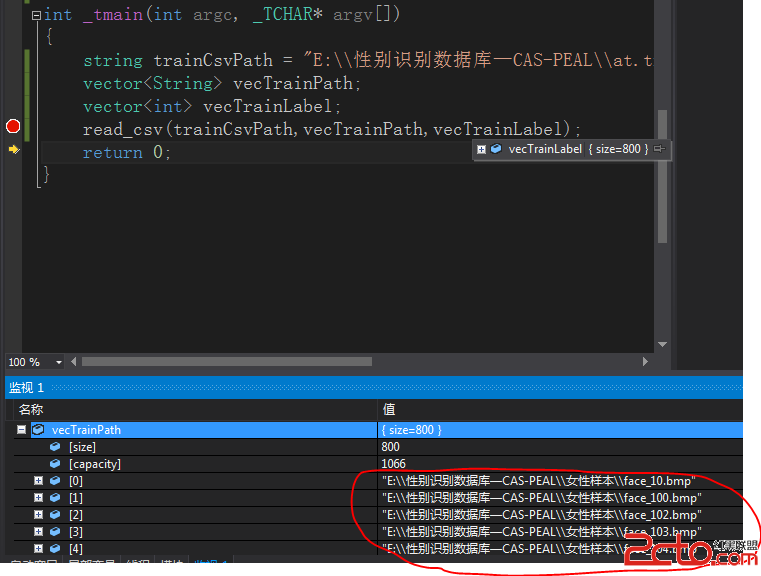
1.引言
本文的寫作目的並不在於提供C/C++程序員求職面試指導,而旨在從技術上分析面試題的內涵。文中的大多數面試題來自各大論壇,部分試題解答也參考了網友的意見。
許多面試題看似簡單,卻需要深厚的基本功才能給出完美的解答。企業要求面試者寫一個最簡單的strcpy函數都可看出面試者在技術上究竟達到了怎樣的程度,我們能真正寫好一個strcpy函數嗎?我們都覺得自己能,可是我們寫出的strcpy很可能只能拿到10分中的2分。讀者可從本文看到strcpy函數從2分到10分解答的例子,看看自己屬於什麼樣的層次。此外,還有一些面試題考查面試者敏捷的思維能力。
分析這些面試題,本身包含很強的趣味性;而作為一名研發人員,通過對這些面試題的深入剖析則可進一步增強自身的內功。
2.找錯題
試題1:
void test1()
{
char string[10];
char* str1 = "0123456789";
strcpy( string, str1 );
}
試題2:
void test2()
{
char string[10], str1[10];
int i;
for(i=0; i<10; i++)
{
str1[i] = 'a';
}
strcpy( string, str1 );
}
試題3:
void test3(char* str1)
{
char string[10];
if( strlen( str1 ) <= 10 )
{
strcpy( string, str1 );
}
}
解答:
試題1字符串str1需要11個字節才能存放下(包括末尾的’\0’),而string只有10個字節的空間,strcpy會導致數組越界;
對試題2,如果面試者指出字符數組str1不能在數組內結束可以給3分;如果面試者指出strcpy(string, str1)調用使得從str1內存起復制到string內存起所復制的字節數具有不確定性可以給7分,在此基礎上指出庫函數strcpy工作方式的給10分;
對試題3,if(strlen(str1) <= 10)應改為if(strlen(str1) < 10),因為strlen的結果未統計’\0’所占用的1個字節。
剖析:
考查對基本功的掌握:
(1)字符串以’\0’結尾;
(2)對數組越界把握的敏感度;
(3)庫函數strcpy的工作方式,如果編寫一個標准strcpy函數的總分值為10,下面給出幾個不同得分的答案:
2分
void strcpy( char *strDest, char *strSrc )
{
while( (*strDest++ = * strSrc++) != ‘\0’ );
}
4分
void strcpy( char *strDest, const char *strSrc )
//將源字符串加const,表明其為輸入參數,加2分
{
while( (*strDest++ = * strSrc++) != ‘\0’ );
}
7分
void strcpy(char *strDest, const char *strSrc)
{
//對源地址和目的地址加非0斷言,加3分
assert( (strDest != NULL) && (strSrc != NULL) );
while( (*strDest++ = * strSrc++) != ‘\0’ );
}
10分
//為了實現鏈式操作,將目的地址返回,加3分!
char * strcpy( char *strDest, const char *strSrc )
{
assert( (strDest != NULL) && (strSrc != NULL) );
char *address = strDest;
while( (*strDest++ = * strSrc++) != ‘\0’ );
return address;
}
從2分到10分的幾個答案我們可以清楚的看到,小小的strcpy竟然暗藏著這麼多玄機,真不是蓋的!需要多麼扎實的基本功才能寫一個完美的strcpy啊!
