c++完成的罕見緩存算法和LRU。本站提示廣大學習愛好者:(c++完成的罕見緩存算法和LRU)文章只能為提供參考,不一定能成為您想要的結果。以下是c++完成的罕見緩存算法和LRU正文
前言
關於web開發而言,緩存必不可少,也是進步功能最常用的方式。無論是閱讀器緩存(假如是chrome閱讀器,可以經過chrome:://cache檢查),還是服務端的緩存(經過memcached或許redis等外存數據庫)。緩存不只可以減速用戶的訪問,同時也可以降低服務器的負載和壓力。那麼,理解罕見的緩存淘汰算法的戰略和原理就顯得特別重要。
罕見的緩存算法
LRU緩存
像閱讀器的緩存戰略、memcached的緩存戰略都是運用LRU這個算法,LRU算法會將近期最不會訪問的數據淘汰掉。LRU如此盛行的緣由是完成比擬復雜,而且關於實踐問題也很適用,良好的運轉時功能,命中率較高。上面談談如何完成LRU緩存:
LRU Cache具有的操作:
LRU的c++完成
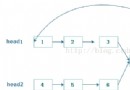
LRU完成采用雙向鏈表 + Map 來停止完成。這裡采用雙向鏈表的緣由是:假如采用普通的單鏈表,則刪除節點的時分需求從表頭開端遍歷查找,效率為O(n),采用雙向鏈表可以直接改動節點的前驅的指針指向停止刪除到達O(1)的效率。運用Map來保管節點的key、value值便於能在O(logN)的時間查找元素,對應get操作。
雙鏈表節點的定義:
struct CacheNode {
int key; // 鍵
int value; // 值
CacheNode *pre, *next; // 節點的前驅、後繼指針
CacheNode(int k, int v) : key(k), value(v), pre(NULL), next(NULL) {}
};
關於LRUCache這個類而言,結構函數需求指定容量大小
LRUCache(int capacity)
{
size = capacity; // 容量
head = NULL; // 鏈表頭指針
tail = NULL; // 鏈表尾指針
}
雙鏈表的節點刪除操作:
void remove(CacheNode *node)
{
if (node -> pre != NULL)
{
node -> pre -> next = node -> next;
}
else
{
head = node -> next;
}
if (node -> next != NULL)
{
node -> next -> pre = node -> pre;
}
else
{
tail = node -> pre;
}
}
將節點拔出到頭部的操作:
void setHead(CacheNode *node)
{
node -> next = head;
node -> pre = NULL;
if (head != NULL)
{
head -> pre = node;
}
head = node;
if (tail == NULL)
{
tail = head;
}
}
get(key)操作的完成比擬復雜,直接經過判別Map能否含有key值即可,假如查找到key,則前往對應的value,否則前往-1;
int get(int key)
{
map<int, CacheNode *>::iterator it = mp.find(key);
if (it != mp.end())
{
CacheNode *node = it -> second;
remove(node);
setHead(node);
return node -> value;
}
else
{
return -1;
}
}
set(key, value)操作需求分狀況判別。假如以後的key值對應的節點曾經存在,則將這個節點取出來,並且刪除節點所處的原有的地位,並在頭部拔出該節點;假如節點不存在節點中,這個時分需求在鏈表的頭部拔出新節點,拔出新節點能夠招致容量溢出,假如呈現溢出的狀況,則需求刪除鏈表尾部的節點。
void set(int key, int value)
{
map<int, CacheNode *>::iterator it = mp.find(key);
if (it != mp.end())
{
CacheNode *node = it -> second;
node -> value = value;
remove(node);
setHead(node);
}
else
{
CacheNode *newNode = new CacheNode(key, value);
if (mp.size() >= size)
{
map<int, CacheNode *>::iterator iter = mp.find(tail -> key);
remove(tail);
mp.erase(iter);
}
setHead(newNode);
mp[key] = newNode;
}
}
總結
好了,至此,LRU算法的完成操作就完成了,希望本文的內容對大家的學習或許任務能帶來一定的協助,假如有疑問大家可以留言交流。