在1994年,我主要關心的是如何使ISO C++標准盡可能地好--同時在它所包含的特性和規范的質量兩個方面--並獲得多數人的同意。即使人們不接受某種規范,也不會影響它(規范)的良好性。ISO標准沒有強制力,因此有些人認為自己不值得浪費時間來適應它,除非(群體)社團的壓力能夠使他們確信該規范的價值。對於一個實現者來說,適應環境是很重要的額外工作,因此適應環境是一個有意識的決定,並且需要分配一些資源,而這些資源本來可以在其它地方使用。某些晦澀的語言特性很難在某些編譯器中實現。我們可以實現或者購買類庫,而且領先的、可靠的實現者(implementer)也有機會用自己的富於想像力的專利特性來"鎖定"用戶。因此,我認為要點是:讓委員會成員和他們所代表的組織確信該標准的文檔是他們所期望看到的最好的文檔。
在做了很多工作之後,該委員會獲得了成功。1997年10月,在Morristown(New Jersey,USA)會議上,技術成員的最終投票結果是43-0。在獲知這個結果以後,我們進行了慶祝活動!在1998年,ISO成員國以空前的22-0的投票結果批准了這個標准。為了獲取大家的一致同意,委員會做了大量的技術工作,也使用了一些外交策略:在那個時候,我喜歡說"政治問題無法解決;我們必須找到引發該問題的技術問題並解決它"。我無法想象僅僅通過投票,因為少數服從多數才簡單"解決"的問題,同時,由於"政治上的討價還價"的問題也危害了我們最好的技術判斷--而這個問題(模板的分開編譯)仍然在"惡化",需要尋找一個更好的技術方案。
在最後投票之前的一年裡,委員會的工作是:
1. 細節、細節和更多的細節。
2. STL
3. 模板的分開編譯
第一個問題非常明顯:國際標准必須用大量的篇幅來關注細節信息;實際上,實現(implement)與已有標准的兼容性是標准的關鍵目標,同時還是實現之間的工具和應用程序能夠遷移的基礎。標准是一個712頁的文檔(加上索引等內容),它是采用高度技術化的和正式的方式編寫的,因此為了理解真正的含義需要很多的細節信息。像以前一樣,我在新語言規范上附加了新版的"C++編程語言",以提供更有幫助意義和面向用戶的語言描述。
STL的出現
第二個問題,STL("標准模板類庫",它是ISO C++標准類庫的容器和算法框架)成為標准的一部分是一個主要的創新,並且它成為了新的用以思考已經出現的編程技術的出發點。STL基本上革命性地脫離了我們原來思考容器和容器使用問題的方式。在Simula早期,容器(例如列表)曾經是困擾人的:如果,並且只有當某個對象已經(顯式或隱式地)衍生自那些包含編譯器所需鏈接信息的特定的"Link"或"Object"類的時候,它才能被放到容器中。這種容器基本上是引用Link的容器。這暗示著基本的類型(例如int和double)不能直接地放入容器中,數組類型(它直接支持基本的類型)必定跟其它的容器不同。此外,如果我們希望把真正的簡單類對象(例如complex和Point)放入容器中,那麼它們在時間和空間上就無法達到理想效果。它同時還暗示著這種容器不是靜態類型安全的。例如,Circle可以被加入列表中,但是當它被提取出來的時候,我們只知道它是一個Object,需要使用一個轉換(顯式類型轉換)來恢復其靜態類型。
Simula容器和數組關於內建和用戶定義類型(只有後來的一些可以放入容器)、關於容器和數組(只有數組能夠保存基本的類型;數組不能保存用戶定義類型,只能保存用戶定義類型的指針)都有一些奇怪的條款。Smalltalk使用了相同的方法,也有相同的問題,後來的一些語言(例如Java和C#)也是這樣的。由於它有明顯的效用,而且很多設計者現在都熟悉它,所以很多C++類庫也遵循這種模型。但是,我卻發現它是無規律的和低效率的(在時間和空間上),使用它開發真正通用的類庫是不可以接受的。這就是我在1985年沒有為C++提供適當的標准類庫(這個失誤)的根本原因。
當我編寫D&E的時候,我知道了一種容器和容器使用的新方法,它是由Alex Stepanov開發的。Alex當時在HP實驗室工作,之前在Bell實驗室工作了多年,在那兒他接近了Andrew Koenig,我也在那兒與他討論過類庫設計和模板機制。他鼓勵我進一步研究某些模板機制的泛化和效率,但是很幸運的是,他卻沒有說服我讓模板更類似Ada泛型。如果他成功了,他就無法設計和實現STL了!
在1993年末,Alex在泛型編程技術方面顯示了他最近十年的長期研究的進展,這種技術是基於嚴格的數學基礎的、目標是成為"最通用和最高效"的編程技術。他是一個容器和算法的框架。他首先聯系了Andrew,Andrew花幾天時間研究這種技術之後,就把它展示給我了。我的第一反映是很迷惑。我發現STL的容器和容器使用方式是多余的,甚至於是丑陋的。與很多通曉面向對象編程的程序員一樣,我認為自己知道容器的樣子與STL代碼的樣子有怎樣的不同。但是,在我建立工具列表(我認為這個列表對於容器來說是很重要的)的幾年裡,令我驚訝的是,我發現STL除了一個條件之外,符合其它所有的條件。那個缺少的條件是使用通用基類為所有的衍生類(例如所有的對象或容器)提供服務(例如永續性)。但是,我不認為這種服務對容器的概念有本質的意義。
它讓我花了幾周時間才感覺到STL比較"舒適"。在那以後,我擔心把一個全新樣式的類庫介紹給C++群體已經太晚了。讓標准委員會在標准進行過程中這麼遲的時候接受新的和革命性的東西的成功幾率是非常小的(的確是這樣的)。即使出現最好的情況,標准也會被延遲一年--而C++群體急切需要該標准。同時,委員會本質上是一個保守的團體,而STL是革命性的。
因此成功的機會是很渺茫的,但是我還是在它上面進行著辛勤的工作。畢竟,由於C++沒有足夠大的、足夠好的標准庫,我的感覺非常糟糕。Andrew Koenig盡了最大的努力來鼓勵我,並且Alex Stepanov用他知道的最好的東西來游說Andy和我。幸運的是,Alex不太了解在委員會中使某種東西成為主流的難度,因此他不太沮喪,並且繼續研究技術方面,繼續為Andrew和我講授。我開始給其他人解釋STL背後的想法。
1993年10月,在加利福尼亞的San Jose舉行的標准委員會會議上,我們邀請了Alex進行晚間演講。"它叫做C++編程的科學,它處理了規則類型的大多數原則--連接構造、賦值和等同。我還介紹了轉發迭代子的原則。我沒有提起任何容器的問題,只提到一個算法:查找"。這次演講是活躍的下層社會的大膽創新,而其巨大的樂趣使委員會的態度從"現在讓我們作些主要的事情"變成了"等等,讓我們瞧一瞧"。
這正是我們需要的"暫停時間"!在後來的四個月中,我們進行試驗、爭論、游說、講授、編程和重新設計,這樣Alex才能在1994年三月加利福尼亞的San Diego委員會會議上提供STL的完整說明。1994年末在HP一個會議上,Alex提出了C++類庫實現,我們在很多細節上達成了一致,但是STL的大小成為了主要的障礙。最後,在Alex的催促下,我拿起筆,逐字地刪除,大約刪掉了三分之二的內容。對於每一個工具,我都必須向Alex和其他類庫專家非常簡短地解釋為什麼它不能被刪掉、為什麼它使大多數C++程序員受益。這是個可怕的過程。Alex後來聲明說這讓他心痛。但是,這樣的刪減造就了現在知名的STL,並讓它1994年10月在加拿大Waterloo的會議上成為ISO C++標准的一部分--而原始的和完全的STL都沒有達到這個目標。對"簡化STL"的必要修改也把標准延遲了一年以上。回想起來,我認為當時我們做的事情造成的傷害比預料的要小一些。
在對采用STL的可能性的討論中,我記得一件事情:Beman Dawes冷靜地聲明自己認為STL對於普通程序員來說過於復雜了,但是作為試驗,他自己實現了10%,從此他不再認為STL超過了標准的難度。Beman是委員會中很少編寫應用程序的人。不幸的是,委員會趨向於由建立編譯器、類庫和工具的人員所控制。
在STL方面我信任Alex Stepanov。在STL之前,他花了十年以上的時間,用一些無用的語言(例如Scheme和Ada)來研究基本的想法和技術。但是,Alex第一個堅持要求其他人一起參與。David Musser和Alex在泛型編程方面一起工作了約二十年,Meng Lee與他一起在HP工作,幫助他編寫最初的STL。Alex和Andrew Koenig之間的電子郵件討論也有幫助作用。除了苛刻的試驗之外,我的貢獻很小。我建議與內存相關的所有信息都集中到一個對象中--就形成了分配器(allocator)。我還草擬了Alex想法的初始需求表,建立表格記錄STL算法和類對它們的模板參數的要求。這些需求表實際上表明這種語言的表達能力不足--這種需求應該成為代碼的一部分。
