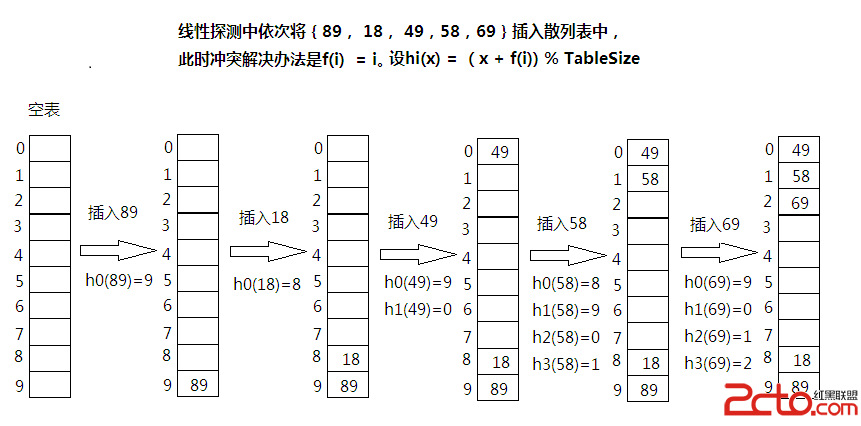
簡介
從處理器的角度來看,線程是一個單獨的執行流程,每個線程都有各自的寄存器及堆棧上下文。通常來說,在系統中只有一個處理器或處理器只有一個核心時,運行時環境在一個時間片內只能執行一個線程,當線程未能獲取所需的資源時,線程的執行就會被中斷,且會一直等到相關操作的完成,如I/O;或者在線程用完它的處理器時間片時,也會被中斷下來等待。而處理器把執行流程從一個線程切換到另一個線程時,這稱為"上下文切換";當某個線程變為"阻塞"狀態,從而執行另一個線程時,系統有效地減少了處理器空閒時間,這稱為"多任務"。
當程序執行時,系統知道可以從磁盤上某處獲取相關的指令及靜態數據,程序會被分配到一組包含虛擬內存在內的地址空間,這個運行時上下文被稱為"進程"。然而,在一個進程可以運行之前,它必須擁有至少一個線程,也就是說,當一個進程被創建時,它自動被賦予了一個線程,這稱為"主線程"。但是話說回來,這個線程與之後這個進程所創建的線程相比,沒有任何不同之處,它只不過恰好是這個進程的第一個線程而已。一般來說,在程序的控制之下,進程內的線程數在運行時會有所變化,任何線程都可以創建其他的線程,但不管怎樣,線程不擁有它所創建的線程,所有進程內的線程都是作為一個整體屬於這個進程。
可把進程要完成的工作分成不同的"子任務",每一部分都由不同的線程來執行,這稱為"多線程"。進程內的每個線程共享同樣的地址空間與進程資源,當最後一個進程內的線程結束時,父進程就結束了。
為何進程內要有多個線程呢?如果進程只有一個線程,那麼它的執行流程是自上而下順序執行的;當線程阻塞,而又沒有其他的活動線程處於等待狀態時,系統就會進入空閒狀態;如果此時進程的子任務必須被順序地執行,那麼這種情況就不可避免,將花費大量的時間來等待。然而,絕大多數的進程都不是這樣的,試想有這樣一種情況,某個進程有多個選項,用戶可以選擇其中一些選項,由此產生的計算會使用內存或文件中的數據,並生成結果,如果能從中分出一些新的線程,那麼進程不必等待前一個計算的結果,就可以繼續接受新的計算請求。此外,通過指定線程的優先級,進程可只在更關鍵的線程阻塞時,才運行次關鍵的線程。
在有多個線程的情況下,某些線程可負責程序的主要工作,而另一個線程可用於處理鍵盤和鼠標的輸入。例如,用戶可能會覺得前一次請求並不是期望的動作,從而希望取消由前一次請求產生的那一個線程,這時就可在某個下拉菜單中進行選擇,由一個線程去終止另一個線程。
另一個例子就是打印假脫機程序,它的任務是保持打印機盡可能地滿載工作,並處理用戶的打印請求;如果這個程序必須要等到前一項打印工作完成,才能接受新請求的話,用戶可能會感到非常的不滿。當然,程序也可周期性地停下打印工作,來查看是否有新的未處理請求(這稱為"輪詢"),但是,如果沒有新請求,這將會非常浪費時間。另外,如果輪詢的間隔時間太長,對處理新請求,還會造成延時;如果間隔太短,那麼線程在輪詢上花費的時間又太多。那麼,為什麼不讓假脫機程序有兩個線程呢?一個用於將打印工作傳遞到打印機,而另一個用於處於用戶的請求,它們之間都相互獨立運行;而當一個線程工作完成時,它要麼結束自身,要麼進入休眠狀態。
