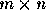增加C++代碼編譯時間的復雜辦法(必看篇)。本站提示廣大學習愛好者:(增加C++代碼編譯時間的復雜辦法(必看篇))文章只能為提供參考,不一定能成為您想要的結果。以下是增加C++代碼編譯時間的復雜辦法(必看篇)正文
c++ 的代碼包括頭文件和完成文件兩局部, 頭文件普通是提供應他人(也叫客戶)運用的, 但是一旦頭文件發作改動,不論多小的變化,一切援用他的文件就必需重新編譯,編譯就要花時間,假設你做的工程比擬大(比方二次封裝chrome這類的開發),重新編譯一次的時間就會糜費下班的大局部時間,這樣干了一天挺累的, 但是你的老板說你沒有產出,後果你被fired, 是不是很怨啊, 假如你早點看到這段文章,你就會比你的同事開發效率高那麼一些,那樣被fired就不會是你了,你說這篇文章是不是價值千金!開個玩笑 :)
言歸正傳,怎樣引見編譯時間呢, 我知道的就3個方法:
1. 刪除不用要的#include,替代方法 運用前向聲明 (forward declared )
2. 刪除不用要的一大堆公有成員變量,轉而運用 "impl" 辦法
3. 刪除不用要的類之間的承繼
為了講清楚這3點,還是舉個實例比擬好,這個實例我會一步一步的改良(由於我也是一點一點探索出來了,假如哪裡說錯了, 你就擔心的噴吧,我會和你在爭論究竟的,呵呵)
如今先假定你找到一個新任務,接手以前某個順序員寫的類,如下
// old.h: 這就是你接納的類
//
#include <iostream>
#include <ostream>
#include <list>
// 5 個 辨別是file , db, cx, deduce or error , 程度無限沒有模板類
// 只用 file and cx 有虛函數.
#include "file.h" // class file
#include "db.h" // class db
#include "cx.h" // class cx
#include "deduce.h" // class deduce
#include "error.h" // class error
class old : public file, private db {
public:
old( const cx& );
db get_db( int, char* );
cx get_cx( int, cx );
cx& fun1( db );
error fun2( error );
virtual std::ostream& print( std::ostream& ) const;
private:
std::list<cx> cx_list_;
deduce deduce_d_;
};
inline std::ostream& operator<<( std::ostream& os,const old& old_val )
{ return old_val.print(os); }
這個類看完了, 假如你曾經看出了問題出在哪裡, 接上去的不必看了, 你是高手, 這些根本知識對你來說太小兒科,要是像面試時被問住了愣了一下,請接著看吧
先看怎樣運用第一條: 刪除不用要的#include
這個類援用 5個頭文件, 那意味著那5個頭文件所援用的頭文件也都被援用了出去, 實踐上, 不需求援用5 個,只需援用2個就完全可以了
1.刪除不用要的#include,替代方法 運用前向聲明 (forward declared )
1.1刪除頭文件 iostream, 我剛開端學習c++ 時照著《c++ primer》 抄,只需看見關於輸出,輸入就把 iostream 頭文件加上, 幾年過來了, 如今我知道不是這樣的, 這裡只是定義輸入函數, 只需援用ostream 就夠了
1.2.ostream頭文件也不要, 交換為 iosfwd , 為什麼, 緣由就是, 參數和前往類型只需前向聲明就可以編譯經過, 在iosfwd 文件裡 678行(我的環境是vs2013,不同的編譯環境詳細地位能夠會不相反,但是都有這句聲明) 有這麼一句
typedef basic_ostream<char, char_traits<char> > ostream;
inline std::ostream& operator<<( std::ostream& os,const old& old_val )
{ return old_val.print(os); }
除此之外,要是你說這個函數要操作ostream 對象, 那還是需求#include <ostream> , 你只說對了一半, 確實, 這個函數要操作ostream 對象, 但是請看他的函數完成,
外面沒有定義一個相似 std::ostream os, 這樣的語句,話說回來,凡是呈現這樣的定義語句, 就必需#include 相應的頭文件了 ,由於這是懇求編譯器分配空間,而假如只前向聲明 class XXX; 編譯器怎樣知道分配多大的空間給這個對象!
看到這裡, old.h頭文件可以更新如下了:
// old.h: 這就是你接納的類
//
#include <iosfwd> //新交換的頭文件
#include <list>
// 5 個 辨別是file , db, cx, deduce or error , 程度無限沒有模板類
// 只用 file and cx 有虛函數.