(4)對strlen的掌握,它沒有包括字符串末尾的'\0'。
讀者看了不同分值的strcpy版本,應該也可以寫出一個10分的strlen函數了,完美的版本為: int strlen( const char *str ) //輸入參數const
{
assert( strt != NULL ); //斷言字符串地址非0
int len;
while( (*str++) != '\0' )
{
len++;
}
return len;
}
試題4:
void GetMemory( char *p )
{
p = (char *) malloc( 100 );
}
void Test( void )
{
char *str = NULL;
GetMemory( str );
strcpy( str, "hello world" );
printf( str );
}
試題5:
char *GetMemory( void )
{
char p[] = "hello world";
return p;
}
void Test( void )
{
char *str = NULL;
str = GetMemory();
printf( str );
}
試題6:
void GetMemory( char **p, int num )
{
*p = (char *) malloc( num );
}
void Test( void )
{
char *str = NULL;
GetMemory( &str, 100 );
strcpy( str, "hello" );
printf( str );
}
試題7:
void Test( void )
{
char *str = (char *) malloc( 100 );
strcpy( str, "hello" );
free( str );
... //省略的其它語句
}
解答:
試題4傳入中GetMemory( char *p )函數的形參為字符串指針,在函數內部修改形參並不能真正的改變傳入形參的值,執行完
char *str = NULL;
GetMemory( str );
後的str仍然為NULL;
試題5中
char p[] = "hello world";
return p;
的p[]數組為函數內的局部自動變量,在函數返回後,內存已經被釋放。這是許多程序員常犯的錯誤,其根源在於不理解變量的生存期。
試題6的GetMemory避免了試題4的問題,傳入GetMemory的參數為字符串指針的指針,但是在GetMemory中執行申請內存及賦值語句
*p = (char *) malloc( num );
後未判斷內存是否申請成功,應加上:
if ( *p == NULL )
{
...//進行申請內存失敗處理
}
試題7存在與試題6同樣的問題,在執行
char *str = (char *) malloc(100);
後未進行內存是否申請成功的判斷;另外,在free(str)後未置str為空,導致可能變成一個“野”指針,應加上:
str = NULL;
試題6的Test函數中也未對malloc的內存進行釋放。
剖析:
試題4~7考查面試者對內存操作的理解程度,基本功扎實的面試者一般都能正確的回答其中50~60的錯誤。但是要完全解答正確,卻也絕非易事。
對內存操作的考查主要集中在:
(1)指針的理解;
(2)變量的生存期及作用范圍;
(3)良好的動態內存申請和釋放習慣。
再看看下面的一段程序有什麼錯誤:
swap( int* p1,int* p2 )
{
int *p;
*p = *p1;
*p1 = *p2;
*p2 = *p;
}
在swap函數中,p是一個“野”指針,有可能指向系統區,導致程序運行的崩潰。在VC++中DEBUG運行時提示錯誤“Access Violation”。該程序應該改為:
swap( int* p1,int* p2 )
{
int p;
p = *p1;
*p1 = *p2;
*p2 = p;
}
3.內功題
試題1:分別給出BOOL,int,float,指針變量 與“零值”比較的 if 語句(假設變量名為var)
解答:
BOOL型變量:if(!var)
int型變量: if(var==0)
float型變量:
const float EPSINON = 0.00001;
if ((x >= - EPSINON) && (x <= EPSINON)
指針變量: if(var==NULL)
剖析:
考查對0值判斷的“內功”,BOOL型變量的0判斷完全可以寫成if(var==0),而int型變量也可以寫成if(!var),指針變量的判斷也可以寫成if(!var),上述寫法雖然程序都能正確運行,但是未能清晰地表達程序的意思。
一般的,如果想讓if判斷一個變量的“真”、“假”,應直接使用if(var)、if(!var),表明其為“邏輯”判斷;如果用if判斷一個數值型變量(short、int、long等),應該用if(var==0),表明是與0進行“數值”上的比較;而判斷指針則適宜用if(var==NULL),這是一種很好的編程習慣。
浮點型變量並不精確,所以不可將float變量用“==”或“!=”與數字比較,應該設法轉化成“>=”或“<=”形式。如果寫成if (x == 0.0),則判為錯,得0分。
試題2:以下為Windows NT下的32位C++程序,請計算sizeof的值
void Func ( char str[100] )
{
sizeof( str ) = ?