當處理並發的執行線程時,必須要首先了解兩個重要的概念:原子性和重入性。一個原子變量或對象是作為一個整體被訪問的,甚至於在異步操作的情況下也是如此--訪問的是同一個變量或對象。舉例來講,如果一個線程正在更新一個原子變量或對象,而另一個線程在讀取其內容,此時來講,內容邏輯上的完整性是不可能被破壞的,所以,要麼讀取到舊值,要麼讀取到新值,而不會舊值新值各讀一部分。通常來說,能被原子性訪問的變量或對象,只是那些在硬件上能被原子性支持的類型,如字節(Byte)和字(Word)。C++/CLI中大多數的基本類型都確保具有原子性,剩下的類型也可被某種特定的實現支持原子性,但不能百分百保證。顯而易見,一個實現了x與y坐標對的Point對象,不具有原子性,對Point值的寫入,可能會被對其值的讀取中斷,結果就是,讀取到了一個新的x值和一個舊的y值,反之亦然;同樣地,數組也不可能被原子性地訪問。正是因為大多數的對象不能被原子性地訪問,所以必須使用一些同步形式來保證在某一時間,只有一個線程可操縱某個特定的對象。也正是因為此,C++/CLI分配給每一個對象、數據和類一個同步鎖。
一個重入的函數可由多個線程安全地並行執行。當線程開始執行一個函數時,在函數中分配的所有數據都來自棧或堆,但無論如何,對此調用來說,都是唯一的。如果在另一個線程仍處於工作狀態時,本線程開始執行同一個函數,那麼,每個線程中的數據都是相互獨立的。然而,如果函數訪問線程間共享的變量或文件時,則必須使用某些同步方法。
創建線程
在例1中,主線程創建了兩個其他的線程,這三個線程並行運行,並且未進行同步。在線程間並未共享數據,且當最後一個線程結束時,主進程也結束了。
例1:
using namespace System;
using namespace System::Threading;
public ref class ThreadX
{
int loopStart;
int loopEnd;
int dispFrequency;
public:
ThreadX(int startValue, int endValue, int frequency)
{
loopStart = startValue;
loopEnd = endValue;
dispFrequency = frequency;
}
/*1*/ void ThreadEntryPoint()
{
/*2*/ String^ threadName = Thread::CurrentThread->Name;
for (int i = loopStart; i <= loopEnd; ++i)
{
if (i % dispFrequency == 0)
{
Console::WriteLine("{0}: i = {1,10}", threadName, i);
}
}
Console::WriteLine("{0} thread terminating", threadName);
}
};
int main()
{
/*3a*/ ThreadX^ o1 = gcnew ThreadX(0, 1000000, 200000);
/*3b*/ Thread^ t1 = gcnew Thread(gcnew ThreadStart(o1, &ThreadX::ThreadEntryPoint));
/*3c*/ t1->Name = "t1";
/*4a*/ ThreadX^ o2 = gcnew ThreadX(-1000000, 0, 200000);
/*4b*/ Thread^ t2 = gcnew Thread(gcnew ThreadStart(o2, &ThreadX::ThreadEntryPoint));
/*4c*/ t2->Name = "t2";
/*5*/ t1->Start();
/*6*/ t2->Start();
Console::WriteLine("Primary thread terminating");
}
請看標記3a中第一條可執行語句,此處我們創建了一個用戶自定義ThreadX類型的對象,這個類有一個構造函數、一個實例函數及三個字段。我們調用構造函數時,傳遞進一個開始、一個結束計數,及一個固定增量,其用於循環控制。