1.1 STL的理念
那麼什麼是STL呢?到目前為止,它作為標准C++的一部分已經快十年了,因此你的確應該知道它,但是如果你不熟悉現代的C++,那麼我就有必要對它的想法和語言使用方式作一些簡單的介紹。
我們來考慮一個問題:把對象存儲在容器中,並編寫算法來操作這些對象。我們按照直接、獨立和概念的混合表現方式來考慮這個問題。自然地,我們希望能夠在多種容器(例如列表、向量、映射)中存儲多種類型(例如整型、Point、Shape)的對象,並在容器中的對象上應用大量的算法(例如排序、檢索、積聚)。此外,我們希望使用的這些對象、容器和算法都是靜態類型安全的、盡可能地快速、盡可能地簡潔、不冗長、易於閱讀。同時實現這些目標並不容易。實際上,為了解決這個難題,我差不多花費了十年還是沒有找到成功的方法。
STL解決方案是以帶元素類型的參數化容器以及與容器完全分離的算法為基礎的。容器的每種類型都提供一種迭代子(iterator)類型,只使用這些迭代子就可以實現對容器中所有元素的訪問。通過這種方式,我們可以編寫算法來使用迭代子而不用知道提供迭代子的容器的信息。每種迭代子類型與其它類型都是完全獨立的,除非要為必要的操作(例如*和++)提供了相同語義(semantics)。我們可以用圖形來說明。
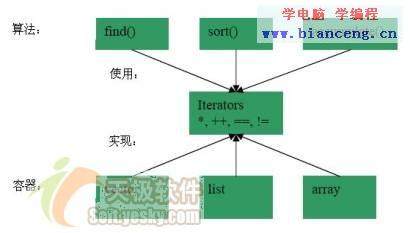
我們來看一個很恰當的例子,它在不同的容器中查找不同類型的元素。首先,下面是兩個容器:
vector<int> vi; // 整型向量
list<double> vd; // 雙精度型列表
目前存在一些向量和列表概念的標准類庫,它們是作為模板實現的。假如你已經用相應的元素類型值恰當地初始化過它們,那麼在vi中查找第一個值為7的元素和在vd中查找第一個值為3.14的元素的語法如下:
vector<int>::iterator p = find(vi.begin(),vi.end(),7);
list<double>::iterator q = find(vd.begin(),vd.end(),3.14);
其基本的想法是,你能夠把任何容器的(所有)元素都作為一個元素序列(sequence)。容器"知道"第一個元素在哪兒,最後一個元素在哪兒。我們把指向一個元素的對象稱為"迭代子"。接著我們就可以使用一對迭代子(begin()和end())來表示容器中的元素,其中begin()指向第一個元素,end()指向最後一個元素前面。
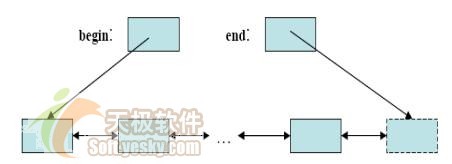
end()迭代子指向最後一個元素後面,而不是指向最後一個元素,這就使空序列不會成為一種特殊情況。
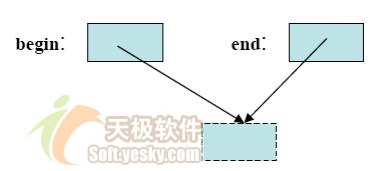
你能對迭代子做什麼樣的操作?你可以得到迭代子指向的元素的值(像指針一樣使用*),可以使迭代子指向下一個元素(像指針一樣使用++),可以比較兩個迭代子,看它們是否指向同一個元素(使用==或!=)。令人驚訝的是,這已經足以實現find()(查找功能)了:
template<class Iter, class T> Iter find(Iter first, Iter last, const T& val)
{
while (first!=last && *first!=val) ++first;
return first;
}
這是一個簡單的--真的非常簡單的--模板函數。熟悉C和C++指針的人應該發現這些代碼很容易閱讀的:first!=last檢查我們是否到了序列末尾,*first!=val檢查我們是否找到了值val。如果沒有找到,我們增加first迭代子,使它指向下一個元素並重復。因此,當find()返回的時候,它的值要麼指向值為val的第一個元素,要麼指向最後一個元素後面(end())。於是我們可以編寫下面的代碼:
vector<int>::iterator p = find(vi.begin(),vi.end(),7);
if (p != vi.end()) {
// 我們找到了 7
// …
}
else {
// vi 中沒有 7
// …
}
這是非常非常簡單的。它簡單得像數學書的前面幾頁,速度也很快。但是,我知道自己不是唯一一個花時間來研究它到底是如何實現的、以及為什麼它是一個好的想法的人。與簡單的數學相似,最初的STL規則和原理的概括也是難以置信的。
