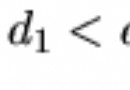Species Tree 應用HashTable完成實例代碼。本站提示廣大學習愛好者:(Species Tree 應用HashTable完成實例代碼)文章只能為提供參考,不一定能成為您想要的結果。以下是Species Tree 應用HashTable完成實例代碼正文
Species Tree 應用HashTable完成
標題再現
標題內容:
給定一個物種演化圖, 關系的表示方式如下: x y : 表示x為y的先祖。 一個物種只會有一個先祖, 一個先祖可以有很多個演化出來的物種, 請你找出每個問題訊問物種的祖父物種(先祖的先祖), 每個物種會運用一個不反復的編號來表示, 假如該物種沒有祖父物種的話或是不存在, 那麼請將他的祖父物種當是0。(憑空而生) 保證一切物種間一定有所關連, 且不會有反復演化的景象發作, 即演化圖只會是一棵樹。 輸出格式: 只要一組測資。 第一行會有兩個數字N、Q,代表總共有N個物種及Q個問題。 接上去N-1行,每一行有兩個數字x、y, 意義如標題所述。 接上去的Q行,每一行有一個數字Z, 代表要訊問的物種編號。 測資范圍: 1 < N < 10000 0 < Q < 1000 0 < x, y, z < 1000000 輸入格式: 關於每一個訊問的物種編號,將他們的祖父物種編號加總後再輸入。 輸出樣例: 6 3 1000 2000 1000 3000 2000 4000 3000 5000 5000 6000 5000 6000 1234 輸入樣例: 4000 時間限制:100ms內存限制:16000kb
算法完成
1. 復雜數組下標查找法
經過標題的要求,這裡可以運用最復雜的辦法,由於輸出的x , y中,y的值是確定不變的,所以這裡可以定義一個y的取值范圍那麼大的數組,下標就是y的值,內容就是x的值,這樣查找起來非常方便,時間復雜度是O(1),但是空間上就會糜費比擬多了。
#include <stdio.h>
#include <string.h>
int main(){
int arrBucket[1000000];
int N, Q;
int x, y, z;
long long sum = 0;
memset(arrBucket, 0, sizeof(arrBucket));
scanf("%d %d", &N, &Q);
while(N -- > 1){
scanf("%d %d", &x, &y);
arrBucket[y] = x;
}
while(Q --){
scanf("%d", &z);
if(arrBucket[z] != 0){
if(arrBucket[arrBucket[z]] != 0){
sum += arrBucket[arrBucket[z]];
}
}
}
printf("%lld", sum);
return 0;
}
2. Hash表完成
由於辦法1中,糜費空間嚴重,所以這裡運用Hash表完成。
#include <stdio.h>
#include <stdlib.h>
#define NULLKEY -1
typedef struct {
int *elem; //元素
int *elemP; //父元素
int count;
}HashTable;
int Hash(HashTable H, int k){
return k % H.count;
}
void InitHashTable(HashTable *H){
int i;
H->elem = (int *)malloc(sizeof(int) * H->count);
H->elemP = (int *)malloc(sizeof(int) * H->count);
for(i = 0; i < H->count; i ++){
H->elem[i] = NULLKEY;
H->elemP[i] = NULLKEY;
}
}
void InsertHash(HashTable *H, int key, int value){
int addr;
addr = Hash(*H, key);
while(H->elem[addr] != NULLKEY){
addr = (addr + 1) % H->count;
}
H->elem[addr] = key;
H->elemP[addr] = value;
}
int FindHash(HashTable *H, int key, int *addr){
*addr = Hash(*H, key);
while(H->elem[*addr] != key){
*addr = (*addr + 1) % H->count;
if(H->elem[*addr] == NULLKEY || *addr == Hash(*H, key)){
return 0;
}
}
return 1;
}
int main(){
int N, Q;
int x, y, z, addr;
long long sum = 0;
HashTable H;
scanf("%d %d", &N, &Q);
H.count = N - 1;
InitHashTable(&H);
while(N -- > 1){
scanf("%d %d", &x, &y);
InsertHash(&H, y, x);
}
while(Q --){
scanf("%d", &z);
if(FindHash(&H, z, &addr)){
if(FindHash(&H, H.elemP[addr], &addr)){
sum += H.elemP[addr];
}
}
}
printf("%lld", sum);
return 0;
}
3. 用C++的map來完成
看著用C完成起來,絕對來說完成的各個功用都要自己寫,這裡看一下用C++的STL外面的map來完成下面的標題,十分復雜(不得不說STL真的很好用,但是不如HashTable速度快,空間上也不如HashTable占用的小)
#include <iostream>
#include <map>
using namespace std;
int main() {
int n, q;
cin >> n >> q;
map<int,int> mp;
map<int,int>::iterator it;
int x, y, z;
for (int i=1; i<n; ++i) {
cin >> x >> y;
mp.insert(pair<int,int>(y,x));
}
int sum = 0;
for (int i=0; i<q; ++i) {
cin >> z;
it = mp.find(z);
if (it != mp.end()) {
it = mp.find(it->second);
if (it != mp.end())
sum += it->second;
}
}
cout << sum;
return 0;
}
感激閱讀,希望能協助到大家,謝謝大家對本站的支持!