在標記3b中,創建了一個庫類型System::Thread的對象,它源自命名空間System::Threading,可用此對象來創建一個新的線程,但是,在線程可以工作之前,它必須要知道從哪開始執行,所以傳遞給Thread構造函數一個System::ThreadStart代理類型,其可支持不接受參數的任意函數,且沒有返回值(作為一個代理,它可封裝進多個函數,在本例中,只指定了一個)。在上面的代碼中,指定了線程由執行對象o1的ThreadEntryPoint實例函數開始,一旦開始之後,這個線程將會執行下去直到函數結束。最後,在標記3c中,隨意使用了一個名稱,以設置它的Name屬性。
請看標記4a、4b及4c,第二個線程也一樣,只不過設置了不同的循環控制及名稱。
眼下,已構造了兩個線程對象,但並未創建新的線程,也就是說,這些線程處於未激活狀態。為激活一個線程,必須調用Thread中的Start函數,見標記5與6。通過調用進入點函數,這個函數啟動了一個新的執行線程(對一個已經激活的函數調用Start將導致一個ThreadStateException類型異常)。兩個新的線程都各自顯示出它們的名稱,並在循環中定時地顯示它們的進度,因為每個線程都執行其自身的實例函數,所以每個線程都有其自己的實例數據成員集。
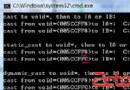
所有三個線程均寫至標准輸出,見插1,可看出線程中的輸出是纏繞在一起的(當然,在後續的執行中,輸出也可能有不同的順序)。可見,主線程在其他兩個線程啟動之前就結束了,這證明了盡管主線程是其他線程的父類,但線程的生命期是無關的。雖然,例中使用的進入點函數無關緊要,但其可調用它可訪問的任意其他函數。 插1:三個線程的纏繞輸出
Primary thread terminating
t1: i = 0
t1: i = 200000
t1: i = 400000
t1: i = 600000
t2: i = -1000000
t2: i = -800000
t2: i = -600000
t2: i = -400000
t2: i = -200000
t2: i = 0
t2 thread terminating
t1: i = 800000
t1: i = 1000000
t1 thread terminating
如果想讓不同的線程由不同的進入點函數開始,只需簡單地在同一或不同的類中,定義這些函數就行了(或作為非成員函數)。
同步語句
例2中的主程序有兩個線程訪問同一Point,其中一個不斷地把Point的x與y坐標設置為一些新值,而另一個取回並顯示這些值。即使兩個線程由同一進入點函數開始執行,通過傳遞一個值給它們的構造函數,可使每個線程的行為都有所不同。
例2:
using namespace System;
using namespace System::Threading;
public ref class Point
{
int x;
int y;
public:
//定義讀寫訪問器
property int X
{
int get() { return x; }
void set(int val) { x = val; }
}
property int Y
{
int get() { return y; }
void set(int val) { y = val; }
}
// ...
void Move(int xor, int yor)
{
/*1a*/ Monitor::Enter(this);
X = xor;
Y = yor;
/*1b*/ Monitor::Exit(this);
}
virtual bool Equals(Object^ obj) override
{
// ...