考慮第一個實現:在調用find(vi.begin(),vi.end(),7)中,迭代子vi.begin()和vi.end()會相應地成first為last,在find()內部有些東西指向int(整型)、int*。在這樣的實現中,*成為了指針,++成為了指針增加操作符,!=成為了指針比較操作符。也就是說,find()的實現是明顯的、理想的。特別地,我們沒有使用函數調用來訪問那些作為運算法則的有效參數的操作符(例如*和!=),因為它們依賴於模板參數。在這種情況中,模板與"泛型"的大多數機制從根本上都是不同的,它依賴於當前編程語言中的間接函數調用(類似虛擬函數)。如果有一個好的優化程序(optimizer),vector<int>::iterator可以成為一個把*和++作為內建函數(inline function)的、沒有資源花費(overhead)的類。這種優化程序現在很少,它通過捕捉無保證的假設(如下所示)來進行類改善類型檢查。
int* p = find(vi.begin(),vi.end(),7); // 迭代子類型不能是 int*
那麼為什麼我們不省去所有的"迭代子材料"和使用指針呢?其中一個原因是vector<int>::iterator可能已經成為了一個提供了范圍檢查訪問的類。我們看看find()的其它調用:
list<double>::iterator q= find(vd.begin(),vd.end(),3.14);
if (q != vd.end()) {
// 我們找到了3.14
// …
}
else {
// vi 中沒有3.14
// …
}
此處list<double>::iterator不會成為double*。實際上,在最普通的鏈表實現方式中,應該是Link*類型的,其中是鏈表節點類型的,例如:
template<class T> struct Link {
T value;
Link* suc;
Link* pre;
};
這意味著,*的意思是p->value(返回值字段),++的意思是p->suc(使指針指向下一個鏈接),!=指針比較的意思是(比較Link*s)。同樣,這種實現也是明顯的、理想的。但是,它與我們前面看到的vector<int>::iterator完全不同了。
我們使用了模板組合(combination)和重載解決方案為find()的單一源代碼定義和使用來挑選根本不同的、也是理想的代碼。請注意,這兒不存在運行時分派(dispatch)、沒有虛擬函數調用。實際上,它只有瑣碎的內聯函數和指針的基本操作(例如*和++)的調用。在速度和代碼大小方面,我們都到取得了很大的成功。
為什麼沒有把"序列"或"容器"作為基本的概念,而使用了"一對迭代子"呢?部分原因在於"一對迭代子"只不過比"容器"的概念更普通。例如,給定迭代子,我們可以只對容器的前一半進行排序:sort(vi.begin(), vi.begin()+vi.size()/2)。另一個原因是STL遵循了C++的設計原則,我們必須一律地提供轉換(transition)路徑、支持內建的和用戶定義類型。如果某個人把數據保存在普通的數組中會怎麼樣呢?我們仍然可以使用STL算法。例如:
char buf[max];
// … 填充buf …
int* p = find(buf,buf+max,7);
if (p != buf+max) {
// 我們找到了 7
// …
}
else {
// buf 中沒有 7
// …
}
此處,find()中的*、++和!=都是指針操作符!與C++本身不同,STL與一些舊的概念(例如C數組)是兼容的。我們始終提供轉換路徑,平等地對待用戶定義類型和內建類型(如數組)。
STL像ISO C++標准庫所采用的容器和算法框架一樣,包含一打容器(例如vector、list和map)和數據結構(例如數組),它們可以被當作序列使用。此外,還有大約60種算法(例如find、sort、accumulate和merge)。你可以查閱資料看到更詳細的信息。
