解析四則表達式的編譯進程及生成匯編代碼。本站提示廣大學習愛好者:(解析四則表達式的編譯進程及生成匯編代碼)文章只能為提供參考,不一定能成為您想要的結果。以下是解析四則表達式的編譯進程及生成匯編代碼正文

test1.c文件用代碼表現以下:
#ifndef TEST1_C
#define TEST1_C
/**
* 采取狀況圖停止詞法剖析和測試詞法剖析
*
**/
#include"test.c"
//列舉類型
typedef enum Symbol { ERR = -1, END, NUM, PLUS, MINUS, TIMES,
SLASH, LPAREN, RPAREN } Symbol;
//獲得一個單詞符號,該單詞符號寄存在strToken中。前往該單詞符號的列舉類型
Symbol getToken();
//依據傳入的列舉類型輸入對應的單詞符號
void printToken(Symbol i);
//測試詞法剖析
void testLexAnalyse();
//獲得一個單詞符號,該單詞符號寄存在strToken中。前往該單詞符號的列舉類型
Symbol getToken()
{
char ch;
int state=0;//每次都是從狀況0開端
int j=0;
//表達式遍歷完成,單詞符號為'#'
if(expression[expression_index]=='\0'){
strToken[0]='#';
strToken[1]='\0';
return END;
}
while(1){
switch(state){
case 0:
//讀取一個字符
ch=strToken[j++]=expression[expression_index++];
if(isspace(ch)){
j--;//留意退格
state=0;
}
else if(isdigit(ch))
state=1;
else if(ch=='+')
state=2;
else if(ch=='-')
state=3;
else if(ch=='*')
state=4;
else if(ch=='/')
state=5;
else if(ch=='(')
state=6;
else if(ch==')')
state=7;
else
return ERR;
break;
case 1:
ch=strToken[j++]=expression[expression_index++];
if(isdigit(ch))
state=1;
else{
expression_index--;
strToken[--j]=0;
return NUM;
}
break;
case 2:
strToken[j]=0;
return PLUS;
case 3:
strToken[j]=0;
return MINUS;
case 4:
strToken[j]=0;
return TIMES;
case 5:
strToken[j]=0;
return SLASH;
case 6:
strToken[j]=0;
return LPAREN;
case 7:
strToken[j]=0;
return RPAREN;
}
}
}
//依據傳入的列舉類型輸入對應的單詞符號
void printToken(Symbol i){
switch(i){
case -1:printf("ERR\n");break;
case 0:printf("END\n");break;
case 1:printf("NUM %s\n",strToken);break;
case 2:printf("PLUS %s\n",strToken);break;
case 3:printf("MINUS %s\n",strToken);break;
case 4:printf("TIMES %s\n",strToken);break;
case 5:printf("SLASH %s\n",strToken);break;
case 6:printf("LPAREN %s\n",strToken);break;
case 7:printf("RPAREN %s\n",strToken);break;
}
}
//測試詞法剖析
void testLexAnalyse()
{
Symbol tokenStyle;//單詞符號類型
expression_index=0;
puts("\n詞法剖析成果以下:");
while(1){
tokenStyle=getToken();
printToken(tokenStyle);
if(tokenStyle == ERR){
error("詞法剖析毛病!");
}
if(tokenStyle == END){
break;
}
}
}
//主函數
int main()
{
gets(expression);
testLexAnalyse();
return 0;
}
#endif
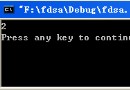
運轉成果
5、語法剖析
請求:接收一個表達式,剖析該表達式,並依據輸出准確與否給出響應信息
重要是依據無左遞歸文法寫出對應的各個子法式
test2.c
#ifndef TEST_2
#define TEST_2
/**
* 語法剖析和測試語法剖析
**/
#include"test1.c"
/*
清除左遞歸後的文法:
E→TE'
E'→+TE' |ε
T→FT'
T'→*FT' |ε
F→(E) | i
*/
//每一個非終結符有對應的子法式函數聲明
void E();
void E1();
void T();
void T1();
void F();
//測試語法剖析
void testSyntaxAnalyse();
//每一個非終結符有對應的子法式
void E()
{
T();
E1();
}
void E1()
{
if(strcmp(strToken,"+")==0 || strcmp(strToken,"-")==0){
getToken();
T();
E1();
}
//Follow(E1)={#,)}
else if(strcmp(strToken,"#")!=0 && strcmp(strToken,")")!=0){
error("語法剖析毛病!");
}
}
void T()
{
F();
T1();
}
void T1()
{
if(strcmp(strToken,"*")==0 || strcmp(strToken,"/")==0){
getToken();
F();
T1();
}
//Follow(T1)={+,#,)},假如斟酌-號的話要加上-號
else if(strcmp(strToken,"-")!=0 &&strcmp(strToken,"+")!=0 && strcmp(strToken,"#")!=0 && strcmp(strToken,")")!=0){
error("語法剖析毛病!");
}
}
void F()
{
if(isNum(strToken)){