if (GetType() == obj->GetType())
{
int xCopy1, xCopy2, yCopy1, yCopy2;
Point^ p = static_cast<Point^>(obj);
/*2a*/ Monitor::Enter(this);
xCopy1 = X;
xCopy2 = p->X;
yCopy1 = Y;
yCopy2 = p->Y;
/*2b*/ Monitor::Exit(this);
return (xCopy1 == xCopy2) && (yCopy1 == yCopy2);
}
return false;
}
virtual int GetHashCode() override
{
int xCopy;
int yCopy;
/*3a*/ Monitor::Enter(this);
xCopy = X;
yCopy = Y;
/*3b*/ Monitor::Exit(this);
return xCopy ^ (yCopy << 1);
}
virtual String^ ToString() override
{
int xCopy;
int yCopy;
/*4a*/ Monitor::Enter(this);
xCopy = X;
yCopy = Y;
/*4b*/ Monitor::Exit(this);
return String::Concat("(", xCopy, ",", yCopy, ")");
}
};
public ref class ThreadY
{
Point^ pnt;
bool mover;
public:
ThreadY(bool isMover, Point^ p)
{
mover = isMover;
pnt = p;
}
void StartUp()
{
if (mover)
{
for (int i = 1; i <= 10000000; ++i)
{
/*1*/ pnt->Move(i, i);
}
}
else
{
for (int i = 1; i <= 10; ++i)
{
/*2*/ Console::WriteLine(pnt); // calls ToString
Thread::Sleep(10);
}
}
}
};
int main()
{
Point^ p = gcnew Point;
/*1*/ ThreadY^ o1 = gcnew ThreadY(true, p);
/*2*/ Thread^ t1 = gcnew Thread(gcnew ThreadStart(o1, &ThreadY::StartUp));
/*3*/ ThreadY^ o2 = gcnew ThreadY(false, p);
/*4*/ Thread^ t2 = gcnew Thread(gcnew ThreadStart(o2, &ThreadY::StartUp));
t1->Start();
t2->Start();
Thread::Sleep(100);
/*5*/ Console::WriteLine("x: {0}", p->X);
/*6*/ Console::WriteLine("y: {0}", p->Y);
/*7*/ t1->Join();
t2->Join();
}
調用Sleep休眠100毫秒的目的是為了在可以訪問x與y坐標之前,讓兩個線程開始執行,這就是說,我們想要主線程與其他兩個線程競爭坐標值的獨占訪問。
對Thread::Join的調用將會掛起調用線程,直到Join調用的線程結束。
請看例2中的ThreadY類,當一個線程調用標記1中的Move,而另一個線程隱式地調用標記2中的ToString時,潛在的沖突就發生了。因為兩個函數沒有用同步措施來訪問同一個Point,Move可能會先更新x坐標,但在它更新相應的y坐標之前,ToString卻顯示了一對錯誤的坐標值,這時,輸出可能會如插2a所示。然而,當相關的語句被同步之後,ToString顯示的坐標對總是正確匹配的,同步執行之後的輸出如插2b所示。再看一下例2中的Point類型,在此可看到這些訪問x與y坐標的函數是如何被同步的。
插2:a線程輸出產生了不匹配的坐標對;b同步執行中匹配的坐標對
(a)
(1878406,1878406)
(2110533,2110533)
(2439367,2439367)
(2790112,2790112)
x: 3137912
y: 3137911 // y與x不同
(3137912,3137911) // y與x不同
(3466456,3466456)
(3798720,3798720)
(5571903,5571902) // y與x不同
(5785646,5785646)
(5785646,5785646)
(b)
(333731,333731)
(397574,397574)
(509857,509857)
(967553,967553)
x: 853896
y: 967553 // y仍與x不同
(1619521,1619521)
(1720752,1720752)
(1833313,1833313)
(2973291,2973291)
(3083198,3083198)
(3640996,3640996)
在此,可把一段語句放在一個稱作"同步鎖"--即Thread::Monitor的Enter與Exit語句當中,來進行對某些資源的獨占式訪問,如標記1a與1b、2a與2b、3a與3b、4a與4b。
