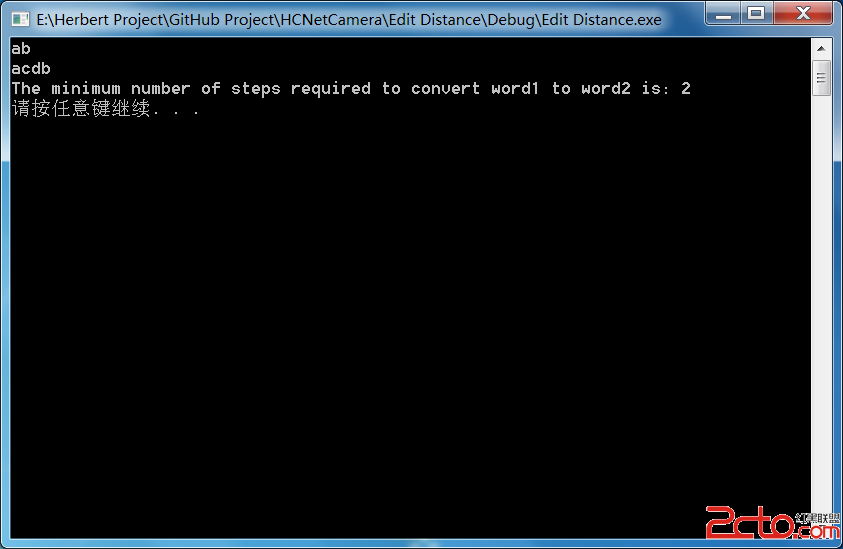
哈夫曼的c說話完成代碼。本站提示廣大學習愛好者:(哈夫曼的c說話完成代碼)文章只能為提供參考,不一定能成為您想要的結果。以下是哈夫曼的c說話完成代碼正文
我們設置一個構造數組 HuffNode 保留哈夫曼樹中各結點的信息。依據二叉樹的性質可知,具有n個葉子結點的哈夫曼樹共有 2n-1 個結點,所以數組 HuffNode 的年夜小設置為 2n-1 。HuffNode 構造中有 weight, lchild, rchild 和 parent 域。個中,weight 域保留結點的權值, lchild 和 rchild 分離保留該結點的左、右孩子的結點在數組 HuffNode 中的序號,從而樹立起結點之間的關系。為了剖斷一個結點能否已參加到要樹立的哈夫曼樹中,可經由過程 parent 域的值來肯定。初始時 parent 的值為 -1。當結點參加到樹中去時,該結點 parent 的值為其父結點在數組 HuffNode 中的序號,而不會是 -1 了。
求葉結點的編碼:
該進程本質上就是在已樹立的哈夫曼樹中,從葉結點開端,沿結點的雙親鏈域回退到根結點,每回退一步,就走過了哈夫曼樹的一個分支,從而獲得一名哈夫曼碼值。因為一個字符的哈夫曼編碼是從根結點到響應葉結點所經由的途徑上各分支所構成的 0、1 序列,是以先獲得的分支代碼為所求編碼的低位,後獲得的分支代碼為所求編碼的高位碼。我們可以設置一個構造數組 HuffCode 用來寄存各字符的哈夫曼編碼信息,數組元素的構造中有兩個域:bit 和 start。個中,域 bit 為一維數組,用來保留字符的哈夫曼編碼, start 表現該編碼在數組 bit 中的開端地位。所以,關於第 i 個字符,它的哈夫曼編碼寄存在 HuffCode[i].bit 中的從 HuffCode[i].start 到 n 的 bit 位中。
/*-------------------------------------------------------------------------
* Name: 哈夫曼編碼源代碼。
* 在 Win-TC 下測試經由過程
* 完成進程:著先經由過程 HuffmanTree() 函數結構哈夫曼樹,然後在主函數 main()中
* 自底向上開端(也就是從數組序號為零的結點開端)向下層層斷定,若在
* 父結點左邊,則置碼為 0,若在右邊,則置碼為 1。最初輸入生成的編碼。
*------------------------------------------------------------------------*/
#include <stdio.h>
#define MAXBIT 100
#define MAXVALUE 10000
#define MAXLEAF 30
#define MAXNODE MAXLEAF*2 -1
typedef struct
{
int bit[MAXBIT];
int start;
} HCodeType; /* 編碼構造體 */
typedef struct
{
int weight;
int parent;
int lchild;
int rchild;
} HNodeType; /* 結點構造體 */
/* 結構一顆哈夫曼樹 */
void HuffmanTree (HNodeType HuffNode[MAXNODE], int n)
{
/* i、j: 輪回變量,m1、m2:結構哈夫曼樹分歧進程中兩個最小權值結點的權值,
x1、x2:結構哈夫曼樹分歧進程中兩個最小權值結點在數組中的序號。*/
int i, j, m1, m2, x1, x2;
/* 初始化寄存哈夫曼樹數組 HuffNode[] 中的結點 */
for (i=0; i<2*n-1; i++)
{
HuffNode[i].weight = 0;
HuffNode[i].parent =-1;
HuffNode[i].lchild =-1;
HuffNode[i].lchild =-1;
} /* end for */