getToken();
}
else{
if(strcmp(strToken,"(")==0){
getToken();
E();
if(strcmp(strToken,")")==0)
getToken();
else
error("語法剖析毛病!");
}
else
error("語法剖析毛病!");
}
}
//測試語法剖析
void testSyntaxAnalyse()
{
expression_index=0;
getToken();
E();
puts("\n語法剖析成果以下:");
if(strcmp(strToken,"#")!=0)
error("語法剖析毛病!");
else{
puts("語法剖析准確!");
}
}
//主函數
int main()
{
gets(expression);
testLexAnalyse();
testSyntaxAnalyse();
return 0;
}
#endif
運轉時要刪失落test1.c中的主函數,運轉成果 
6、語義剖析
請求:須要完成的語義剖析法式的功效是,接收一個表達式,剖析該表達式,並在剖析的進程中樹立該表達式的籠統語法樹。因為四則運算表達式的籠統語法樹可根本上看做是二叉樹,是以中序遍歷序列應當和輸出的表達式一樣——除沒有括號以外。可輸入中序遍歷序列檢測法式功效能否准確。假如每一個分支節點用一個暫時變量標志,則對四則運算表達式的籠統語法樹停止後序遍歷,可以獲得輸出表達式所對應的四元式序列
test3.c文件
#ifndef TEST3_C
#define TEST3_C
/**
* 語義剖析和測試語義剖析
* 其實這個試驗是在test2的代碼長進行修正
**/
#include"test1.c"
/*
清除左遞歸的翻譯形式:
E ::= T {E'.i:=T.nptr}
E' {E.nptr:=E'.s}
E'::= + T {E'1.i:=mknode('+',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= - T {E'1.i:=mknode('-',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= ε {E'.s:= E'.i}
T ::= F {T'.i:=F.nptr}
T' {T.nptr:=T'.s}
T'::= * F {T'1.i:=mknode('*',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T'::= / F {T'1.i:=mknode('/',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T' ::= ε {T'.s:= T'.i}
F ::= (E) {F.nptr:=E.nptr}
F ::= num {F.nptr:=mkleaf(num,num.val)}
*/
#define MAX_LENGTH 20 //四元式中操作數的最年夜長度
typedef int ValType;
//結點類型
typedef struct ASTNode {
Symbol sym;//類型
ValType val;//值
struct ASTNode * left, *right;//左、右孩子
}ASTNode, *AST;
//四元式類型界說以下
typedef struct Quaternion{
char op;
char arg1[MAX_LENGTH];
char arg2[MAX_LENGTH];
char result[MAX_LENGTH];
}Quaternion;
//四元式數組,寄存發生的四元式
Quaternion quaternion[MAX_LENGTH*2];
//統計四元式的個數
int count=0;
//後序遍歷籠統語法樹時寄存操作數和暫時變量,這裡看成一個棧來應用
char stack[MAX_LENGTH*2][MAX_LENGTH];
//stack棧的下標
int index=0;
//內存中暫時數據存儲地址的偏移量
int t=-4;
//函數聲明
ASTNode* E();
ASTNode* E1(ASTNode* E1_i);
ASTNode* T();
ASTNode* T1(ASTNode* T1_i);
ASTNode* F();
void error(char* errerMessage);
ASTNode *mknode(Symbol op, ASTNode *left, ASTNode *right);
ASTNode *mkleaf(Symbol sym, ValType val);
void yuyi_analyse();
void print_node(ASTNode *root);
void middle_list(ASTNode *root);
void last_list(ASTNode *root);
//測試語義剖析
void testYuyiAnalyse();
//創立運算符結點
ASTNode *mknode(Symbol op, ASTNode *left, ASTNode *right);
//創立操作數結點
ASTNode *mkleaf(Symbol sym, ValType val);
//輸入結點
void printNode(ASTNode *root);
//中序遍歷二叉樹
void middle_list(ASTNode *root);
//後序遍歷二叉樹
void last_list(ASTNode *root);
/*
E ::= T {E'.i:=T.nptr}
E' {E.nptr:=E'.s}
*/
//為左邊的每一個非終結符界說一個屬性,前往E的綜合屬性
ASTNode* E()
{
ASTNode * E_nptr;
ASTNode * E1_i;
E1_i=T();
E_nptr=E1(E1_i);
return E_nptr;
}
/*
E'::= + T {E'1.i:=mknode('+',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= - T {E'1.i:=mknode('-',E'.i,T.nptr)}
E'1 {E'.s:=E1.s}
E'::= ε {E'.s:= E'.i}
*/
//前往的是綜合屬性,傳遞的是繼續屬性
ASTNode * E1(ASTNode *E1_i)
{
ASTNode * E11_i;
ASTNode * E1_s;
ASTNode * T_nptr;
char oper;
if(strcmp(strToken,"+")==0 || strcmp(strToken,"-")==0){
oper=strToken[0];
getToken();
T_nptr=T();
if(oper=='+')
E11_i=mknode(PLUS,E1_i,T_nptr);
else