因為Move與ToString都是實例函數,當它們在同一Point上被調用時,它們共享Point的同步鎖,為獨占訪問一個對象,就必須傳遞一個指向對象的句柄給Enter。如果在ToString訪問時,Move也被調用操作同一Point,Move將會一直處於阻塞狀態,直至ToString完成,反之亦然。結果就是,函數花費時間在相互等待,反之沒有同步,它們都會盡可能快地同時運行。
一旦同步鎖控制了對象,它將保證在同一時刻,只有一個此類的實例函數可以在對象上執行它的關鍵代碼。當然,類中沒有使用同步鎖的其他實例函數,可不會理會它的同步"兄弟"在做些什麼,所以,必須小心適當地使用同步鎖(注意,X與Y的訪問器未被同步)。同步鎖對於那些操作不同對象的實例函數,將不起任何作用,這些函數不會互相等待。
通常地,當調用Exit時,同步鎖就被釋放了,因此,同步鎖的作用范圍就是Enter與Exit中間的那些代碼,程序員必須有責任避免死鎖問題的發生--防止線程A一直等待線程B,或反之。
假設有一個包含25條語句的函數,其中只有3條連貫的語句需要同步,如果我們把全部的25條語句都包括在一個同步鎖中,那麼,將把資源比實際所需鎖住了更長的時間。正如前述代碼所示,每個同步鎖保持的時間都要盡可能地短。
請看例3中的ArrayManip結構,當同步鎖執行到標記2時,鎖中的array正處於忙碌狀態,因此將會阻塞其他所有在array上需要同步的代碼。
例3:
using namespace System;
using namespace System::Threading;
public ref struct ArrayManip
{
static int TotalValues(array<int>^ array)
{
/*1*/ int sum = 0;
/*2*/ Monitor::Enter(array);
{
for (int i = 0; i < array->Length; ++i)
{
sum += array[i];
}
}
Monitor::Exit(array);
return sum;
}
static void SetAllValues(array<int>^ array, int newValue)
{
/*3*/ Monitor::Enter(array);
{
for (int i = 0; i < array->Length; ++i)
{
array[i] = newValue;
}
}
Monitor::Exit(array);
}
static void CopyArrays(array<int>^ array1, array<int>^ array2)
{
/*4*/ Monitor::Enter(array1);
{
/*5*/ Monitor::Enter(array2);
{
Array::Copy(array1, array2,
array1->Length < array2->Length ? array1->Length
: array2->Length);
}
Monitor::Exit(array2);
}
Monitor::Exit(array1);
}
};
一個同步鎖可包含同一對象的另一個同步鎖,在這種情況下,鎖計數相應地增長了;但如果想被另一個線程中的同步語句操作,必須先遞減到零。一個同步鎖還可包含不同對象的同步鎖,在此情況下,它將會一直阻塞,直到第二個對象可訪問,函數CopyArrays就是一個例子。
一般來說,使用同步鎖的目的,是為了使用父類函數的實例對象,然而,我們在不需要這些對象實際包含任何信息的情況下,也能"創造"出鎖對象和同步機制。請看例4,類C有一個名為Lock的同步鎖,其並未包含任何數據,且除了一個同步鎖外,從未進行初始化或使用在任何上下文中。但在函數F3與F4中,則分別包含了一些語句,各自在運行時必須阻塞對方的運行。
例4:
using namespace System::Threading;
public ref class C
{
/*1*/ static Object^ Lock = gcnew Object;
public:
static void F1()
{
/*2*/ Monitor::Enter(C::typeid);
/*3*/ try {
//執行一些操作
}
finally {
Monitor::Exit(C::typeid);
}
}
static void F2()
{
Monitor::Enter(C::typeid);
// ...
Monitor::Exit(C::typeid);
}
static void F3()
{
/*4*/ Monitor::Enter(Lock);
// ...
Monitor::Exit(Lock);
}
static void F4()
{
Monitor::Enter(Lock);
// ...
Monitor::Exit(Lock);
}
};
如果一個類函數(而不是一個實例函數)需要同步,可使用typeid操作符來包含一個鎖對象,如標記2中所示。對每個CLI類型而言,都有一個鎖對象,同樣,對類型的每個實例而言,也有一個鎖對象。類上的同步鎖意味著在同一時刻,只能執行一個類函數。
注意標記3中的try/finally,一般而言,如果同步鎖中的執行正常完成,將如前面的例子一樣,正常地調用Monitor::Exit;但是,如果在同步鎖中拋出了一個異常,將不會調用到Exit,因為正常的執行流程已經被中斷了。那麼我們要做的就是,如果同步鎖中可能存在一絲機會發生異常--不管是同步鎖中直接或是間接調用的任何函數,我們都必須加上try/finally語句塊,這樣的話,不管是同步鎖的正常或非正常退出,都會調用到Exit了。