}
void *p = malloc( 100 );
sizeof ( p ) = ?
解答:
sizeof( str ) = 4
sizeof ( p ) = 4
剖析:
Func ( char str[100] )函數中數組名作為函數形參時,在函數體內,數組名失去了本身的內涵,僅僅只是一個指針;在失去其內涵的同時,它還失去了其常量特性,可以作自增、自減等操作,可以被修改。
數組名的本質如下:
(1)數組名指代一種數據結構,這種數據結構就是數組;
例如:
char str[10];
cout << sizeof(str) << endl;
輸出結果為10,str指代數據結構char[10]。
(2)數組名可以轉換為指向其指代實體的指針,而且是一個指針常量,不能作自增、自減等操作,不能被修改;
char str[10];
str++; //編譯出錯,提示str不是左值
(3)數組名作為函數形參時,淪為普通指針。
Windows NT 32位平台下,指針的長度(占用內存的大小)為4字節,故sizeof( str ) 、sizeof ( p ) 都為4。
試題3:寫一個“標准”宏MIN,這個宏輸入兩個參數並返回較小的一個。另外,當你寫下面的代碼時會發生什麼事?
least = MIN(*p++, b);
解答:
#define MIN(A,B) ((A) <= (B) ? (A) : (B))
MIN(*p++, b)會產生宏的副作用
剖析:
這個面試題主要考查面試者對宏定義的使用,宏定義可以實現類似於函數的功能,但是它終歸不是函數,而宏定義中括弧中的“參數”也不是真的參數,在宏展開的時候對“參數”進行的是一對一的替換。
程序員對宏定義的使用要非常小心,特別要注意兩個問題:
(1)謹慎地將宏定義中的“參數”和整個宏用用括弧括起來。所以,嚴格地講,下述解答:
#define MIN(A,B) (A) <= (B) ? (A) : (B)
#define MIN(A,B) (A <= B ? A : B )
都應判0分;
(2)防止宏的副作用。
宏定義#define MIN(A,B) ((A) <= (B) ? (A) : (B))對MIN(*p++, b)的作用結果是:
((*p++) <= (b) ? (*p++) : (*p++))
這個表達式會產生副作用,指針p會作三次++自增操作。
除此之外,另一個應該判0分的解答是:
#define MIN(A,B) ((A) <= (B) ? (A) : (B));
這個解答在宏定義的後面加“;”,顯示編寫者對宏的概念模糊不清,只能被無情地判0分並被面試官淘汰。
試題4:為什麼標准頭文件都有類似以下的結構?
#ifndef __INCvxWorksh
#define __INCvxWorksh
#ifdef __cplusplus
extern "C" {
#endif
/*...*/
#ifdef __cplusplus
}
#endif
#endif /* __INCvxWorksh */
解答:
頭文件中的編譯宏
#ifndef __INCvxWorksh
#define __INCvxWorksh
#endif
的作用是防止被重復引用。
作為一種面向對象的語言,C++支持函數重載,而過程式語言C則不支持。函數被C++編譯後在symbol庫中的名字與C語言的不同。例如,假設某個函數的原型為:
void foo(int x, int y);
該函數被C編譯器編譯後在symbol庫中的名字為_foo,而C++編譯器則會產生像_foo_int_int之類的名字。_foo_int_int這樣的名字包含了函數名和函數參數數量及類型信息,C++就是考這種機制來實現函數重載的。
為了實現C和C++的混合編程,C++提供了C連接交換指定符號extern "C"來解決名字匹配問題,函數聲明前加上extern "C"後,則編譯器就會按照C語言的方式將該函數編譯為_foo,這樣C語言中就可以調用C++的函數了。
試題5:編寫一個函數,作用是把一個char組成的字符串循環右移n個。比如原來是“abcdefghi”如果n=2,移位後應該是“hiabcdefgh”
函數頭是這樣的:
//pStr是指向以'\0'結尾的字符串的指針
//steps是要求移動的n
void LoopMove ( char * pStr, int steps )
{
//請填充...