E11_i=mknode(MINUS,E1_i,T_nptr);
E1_s=E1(E11_i);
}
//Follow(E1)={#,)},可以婚配空串
else if(strcmp(strToken,"#")==0 || strcmp(strToken,")")==0){
E1_s=E1_i;
}else{
error("語法剖析毛病!");
}
return E1_s;
}
/*
T ::= F {T'.i:=F.nptr}
T' {T.nptr:=T'.s}
*/
ASTNode* T()
{
ASTNode * T_nptr;
ASTNode * T1_i;
T1_i=F();
T_nptr=T1(T1_i);
return T_nptr;
}
/*
T'::= * F {T'1.i:=mknode('*',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T'::= / F {T'1.i:=mknode('/',T'.i,F.nptr)}
T'1 {T'.s:=T1.s}
T' ::= ε {T'.s:= T'.i}
*/
ASTNode* T1(ASTNode* T1_i)
{
ASTNode* F_nptr;
ASTNode* T11_i;
ASTNode* T1_s;
char oper;
if(strcmp(strToken,"*")==0 || strcmp(strToken,"/")==0){
oper=strToken[0];
getToken();
F_nptr=F();
if(oper=='*')
T11_i=mknode(TIMES,T1_i,F_nptr);
else
T11_i=mknode(SLASH,T1_i,F_nptr);
T1_s=T1(T11_i);
}
//Follow(T1)={+,#,)},假如斟酌-號的話要加上-號
else if(strcmp(strToken,"-")==0 || strcmp(strToken,"+")==0 || strcmp(strToken,"#")==0 || strcmp(strToken,")")==0){
T1_s=T1_i;
}else{
error("語法剖析毛病!");
}
return T1_s;
}
/*
F ::= (E) {F.nptr:=E.nptr}
F ::= num {F.nptr:=mkleaf(num,num.val)}
*/
ASTNode* F()
{
ASTNode* F_nptr;
ASTNode* E_nptr;
if(isNum(strToken)){
F_nptr=mkleaf(NUM,atoi(strToken));
getToken();
}
else{
if(strcmp(strToken,"(")==0){
getToken();
E_nptr=E();
if(strcmp(strToken,")")==0)
getToken();
else
error("語法剖析毛病!");
F_nptr=E_nptr;
}
else {
error("語法剖析毛病!");
}
}
return F_nptr;
}
//創立運算符結點
ASTNode *mknode(Symbol op, ASTNode *left, ASTNode *right)
{
ASTNode* p=(ASTNode*)malloc(sizeof(ASTNode));
p->left=left;
p->right=right;
p->sym=op;
p->val=0;
return p;
}
//創立操作數結點
ASTNode *mkleaf(Symbol sym, ValType val)
{
ASTNode* p=(ASTNode*)malloc(sizeof(ASTNode));
p->sym=sym;
p->val=val;
p->left=NULL;
p->right=NULL;
return p;
}
//輸入結點
void printNode(ASTNode *root)
{
if(root->sym==NUM)
printf("%d ",root->val);
else if(root->sym==PLUS)
printf("+ ");
else if(root->sym==MINUS)
printf("- ");
else if(root->sym==TIMES)
printf("* ");
else if(root->sym==SLASH)
printf("/ ");
}
//中序遍歷二叉樹
void middle_list(ASTNode *root)
{
if(root==NULL)
return ;
middle_list(root->left);
printNode(root);
middle_list(root->right);
}
//後序遍歷二叉樹
void last_list(ASTNode *root)
{
char temp[MAX_LENGTH];
if(root==NULL)
return ;
last_list(root->left);
last_list(root->right);
if(root->sym == NUM){//假如是數字,則直接存入棧中
sprintf(temp,"%d\0",root->val);
strcpy(stack[index++],temp);
}
else if(root->sym == PLUS){//假如是+號,發生一個四元式
//給四元式賦值
quaternion[count].op='+';
strcpy(quaternion[count].arg2,stack[--index]);
strcpy(quaternion[count].arg1,stack[--index]);
sprintf(quaternion[count].result,"t+%d\0",t+=4);
strcpy(stack[index++],quaternion[count].result);
//輸入該四元式
printf("%-4c%-8s%-8s%-8s\n",quaternion[count].op,quaternion[count].arg1,quaternion[count].arg2,quaternion[count].result);
count++;
}else if(root->sym == MINUS){//假如是+號,發生一個四元式
quaternion[count].op='-';
strcpy(quaternion[count].arg2,stack[--index]);
strcpy(quaternion[count].arg1,stack[--index]);
sprintf(quaternion[count].result,"t+%d\0",t+=4);
strcpy(stack[index++],quaternion[count].result);
