C++中的函數新特性:先來速成新特性1. 內聯函數,說到內聯函數,不得不提和它類似的一個東西先。
#define F(x) ((x)*(x))
沒錯,就是宏定義。
在程序編譯過程中,F(x)會自動替換成((x)*(x))
從而在程序中F(x)就像一個函數一樣
C++中當然也有宏定義
不過有一個新特性
能夠得到與此類似的實現
inline int F(int x)
{
return x*x;
}
和普通函數的定義幾乎一模一樣,不過就是在聲明語句前面加了一個詞
inline
作用:和宏定義類似,在函數調用的地方,
編譯器將會使用相應的函數代碼替換函數的調用
也就是在編譯階段就替換代碼,
實際運行的時候已經沒有函數調用了
這一點是和宏定義類似的
在C++的函數中,我們可以在聲明的時候添加默認值
先 放碼過來 展示下語法
如下面
這是函數原型:
int function(int a = 2)
這是函數定義:
int function(int a)
{
return a*a;
}
然後在調用函數的時候,我們可以這樣
function(6); //返回36 function(4); //返回16 function(); //返回4
嗯??第三條語句並沒有傳遞參數呀?
在沒有傳遞參數的時候
函數會自動采用在聲明時使用的默認值
C++中,是允許同名函數的存在的
在調用函數的時候,
會根據函數的形參列表選擇其中一個執行
所謂函數重載便是如此
例:我們可以定義這樣一組函數
void print(int a); void print(int a,int b); void print(double a); void print(int a, double b); void print(doubla a, int b);
然後我們在調用函數的時候
print (3);// 調用第一個 print (3,4); //調用第二個 print (3.0); //調用第三個 print (3,2.0); //調用第四個 print (2.0, 2); //調用第五個
這幾個調用都會調用不同的函數
如果我要打一個交換兩個int變量的函數
我可以這樣
void swap(int & a, int & b)
{
int temp;
temp = a;
a = b;
b = temp;
}
如果我還要打一個交換double變量的呢?
如果我還要交換long變量呢?
我是不是都要打一個swap函數!!
好煩!!
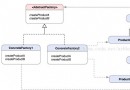
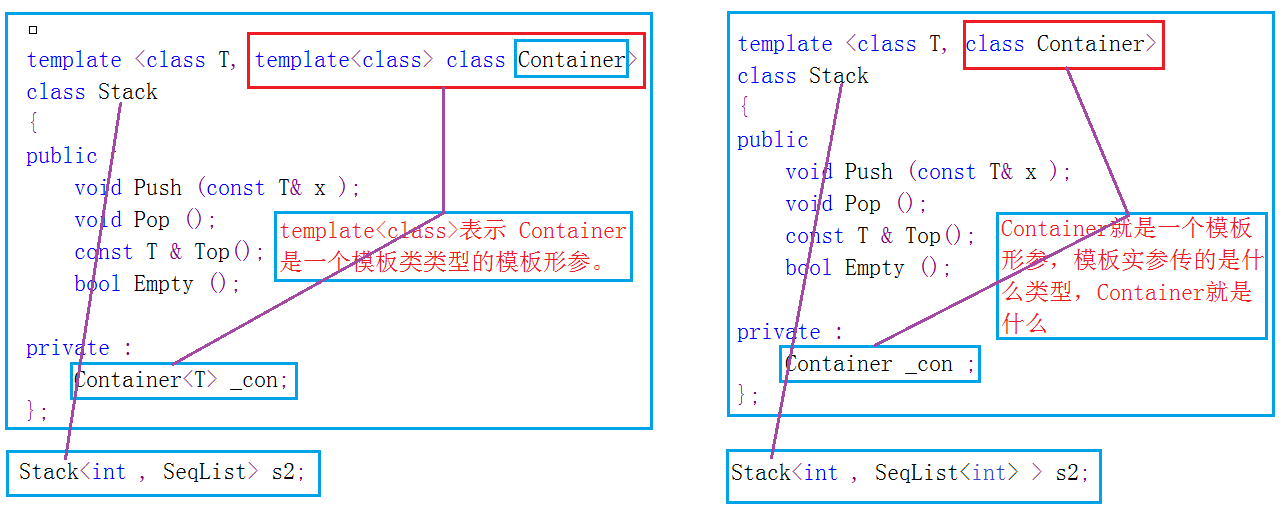
函數模板,就是為了解決你這樣的煩惱而來
且看下面
templatevoid swap(T & a, T & b) { T temp; temp = a; a = b; b = temp; }
關鍵字:template(模板)
關鍵字:typename
第一行,指出這是一個函數模板
一個可替代的變量類型,我們暫且命名為T
然後後面函數的定義
就用T來代替具體的類型
之後我們的函數調用
就可以用這一個swap函數,去交換int變量
去交換double變量
實際上函數模板就是在編譯的時候
將T換成所需要的類型
就像 typedef T int ;一樣
下面是一些比較細的注意事項
最好邊看邊打碼邊實踐
函數的調用原理
函數調用時
需要程序在運行時跳到調用函數所在地址
然後執行函數後,跳回上一級並且返回值