STL的優雅和性能的關鍵在於--與C++本身類似--它是基於直接的內存和計算硬件模型的。STL的序列的概念基本上是把內存作為一組對象序列的硬件視點。STL的基本語法直接映射到硬件指令,允許算法最佳地實現。接下來,模板的編譯時解析和他們支持的完美內聯成為了把STL高級表達式高效率地映射到硬件層的關鍵因素。
1.2 函數對象
我將介紹STL使用的一些基本的技術,它會讓你了解:在普通C++機制上建立的STL是如何提供空前的靈活性和性能的。迄今為止,我們所描述的STL框架組件都有些嚴格。每種算法都嚴格地采用標准指定的方法來准確地實現某種功能。例如,我們需要查找一個與自己指定的值相等的元素。實際上,查找一個帶有某些(自己指定的)屬性的元素,例如小於某個給定的值、匹配某個並非簡單相等的值(例如,匹配大小寫無關的字符串或者在允許很小差別的情況下,匹配雙精度數值),是一項很普通的事務。
下面的例子不是查找值7,我們將查找某些符合條件的值(也就是小於7的值):
vector<int>::iterator p = find_if(v.begin(),v.end(),Less_than<int>(7));
if (p != vi.end()) {
// 我們找到了值小於7 的元素
// …
}
else {
// vi 沒有值小於 7 的元素
// …
}
Less_than<int>(7)是什麼東西呢?它是一個函數對象,它是某個類的對象,該類帶有應用程序操作符(( )),被定義成執行某個函數:
template<class T> struct Less_than {
T value;
Less_than(const T& v) :value(v) { }
bool operator()(const T& v) const { return v<value; }
};
例如:
Less_than<double> f(3.14); // Less_than 保存了雙精度值 3.14
bool b1 = f(3); // b1 為真(3<3.14 是真的)
bool b2 = f(4); // b2 為假(4<3.14 是假的)
從2004年的情況來看,在D&E中沒有提到函數對象是很奇怪的。我們應該使用一個章節來講述它們。甚至於用戶自定義的應用程序操作符(( ))的使用情況也沒有提到,盡管它已經存在很長時間,並且很卓著。例如,它是幾個最初的允許重載的操作符之一(在=之後),它還用於模仿Fortran下標(subscript notation)。
我們可以編寫一個find()版本,它使用了函數對象,而不是簡單的!=來檢測是否可以找到某個元素。它的名字是find_if():
template<class In, class Pred>
In find_if(In first, In last, Pred pred)
{
while (first!=last && !pred(*first)) ++first;
return first;
}
我們簡單地用!pred(*first)代替了*first!=val。函數模板find_if()會接受任何能夠把元素值作為參數調用的對象。特別地,我們可以把普通的函數作為它的第三個參數來調用find_if():
bool less_than_7(int a)
{
return 7<a;
}
vector<int>::iterator p = find_if(v.begin(),v.end(),less_than_7);
但是,這個例子顯示了,與函數相比我們為什麼更喜歡函數對象:我們可以使用一個(或多個)參數來初始化函數對象,同時函數對象可以保持這些信息供以後使用。函數對象可以保持任何狀態。這樣就可以形成更通用、更優良的代碼。如果我們需要,我們以後可以檢查它的狀態。例如:
template<class T> struct Accumulator { // 保持 n 個值的總和
T value;
int count;
Accumulator() :value(), count(0) { }
Accumulator(const T& v) :value(v), count(0) { }
void operator()(const T& v) { ++count; value+=v; }
};
我們可以把Accumulator對象傳遞給一個重復調用它的算法。其部分結果保持在對象中。例如:
int main()
{