}
解答:
正確解答1:
void LoopMove ( char *pStr, int steps )
{
int n = strlen( pStr ) - steps;
char tmp[MAX_LEN];
strcpy ( tmp, pStr + n );
strcpy ( tmp + steps, pStr);
*( tmp + strlen ( pStr ) ) = '\0';
strcpy( pStr, tmp );
}
正確解答2:
void LoopMove ( char *pStr, int steps )
{
int n = strlen( pStr ) - steps;
char tmp[MAX_LEN];
memcpy( tmp, pStr + n, steps );
memcpy(pStr + steps, pStr, n );
memcpy(pStr, tmp, steps );
}
剖析:
這個試題主要考查面試者對標准庫函數的熟練程度,在需要的時候引用庫函數可以很大程度上簡化程序編寫的工作量。
最頻繁被使用的庫函數包括:
(1) strcpy
(2) memcpy
(3) memset
試題6:已知WAV文件格式如下表,打開一個WAV文件,以適當的數據結構組織WAV文件頭並解析WAV格式的各項信息。
WAVE文件格式說明表
偏移地址 字節數 數據類型 內 容 文件頭 00H 4 Char "RIFF"標志 04H 4 int32 文件長度 08H 4 Char "WAVE"標志 0CH 4 Char "fmt"標志 10H 4 過渡字節(不定) 14H 2 int16 格式類別 16H 2 int16 通道數 18H 2 int16 采樣率(每秒樣本數),表示每個通道的播放速度 1CH 4 int32 波形音頻數據傳送速率 20H 2 int16 數據塊的調整數(按字節算的) 22H 2 每樣本的數據位數 24H 4 Char 數據標記符"data" 28H 4 int32 語音數據的長度解答:
將WAV文件格式定義為結構體WAVEFORMAT:
typedef struct tagWaveFormat
{
char cRiffFlag[4];
UIN32 nFileLen;
char cWaveFlag[4];
char cFmtFlag[4];
char cTransition[4];
UIN16 nFormatTag ;
UIN16 nChannels;
UIN16 nSamplesPerSec;
UIN32 nAvgBytesperSec;
UIN16 nBlockAlign;
UIN16 nBitNumPerSample;
char cDataFlag[4];
UIN16 nAudioLength;
} WAVEFORMAT;
假設WAV文件內容讀出後存放在指針buffer開始的內存單元內,則分析文件格式的代碼很簡單,為:
WAVEFORMAT waveFormat;
memcpy( &waveFormat, buffer,sizeof( WAVEFORMAT ) );
直接通過訪問waveFormat的成員,就可以獲得特定WAV文件的各項格式信息。
剖析:
試題6考查面試者組織數據結構的能力,有經驗的程序設計者將屬於一個整體的數據成員組織為一個結構體,利用指針類型轉換,可以將memcpy、memset等函數直接用於結構體地址,進行結構體的整體操作。 透過這個題可以看出面試者的程序設計經驗是否豐富。
試題7:編寫類String的構造函數、析構函數和賦值函數,已知類String的原型為:
class String
{
public:
String(const char *str = NULL); // 普通構造函數
String(const String &other); // 拷貝構造函數
~ String(void); // 析構函數
String & operate =(const String &other); // 賦值函數
private:
char *m_data; // 用於保存字符串
};
解答:
//普通構造函數
String::String(const char *str)
{
if(str==NULL)
{
m_data = new char[1]; // 得分點:對空字符串自動申請存放結束標志'\0'的空
//加分點:對m_data加NULL 判斷
*m_data = '\0';
}
else
{
int length = strlen(str);
m_data = new char[length+1]; // 若能加 NULL 判斷則更好
strcpy(m_data, str);
}
}
// String的析構函數
String::~String(void)
{
delete [] m_data; // 或delete m_data;
}
//拷貝構造函數
String::String(const String &other) // 得分點:輸入參數為const型
{
int length = strlen(other.m_data);
m_data = new char[length+1]; //加分點:對m_data加NULL 判斷
strcpy(m_data, other.m_data);
}
//賦值函數
String & String::operate =(const String &other) // 得分點:輸入參數為const型
{
if(this == &other) //得分點:檢查自賦值
return *this;
delete [] m_data; //得分點:釋放原有的內存資源
int length = strlen( other.m_data );
m_data = new char[length+1]; //加分點:對m_data加NULL 判斷
strcpy( m_data, other.m_data );
return *this; //得分點:返回本對象的引用
}
剖析:
能夠准確無誤地編寫出String類的構造函數、拷貝構造函數、賦值函數和析構函數的面試者至少已經具備了C++基本功的60%以上!
在這個類中包括了指針類成員變量m_data,當類中包括指針類成員變量時,一定要重載其拷貝構造函數、賦值函數和析構函數,這既是對C++程序員的基本要求,也是《Effective C++》中特別強調的條款。
仔細學習這個類,特別注意加注釋的得分點和加分點的意義,這樣就具備了60%以上的C++基本功!