/* 輸出 n 個葉子結點的權值 */
for (i=0; i<n; i++)
{
printf ("Please input weight of leaf node %d: \n", i);
scanf ("%d", &HuffNode[i].weight);
} /* end for */
/* 輪回結構 Huffman 樹 */
for (i=0; i<n-1; i++)
{
m1=m2=MAXVALUE; /* m1、m2中寄存兩個無父結點且結點權值最小的兩個結點 */
x1=x2=0;
/* 找出一切結點中權值最小、無父結點的兩個結點,並歸並之為一顆二叉樹 */
for (j=0; j<n+i; j++)
{
if (HuffNode[j].weight < m1 && HuffNode[j].parent==-1)
{
m2=m1;
x2=x1;
m1=HuffNode[j].weight;
x1=j;
}
else if (HuffNode[j].weight < m2 && HuffNode[j].parent==-1)
{
m2=HuffNode[j].weight;
x2=j;
}
} /* end for */
/* 設置找到的兩個子結點 x1、x2 的父結點信息 */
HuffNode[x1].parent = n+i;
HuffNode[x2].parent = n+i;
HuffNode[n+i].weight = HuffNode[x1].weight + HuffNode[x2].weight;
HuffNode[n+i].lchild = x1;
HuffNode[n+i].rchild = x2;
printf ("x1.weight and x2.weight in round %d: %d, %d\n", i+1, HuffNode[x1].weight, HuffNode[x2].weight); /* 用於測試 */
printf ("\n");
} /* end for */
} /* end HuffmanTree */
int main(void)
{
HNodeType HuffNode[MAXNODE]; /* 界說一個結點構造體數組 */
HCodeType HuffCode[MAXLEAF], cd; /* 界說一個編碼構造體數組, 同時界說一個暫時變量來寄存求解編碼時的信息 */
int i, j, c, p, n;
printf ("Please input n:\n");
scanf ("%d", &n);
HuffmanTree (HuffNode, n);
for (i=0; i < n; i++)
{
cd.start = n-1;
c = i;
p = HuffNode[c].parent;
while (p != -1) /* 父結點存在 */
{
if (HuffNode[p].lchild == c)
cd.bit[cd.start] = 0;
else
cd.bit[cd.start] = 1;
cd.start--; /* 求編碼的低一名 */
c=p;
p=HuffNode[c].parent; /* 設置下一輪回前提 */
} /* end while */
/* 保留求出的每一個葉結點的哈夫曼編碼和編碼的肇端位 */
for (j=cd.start+1; j<n; j++)
{ HuffCode[i].bit[j] = cd.bit[j];}
HuffCode[i].start = cd.start;
} /* end for */
/* 輸入已保留好的一切存在編碼的哈夫曼編碼 */
for (i=0; i<n; i++)
{
printf ("%d 's Huffman code is: ", i);
for (j=HuffCode[i].start+1; j < n; j++)
{
printf ("%d", HuffCode[i].bit[j]);
}
printf ("\n");
}
getch();
return 0;
}