在這一跳一跳的過程
需要做很多事情
宏定義和內聯函數
都通過直接替換代碼的做法
避免了常規的函數調用
節省了計算資源和存儲空間
#define F(x) ((x)*(x))
就如同這條宏定義
為什麼要加這麼多括號呢?
(希望能夠自己思考一下)
如果不加
當我們使用F(x+1)
宏定義會替換成 x+1 * x+1
明顯不能算出我們所期待的x+1 的平方
再如,如果在含有這條宏定義的程序中
我們這樣
F(c++);
又會發生什麼呢?
替換後會變成
c++ * c++
結果不好確定
而且c還被加了兩遍
一定不會是自己所期望自己的結果
返回c的平方後c++;
這些種種弊端,內聯函數都不存在
只管當普通函數用就好啦
假設有這樣的一個函數原型
int function (int a, int b = 3, int c )
我這樣調用
function(2,4);
這是想做什麼呢?
是因為b有了默認值,想只給a和c賦值嗎?
但是
實參按從左向右的順序依次賦給對應的形參
也就是說
2 會賦給 a , 4 會賦給 b,
不會跳過默認值
不過,我們可以這樣修改函數原型
int function (int a, int c , int b = 3)
這樣就沒有問題了
所以,默認值從右往左添加
這個注意事項相信大家再看會該節開頭的例子就懂了
這是函數原型:
int function(int a = 2)
這是函數定義:
int function(int a)
{
return a*a;
}
先明白一個概念:函數的特征標
函數特征標
對於相同名字的函數
函數的特征標由函數定義的形參列表決定
例:
int function (int , int );
int function (double );
第一個函數的形參列表為(int, int)
第二個函數的形參列表為(double)
所以雖然相同名字,這是兩個不同的函數
void print(int a); void print (const int a);
這個是不可以的,
void print (int & a); void print (const int & a);
這個是可以的
void print (int * a); void print (const int * a);
這個也是可以的
我其實很想解釋解釋為什麼可以為什麼不可以的
然後發現我不會解釋
不過在DEV上親測過
void print (int a); void print (int & a);
這兩個是無法重載的
假設這裡定義了這樣的函數
void print (int a, double = 3);
void print (int b);
這兩個當然是不同的函數,當然可以重載
可是,如果我這樣調用函數
print(3);
對於第一個版本,當然可以使用,因為第二個參數默認為3,可以省略
對於第二個版本,毫無疑問可以使用
這下子怎麼辦????
編譯器就會報錯
這就叫做具有二義性
二義性是指
訪問同名成員的不確定性
包括訪問函數,訪問類成員。。。
在類型轉換中,同樣可能會有二義性
例子:這裡定義了這幾個函數
void print (int a); void print (double a);
然後
unsigned int u = 3; print(u);
會發生什麼?
這裡沒有一個函數與u匹配,
因此u會嘗試類型轉換從而匹配
u既可以轉為int類型也可以轉為double類型
出現二義性
編譯器無法確定
報錯
明天再細寫函數模板吧
真是一個大坑