試題8:請說出static和const關鍵字盡可能多的作用
解答:
static關鍵字至少有下列n個作用:
(1)函數體內static變量的作用范圍為該函數體,不同於auto變量,該變量的內存只被分配一次,因此其值在下次調用時仍維持上次的值;
(2)在模塊內的static全局變量可以被模塊內所用函數訪問,但不能被模塊外其它函數訪問;
(3)在模塊內的static函數只可被這一模塊內的其它函數調用,這個函數的使用范圍被限制在聲明它的模塊內;
(4)在類中的static成員變量屬於整個類所擁有,對類的所有對象只有一份拷貝;
(5)在類中的static成員函數屬於整個類所擁有,這個函數不接收this指針,因而只能訪問類的static成員變量。
const關鍵字至少有下列n個作用:
(1)欲阻止一個變量被改變,可以使用const關鍵字。在定義該const變量時,通常需要對它進行初始化,因為以後就沒有機會再去改變它了;
(2)對指針來說,可以指定指針本身為const,也可以指定指針所指的數據為const,或二者同時指定為const;
(3)在一個函數聲明中,const可以修飾形參,表明它是一個輸入參數,在函數內部不能改變其值;
(4)對於類的成員函數,若指定其為const類型,則表明其是一個常函數,不能修改類的成員變量;
(5)對於類的成員函數,有時候必須指定其返回值為const類型,以使得其返回值不為“左值”。例如:
const classA operator*(const classA& a1,const classA& a2);
operator*的返回結果必須是一個const對象。如果不是,這樣的變態代碼也不會編譯出錯:
classA a, b, c;
(a * b) = c; // 對a*b的結果賦值
操作(a * b) = c顯然不符合編程者的初衷,也沒有任何意義。
剖析:
驚訝嗎?小小的static和const居然有這麼多功能,我們能回答幾個?如果只能回答1~2個,那還真得閉關再好好修煉修煉。
這個題可以考查面試者對程序設計知識的掌握程度是初級、中級還是比較深入,沒有一定的知識廣度和深度,不可能對這個問題給出全面的解答。大多數人只能回答出static和const關鍵字的部分功能。
4.技巧題
試題1:請寫一個C函數,若處理器是Big_endian的,則返回0;若是Little_endian的,則返回1
解答:
int checkCPU()
{
{
union w
{
int a;
char b;
} c;
c.a = 1;
return (c.b == 1);
}
}
剖析:
嵌入式系統開發者應該對Little-endian和Big-endian模式非常了解。采用Little-endian模式的CPU對操作數的存放方式是從低字節到高字節,而Big-endian模式對操作數的存放方式是從高字節到低字節。例如,16bit寬的數0x1234在Little-endian模式CPU內存中的存放方式(假設從地址0x4000開始存放)為:
內存地址 存放內容 0x4000 0x34 0x4001 0x12而在Big-endian模式CPU內存中的存放方式則為:
內存地址 存放內容 0x4000 0x12 0x4001 0x3432bit寬的數0x12345678在Little-endian模式CPU內存中的存放方式(假設從地址0x4000開始存放)為:
內存地址 存放內容 0x4000 0x78 0x4001 0x56 0x4002 0x34 0x4003 0x12而在Big-endian模式CPU內存中的存放方式則為:
內存地址 存放內容 0x4000 0x12 0x4001 0x34 0x4002 0x56 0x4003 0x78聯合體union的存放順序是所有成員都從低地址開始存放,面試者的解答利用該特性,輕松地獲得了CPU對內存采用Little-endian還是Big-endian模式讀寫。如果誰能當場給出這個解答,那簡直就是一個天才的程序員。
試題2:寫一個函數返回1+2+3+…+n的值(假定結果不會超過長整型變量的范圍)
解答:
int Sum( int n )
{
return ( (long)1 + n) * n / 2; //或return (1l + n) * n / 2;
}
剖析:
對於這個題,只能說,也許最簡單的答案就是最好的答案。下面的解答,或者基於下面的解答思路去優化,不管怎麼“折騰”,其效率也不可能與直接return ( 1 l + n ) * n / 2相比!
int Sum( int n )
{
long sum = 0;
for( int i=1; i<=n; i++ )
{
sum += i;
}
return sum;
}
所以程序員們需要敏感地將數學等知識用在程序設計中。