printf("%-4c%-8s%-8s%-8s\n",quaternion[count].op,quaternion[count].arg1,quaternion[count].arg2,quaternion[count].result);
count++;
}else if(root->sym == TIMES){//假如是*號,發生一個四元式
quaternion[count].op='*';
strcpy(quaternion[count].arg2,stack[--index]);
strcpy(quaternion[count].arg1,stack[--index]);
sprintf(quaternion[count].result,"t+%d\0",t+=4);
strcpy(stack[index++],quaternion[count].result);
printf("%-4c%-8s%-8s%-8s\n",quaternion[count].op,quaternion[count].arg1,quaternion[count].arg2,quaternion[count].result);
count++;
}else if(root->sym == SLASH){
quaternion[count].op='/';
strcpy(quaternion[count].arg2,stack[--index]);
strcpy(quaternion[count].arg1,stack[--index]);
sprintf(quaternion[count].result,"t+%d\0",t+=4);
strcpy(stack[index++],quaternion[count].result);
printf("%-4c%-8s%-8s%-8s\n",quaternion[count].op,quaternion[count].arg1,quaternion[count].arg2,quaternion[count].result);
count++;
}
}
//測試語義剖析
void testYuyiAnalyse()
{
ASTNode *root;
expression_index=0;
getToken();
root=E();
puts("\n語義剖析成果以下:");
printf("中序遍歷:");
middle_list(root);
putchar('\n');
printf("後序遍歷獲得的四元式:\n");
last_list(root);
putchar('\n');
}
//主函數
int main()
{
gets(expression);
testYuyiAnalyse();
return 0;
}
#endif
運轉成果
7、代碼生成
請求:以試驗3的語義剖析法式的四元式輸入作為輸出,輸入匯編說話法式。
test4.c
#ifndef TEST4_C
#define TEST4_C
/**
* 臨盆匯編代碼
**/
#include"test3.c"
//傳人一個四元式,輸入對應的匯編代碼
void print_code(Quaternion qua)
{
putchar('\n');
/*
mov eax, 3
add eax, 4
mov t+0, eax
*/
if(qua.op == '+'){
printf(" mov eax,%s\n",qua.arg1);
printf(" add eax,%s\n",qua.arg2);
printf(" mov %s,eax\n",qua.result);
}else if(qua.op == '-'){
printf(" mov eax,%s\n",qua.arg1);
printf(" sub eax,%s\n",qua.arg2);
printf(" mov %s,eax\n",qua.result);
}
/*
mov eax, 2
mov ebx, t+0
mul ebx
mov t+4, eax
*/
else if(qua.op == '*'){
printf(" mov eax,%s\n",qua.arg1);
printf(" mov ebx,%s\n",qua.arg2);
printf(" mul ebx\n");
printf(" mov %s,eax\n",qua.result);
}else if(qua.op == '/'){//除法的時刻不斟酌余數
printf(" mov eax,%s\n",qua.arg1);
printf(" mov ebx,%s\n",qua.arg2);
printf(" div ebx\n");
printf(" mov %s,eax\n",qua.result);
}
}
//輸入全體匯編代碼
void testCode()
{
int i=0;
puts("生成的匯編代碼以下:\n");
puts(".386");
puts(".MODEL FLAT");
puts("ExitProcess PROTO NEAR32 stdcall, dwExitCode:DWORD");
puts("INCLUDE io.h ; header file for input/output");
puts("cr EQU 0dh ; carriage return character");
puts("Lf EQU 0ah ; line feed");
puts(".STACK 4096 ; reserve 4096-byte stack");
puts(".DATA ; reserve storage for data");
puts("t DWORD 40 DUP (?)");
puts("label1 BYTE cr, Lf, \"The result is \"");
puts("result BYTE 11 DUP (?)");
puts(" BYTE cr, Lf, 0");
puts(".CODE ; start of main program code");
puts("_start:");
//遍歷試驗3中的四元式,輸入對應的匯編代碼
for(;i<count;i++)
print_code(quaternion[i]);
puts(" dtoa result, eax ; convert to ASCII characters");
puts(" output label1 ; output label and sum");
puts(" INVOKE ExitProcess, 0 ; exit with return code 0");
puts("PUBLIC _start ; make entry point public");
puts("END ; end of source code");
}
//主函數
int main()
{
gets(expression);
testLexAnalyse();
testYuyiAnalyse();
testCode();
return 0;
}
#endif
運轉成果
8、點擊下載源代碼