vector<double> v;
double d;
while (cin>>d) v.push_back(d);
Accumulator<double> ad;
ad = for_each(v.begin(),v.end(), ad);
cout << "sum==" << ad.value
<< ", mean==" << ad.value/ad.count << '\n ';
}
標准類庫算法for_each簡單地把它的第三個參數應用在自己序列中的每個元素上,並把這個參數作為返回值。另一種使用函數對象的方法比較"雜亂"--就是使用全局變量來保持value和count。
有趣的是,簡單的函數對象比功能相同的函數的性能更好。其原因在於它們趨向於按值(by value)傳遞,因此它們更易於內聯(inline)。當我們傳遞那些執行很簡單操作(例如用於排序的比較條件)的對象或函數的時候,這一點是非常重要的。特別地,當對簡單類型(例如整型或雙精度型)的數組進行排序的時候,函數對象的內聯就是STL(C++標准類庫)的sort()在多方面超越了傳統的qsort()原因。
函數對象是用於更高級構造的一種C++機制。它並非高級理念的最好表達方式,但是它在用於普通目的的語言環境中,顯示出令人驚訝的表現能力和固有的高性能。作為表現能力的一個例子,Jaakko J?rvi演示了如何提供和使用一個Lambda類,使它的真正意義合法化:
Lambda x;
List<int>::iterator p = find_if(lst.begin(),lst.end(),x<=7);
如果你希望 <= 能夠工作,那麼不用建立一個通用類庫,而是為Lambda和<=添加大約十余行代碼定義。如果使用上面例子中的Less_than,那麼我們可以簡單地添加:
class Lambda {};
template<class T> Less_than<T> operator<=(Lambda,const T& v)
{
return Less_than<T>(v);
}
因此,find_if調用中的x<=7參數變成了operator<=(Lambda,const int&)調用,它會生成一個Less_than<int>對象,它就是這一部分中第一個例子所使用的對象。它們之間的差別僅僅是--我們實現了更簡單和直觀的語法。這是C++表現能力的一個很好的例子,也是類庫的接口如何比其實現更加簡單的例子。自然地,與辛苦地編寫一個循環來查找值小於7的元素相比,它是沒有運行時開銷的。
1.3 STL的影響
STL對C++的思想的影響是極大的。在STL之前,我一般列舉C++支持的三種基本的編程樣式("范例"):
-面向過程編程
-數據抽象
-面向對象編程
我認為模板是對數據抽象的支持。在試用了STL一段時間之後,我提出第四種樣式:
-泛型編程
以使用模板為基礎的技術,以及從功能性編程中獲取大量靈感的技術與傳統的數據抽象有本質的不同。人們只是認為類型、對象和資源不同。新的C++類庫是使用模板技術編寫的,才獲得了靜態類型安全和高效率。模板技術對於嵌入式系統編程和高性能數學運算也是很關鍵的,在這些環境中,資源的管理和正確性是關鍵。在這些領域中STL並非總是理想的。例如,它沒有直接地支持線性代數,而且在緊湊的實時系統中(在這種環境下一般會禁止自由地使用存儲)也很難使用它。但是,STL證明了在模板的幫助下可以實現什麼樣的功能,並提出了一些有效的技術示例。例如,利用迭代子(和分配器)把邏輯內存訪問與實際內存訪問分離開來,對於很多高性能數字運算就是很關鍵的;使用小型的、簡單的內聯、對象對於嵌入式系統編程中最佳地使用硬件也是很關鍵的。這類技術有一些記載在標准委員會關於性能的技術報告中了。這是對當前過度地使用過分依賴於類層次和虛擬函數的"面向對象"技術的這種趨勢的一種大范圍的反擊--也是一種有建設意義的替代方案。
很明顯,STL並不完美。相對來說沒有完美的東西。但是,它開辟了新天地,而且它擁有的影響力甚至於超過了巨大的C++群體。使用C++時,當人們試圖推動STL所倡導的技術來超越STL技術的時候,它們討論"模板元數據編程"。我們中有些人也會考慮STL迭代子的限制(使用generator和range是不是更好?),以及C++如何更好地支持這些使用(概念、初始化器)。