我的解決方法是:在調用catch塊之前,把當前異常保存在exception_storage對象中,並注冊一個專用於catch塊的異常處理程序——catch_block_protector。調用get_exception_storage()函數,就能得到exception_storage對象:
exception_storage* p = get_exception_storage();
p->set(pexc, pexc_info);
注冊 catch_block_protector;
調用catch塊; //....
這樣,當catch塊(重新)拋出異常時,程序將會執行catch_block_protector。如果是拋出了新異常,這個函數可以從exception_storage對象中分離出前一個異常並銷毀它;如果是重新拋出原來的異常(可以通過ExceptionInformation數組的前兩個元素知道是新異常還是舊異常,後一種情況下著兩個元素都是0,參見下面的代碼),就通過拷貝ExceptionInformation數組來繼續傳播它。下面的代碼就是catch_block_protector()函數的實現。
//-------------------------------------------------------------------
// 如果這個處理程序被調用了,可以斷定是catch塊(重新)拋出了異常。
// 異常處理程序(my_handler)在調用catch塊之前注冊了它。其任務是判斷
// catch塊拋出了新異常還是重新拋出了原來的異常,並采取相應的操作。
// 在前一種情況下,它需要銷毀傳遞給catch塊的前一個異常對象;在後一種
// 情況下,它必須找到原來的異常並將其保存到ExceptionRecord中供異常
// 處理程序使用。
//-------------------------------------------------------------------
EXCEPTION_DISPOSITION catch_block_protector(
_EXCEPTION_RECORD* ExceptionRecord,
void* EstablisherFrame,
struct _CONTEXT *ContextRecord,
void* DispatcherContext
) throw ()
{
EXCEPTION_REGISTRATION *pFrame;
pFrame= reinterpret_cast<EXCEPTION_REGISTRATION*>(EstablisherFrame);
if(!(ExceptionRecord->ExceptionFlags & (_EXCEPTION_UNWINDING | _EXCEPTION_EXIT_UNWIND)))
{
void *pcur_exc = 0, *pprev_exc = 0;
const excpt_info *pexc_info = 0, *pprev_excinfo = 0;
exception_storage* p = get_exception_storage();
pprev_exc = p->get_exception();
pprev_excinfo = p->get_exception_info();
p->set(0, 0);
bool cpp_exc = ExceptionRecord->ExceptionCode == MS_CPP_EXC;
get_exception(ExceptionRecord, &pcur_exc);
get_excpt_info(ExceptionRecord, &pexc_info);
if(cpp_exc && 0 == pcur_exc && 0 == pexc_info) //重新拋出
{
ExceptionRecord->ExceptionInformation[1] = reinterpret_cast<DWORD>(pprev_exc);
ExceptionRecord->ExceptionInformation[2] = reinterpret_cast<DWORD>(pprev_excinfo);
}
else
{
exception_helper::destroy(pprev_exc, pprev_excinfo);
}
}
return ExceptionContinueSearch;
}
下面是get_exception_storage()函數的一個實現:
exception_storage* get_exception_storage()
{
static exception_storage es;
return &es;
}
在單線程程序中,這是一個完美的實現。但在多線程中,這就是個災難了,想象一下多個線程訪問它,並把異常對象保存在裡面的情景吧。由於每個線程都有自己的堆棧和異常處理鏈,我們需要一個線程安全的get_exception_storage實現:每個線程都有自己單獨的exception_storage,它在線程啟動時被創建,並在結束時被銷毀。Windows提供的線程局部存儲(thread local storage,TLS)可以滿足這個要求,它能讓每個線程通過一個全局鍵值來訪問為這個線程所私有的對象副本,這是通過TlsGetValue()和TlsSetValue這兩個API來完成的。
Excptstorage.cpp中給出了get_exception_storage()函數的實現。它會被編譯成動態鏈接庫,因為我們可以籍此知道線程的創建和退出——系統在這兩種情況下都會調用所有(當前進程加載的)dll的DllMain()函數,這讓我們有機會創建特定於線程的數據,也就是exception_storage對象。
//excptstorage.cpp
#include "excptstorage.h"
#include <windows.h>
namespace
{
DWORD dwstorage;
}
namespace my_handler
{
__declspec(dllexport) exception_storage* get_exception_storage() throw ()
{
void * p = TlsGetValue(dwstorage);
return reinterpret_cast <exception_storage*>(p);
}
}
BOOL APIENTRY DllMain( HANDLE hModule, DWORD ul_reason_for_call, LPVOID lpReserved )
{
using my_handler::exception_storage;
exception_storage *p;
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
//主線程(第一個線程)不會收到DLL_THREAD_ATTACH通知,所以,
//與其相關的操作也放在這了
dwstorage = TlsAlloc();
if (-1 == dwstorage)
return FALSE;
p = new exception_storage();
TlsSetValue(dwstorage, p);
break ;
case DLL_THREAD_ATTACH:
p = new exception_storage();
TlsSetValue(dwstorage, p);
break;
case DLL_THREAD_DETACH:
p = my_handler::get_exception_storage();
delete p;
break ;
case DLL_PROCESS_DETACH:
p = my_handler::get_exception_storage();
delete p;
break ;
}
return TRUE;
}
結論
綜上所述,異常處理是在操作系統的協助下,由C++編譯器和運行時異常處理庫共同完成的。
注釋和參考資料
① 本文寫作期間,微軟發布了Visual Studio 7.0。本文的異常處理庫主要是在運行於奔騰處理器的windows2000上使用VC++6.0編譯和測試的。但我也在VC++5.0和VC++7.0 beta版上測試過。6.0和7.0之間有一些差別,6.0先把異常(或其引用)拷貝到catch塊的棧桢上,然後在調用catch塊之前進行堆棧展開;7.0則先進行堆棧展開。在這方面,我的庫代碼的行為比較接近6.0版。
② 參見Matt Pietrek發表在MSDN上的文章《structured exception handling》。
③ 如果一個函數既不含try塊,也沒有定義任何具有“有為的析構函數”的對象,那麼編譯器將不為它生成用於異常處理的數據。