#include "file.h" // class file , 作為基類不能刪除,刪除了編譯器就不知道實例化old 對象時分配多大的空間了
#include "db.h" // class db, 作為基類不能刪除,同上
#include "cx.h" // class cx
#include "deduce.h" // class deduce
// error 只被用做參數和前往值類型, 用前向聲明交換#include "error.h"
class error;
class old : public file, private db {
public:
old( const cx& );
db get_db( int, char* );
cx get_cx( int, cx );
cx& fun1( db );
error fun2( error );
virtual std::ostream& print( std::ostream& ) const;
private:
std::list<cx> cx_list_; // cx 是模版類型,既不是函數參數類型也不是函數前往值類型,所以cx.h 頭文件不能刪除
deduce deduce_d_; // deduce 是類型定義,也不刪除他的頭文件
};
inline std::ostream& operator<<( std::ostream& os,const old& old_val )
{ return old_val.print(os); }
到目前為止, 刪除了一些代碼, 是不是心境很爽,聽說看一個順序員的程度有多高, 不是看他寫了多少代碼,而是看他少寫了多少代碼。
假如你對C++ 編程有更深一步的興味, 接上去的文字你還是會看的,再進一步刪除代碼, 但是這主要另辟蹊徑了
2. 刪除不用要的一大堆公有成員變量,轉而運用 "impl" 辦法
2.1.運用 "impl" 完成方式寫代碼,增加客戶端代碼的編譯依賴
impl 辦法復雜點說就是把 類的公有成員變量全部放進一個impl 類, 然後把這個類的公有成員變量只保存一個impl* 指針,代碼如下
// file old.h
class old {
//私有和維護成員
// public and protected members
private:
//公有成員, 只需恣意一個的頭文件發作變化或成員個數添加,增加,一切援用old.h的客戶端必需重新編譯
// private members; whenever these change,
// all client code must be recompiled
};
改寫成這樣:
// file old.h
class old {
//私有和維護成員
// public and protected members
private:
class oldImpl* pimpl_;
// 交換原來的一切公有成員變量為這個impl指針,指針只需求前向聲明就可以編譯經過,這種寫法將前向聲明和定義指針放在了一同, 完全可以。
//當然,也可以分開寫
// a pointer to a forward-declared class
};
// file old.cpp
struct oldImpl {
//真正的成員變量隱藏在這裡, 隨意變化, 客戶端的代碼都不需求重新編譯
// private members; fully hidden, can be
// changed at will without recompiling clients
};
不知道你看明白了沒有, 看不明白請隨意寫個類實驗下,我就是這麼做的,當然凡事也都有優缺陷,上面復雜比照下:
運用impl 完成類
不運用impl完成類
優點
類型定義與客戶端隔離, 增加#include 的次數,進步編譯速度,庫端的類隨意修正,客戶端不需求重新編譯
直接,復雜明了,不需求思索堆分配,釋放,內存走漏問題
缺陷
關於impl的指針必需運用堆分配,堆釋放,時間長了會發生內存碎片,最終影響順序運轉速度, 每次調用一個成員函數都要經過impl->xxx()的一次轉發
庫端恣意頭文件發作變化,客戶端都必需重新編譯
改為impl完成後是這樣的:
// 只用 file and cx 有虛函數.
#include "file.h"
#include "db.h"
class cx;
class error;
class old : public file, private db {
public:
old( const cx& );
db get_db( int, char* );
cx get_cx( int, cx );
cx& fun1( db );
error fun2( error );
virtual std::ostream& print( std::ostream& ) const;
private:
class oldimpl* pimpl; //此處前向聲明和定義
};
inline std::ostream& operator<<( std::ostream& os,const old& old_val )
{ return old_val.print(os); }
//implementation file old.cpp
class oldimpl{
std::list<cx> cx_list_;
deduce dudece_d_;
};
3. 刪除不用要的類之間的承繼
面向對象提供了承繼這種機制,但是承繼不要濫用, old class 的承繼就屬於濫用之一, class old 承繼file 和 db 類, 承繼file是私有承繼,承繼db 是公有承繼,承繼file 可以了解, 由於file 中有虛函數, old 要重新定義它, 但是依據我們的假定, 只要file 和 cx 有虛函數,公有承繼db 怎樣解釋?! 那麼獨一能夠的理由就是:
經過 公有承繼—讓某個類不能當作基類去派生其他類,相似Java裡final關鍵字的功用,但是從實例看,顯然沒有這個意圖, 所以這個公有承繼完全不用要, 應該改用包括的方式去運用db類提供的功用, 這樣就可以
把"db.h"頭文件刪除, 把db 的實例也可以放進impl類中,最終失掉的類是這樣的:
// 只用 file and cx 有虛函數.
#include "file.h"
class cx;
class error;
class db;
class old : public file {
public:
old( const cx& );
db get_db( int, char* );
cx get_cx( int, cx );
cx& fun1( db );
error fun2( error );
virtual std::ostream& print( std::ostream& ) const;
private:
class oldimpl* pimpl; //此處前向聲明和定義
};
inline std::ostream& operator<<( std::ostream& os,const old& old_val )
{ return old_val.print(os); }
//implementation file old.cpp
class oldimpl{
std::list<cx> cx_list_;
deduce dudece_d_;
};
小結一下:
這篇文章只是復雜的引見了增加編譯時間的幾個方法:
1. 刪除不用要的#include,替代方法 運用前向聲明 (forward declared )
2. 刪除不用要的一大堆公有成員變量,轉而運用 "impl" 辦法
3. 刪除不用要的類之間的承繼
這幾條希望對您有所協助, 假如我哪裡講的不夠清楚也可以參考附件,哪裡有完好的實例,也歡送您發表評論, 大家一同討論提高,哦不,加薪。 呵呵,在下篇文章我將把impl完成方式再詳細剖析下,等待吧...
以上就是為大家帶來的增加C++代碼編譯時間的復雜辦法(必看篇)全部內容了,希望大家多多支持~