哈夫曼算法結構代碼。本站提示廣大學習愛好者:(哈夫曼算法結構代碼)文章只能為提供參考,不一定能成為您想要的結果。以下是哈夫曼算法結構代碼正文
1.界說
哈夫曼編碼重要用於數據緊縮。
哈夫曼編碼是一種可變長編碼。該編碼將湧現頻率高的字符,應用短編碼;將湧現頻率低的字符,應用長編碼。
變長編碼的重要成績是,必需完成非前綴編碼,即在一個字符集中,任何一個字符的編碼都不是另外一個字符編碼的前綴。如:0、10就長短前綴編碼,而0、01不長短前綴編碼。
2.哈夫曼樹的結構
依照字符湧現的頻率,老是選擇以後具有較小頻率的兩個節點,組合為一個新的節點,輪回此進程曉得只剩下一個節點為止。
關於5個字符A、B、C、D、E,頻率分離用1、5、7、9、6表現,則結構樹的進程以下:
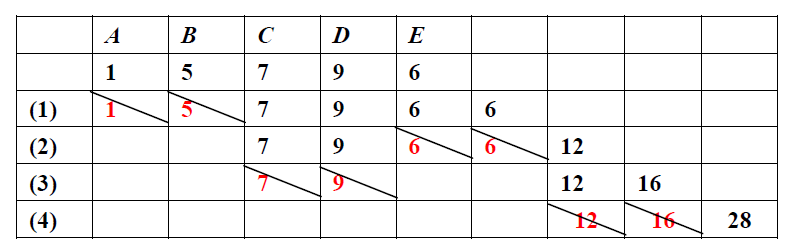
下面進程對應的哈夫曼樹為:
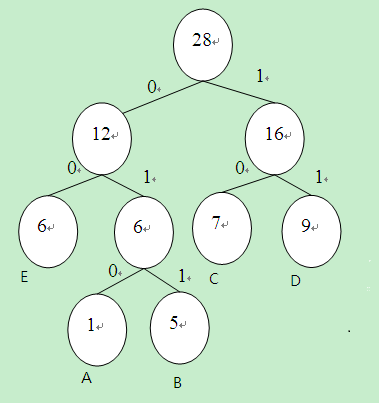
假定劃定右邊為0,左邊為1,則變長編碼為:
A 1:010
B 5:011
C 7:10
D 9:11
E 6: 00
3.哈夫曼結構代碼
#include <iostream>
#include <string.h>
using namespace std;
struct Node{
char c;
int value;
int par;
char tag; //tag='0',表現右邊;tag='1',表現左邊
bool isUsed; //斷定這個點能否曾經用過
Node(){
par=-1;
isUsed=false;
}
};
int input(Node*,int); //輸出節點信息
int buildedTree(Node*,int); //建哈夫曼樹
int getMin(Node*,int); //尋覓未應用的,具有最小頻率值的節點
int outCoding(Node*,int); //輸入哈夫曼編碼
int main ()
{
int n;
cin>>n;
Node *nodes=new Node[2*n-1];
input(nodes,n);
buildedTree(nodes,n);
outCoding(nodes,n);
delete(nodes);
return 0;
}
int input(Node* nodes,int n){
for(int i=0;i<n;i++){
cin>>(nodes+i)->c;
cin>>(nodes+i)->value;
}
return 0;
}
int buildedTree(Node* nodes,int n){
int last=2*n-1;
int t1,t2;
for(int i=n;i<last;i++){
t1=getMin(nodes,i);
t2=getMin(nodes,i);
(nodes+t1)->par=i; (nodes+t1)->tag='0';
(nodes+t2)->par=i; (nodes+t2)->tag='1';
(nodes+i)->value=(nodes+t1)->value+(nodes+t2)->value;
}
return 0;
}
int getMin(Node* nodes,int n){
int minValue=10000000;
int pos=0;
for(int i=0;i<n;i++)
{
if((nodes+i)->isUsed == false && (nodes+i)->value<minValue){
minValue=(nodes+i)->value;
pos=i;
}
}
(nodes+pos)->isUsed=true;
return pos;
}
int outCoding(Node* nodes,int n){
char a[100];
int pos,k,j;
char tmp;
for(int i=0;i<n;i++){
k=0;
pos=i;
memset(a,'\0',sizeof(a));
while((nodes+pos)->par!=-1){
a[k++]=(nodes+pos)->tag;
pos=(nodes+pos)->par;
}
strrev(a); //翻轉字符串
cout<<(nodes+i)->c<<" "<<(nodes+i)->value<<":"<<a<<endl;
}
return 0;
}
履行示例: