C說話完成排序算法之合並排序詳解。本站提示廣大學習愛好者:(C說話完成排序算法之合並排序詳解)文章只能為提供參考,不一定能成為您想要的結果。以下是C說話完成排序算法之合並排序詳解正文
排序算法中的合並排序(Merge Sort)是應用"合並"技巧來停止排序。合並是指將若干個已排序的子文件歸並成一個有序的文件。
1、完成道理:
1、算法根本思緒
設兩個有序的子文件(相當於輸出堆)放在統一向量中相鄰的地位上:R[low..m],R[m+1..high],先將它們歸並到一個部分的暫存向量R1(相當於輸入堆)中,待歸並完成後將R1復制回R[low..high]中。
(1)歸並進程
歸並進程中,設置i,j和p三個指針,其初值分離指向這三個記載區的肇端地位。歸並時順次比擬R[i]和R[j]的症結字,取症結字較小的記載復制到R1[p]中,然後將被復制記載的指針i或j加1,和指向復制地位的指針p加1。
反復這一進程直至兩個輸出的子文件有一個已全體復制終了(無妨稱其為空),此時將另外一非空的子文件中殘剩記載順次復制到R1中便可。
最初,將成果賦值的R[]中。
(2)靜態請求R1
完成時,R1是靜態請求的,由於請求的空間能夠很年夜,故須參加請求空間能否勝利的處置。
2、3種辦法完成:
算法1:合並函數都靜態分派一個數組,兩個有序數組歸並成一個有序數組
//歸並將兩個有序序列([low,mid],[mid+1,high])歸並
void Merge(int arr[],int low,int mid,int high)
{
int i=low,j=mid+1,p=0;
int *newarr = (int *)malloc((high-low+1)*sizeof(int));//用來暫存排序好的數據
if(!newarr){
printf("malloc error!\n");
exit(1);
}
while(i<=mid && j<=high){ //以下進程很相似兩個有序字符串歸並成一個有序字符串
if(arr[i] < arr[j])
newarr[p++] = arr[i++];
else
newarr[p++] = arr[j++];
}
while(i<=mid)
newarr[p++] = arr[i++];
while(j<=high)
newarr[p++] = arr[j++];
for(i=low,p=0;p<(high-low+1);i++,p++) //將成果復制到原數組傍邊
arr[i] = newarr[p];
free(newarr);
}
算法2:
法式開端處就靜態分派一個年夜數組,防止每次都要創立許多小數組,釋放內存的時刻,不會立刻釋放。
有關assert()拜見:http://www.jb51.net/article/39685.htm
/*
* File: mergesort.c
* Time: 2014-07-19 HJJ
*/
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
static void merge1(int array[], int tmp[], int lpos, int rpos, int rend);
static void msort1(int array[], int tmp[], int left, int right);
void merge_sort1(int array[], int n)
{
assert(array!=NULL && n>1); //前提不知足,加入法式並打印毛病語句。
int *tmp = (int *)malloc(sizeof(int) * n);
assert(tmp != NULL);
int i;
for (i = 0; i < n; i ++) {
tmp[i] = array[i];
}
msort1(array, tmp, 0, n-1);
free(tmp);
}
//遞歸的挪用此函數,完成折半劃分,只完成劃分,不完成排序,終究前往array[]數組有序
static void msort1(int array[], int tmp[], int left, int right)
{
assert(array!=NULL && tmp!=NULL);
if (left == right)
return;
int center = (left + right) / 2;
msort1(tmp, array, left, center);
msort1(tmp, array, center+1, right);
merge1(tmp, array, left, center+1, right);
}
//該函數完成,將array[]的閣下兩半排好序的數組,合並為tmp[],並排序
static void merge1(int array[], int tmp[], int lpos, int rpos, int rend)
{
assert(array!=NULL && tmp!=NULL);
int lend = rpos - 1;
int tmp_pos = lpos;
while (lpos<=lend && rpos<=rend) {
if (array[lpos] <= array[rpos])
tmp[tmp_pos++] = array[lpos++];
else
tmp[tmp_pos++] = array[rpos++];
}
while (lpos <= lend)
tmp[tmp_pos++] = array[lpos++];
while (rpos <= rend)
tmp[tmp_pos++] = array[rpos++];
}
int main(int argc, char *argv[])
{
int a[7] = {6, 5, 4, 3, 2, 1, 7};
merge_sort1(a, 7);
int i;
for (i = 0; i < 7; i ++) {
printf("%3d", a[i]);
}
printf("\n");
return 0;
}
算法3:
法式開端處罰配一個年夜的數組,只是每次用array[]將數據給tmp[]排好序後,最初再將tmp[]給array[]賦值,如許就可以完成每次挪用的時刻,進口都一樣。
void merge_sort1(int array[], int n)
{
assert(array!=NULL && n>1); //前提不知足,加入法式並打印毛病語句。
int *tmp = (int *)malloc(sizeof(int) * n);
assert(tmp != NULL);
int i;
for (i = 0; i < n; i ++) {
tmp[i] = array[i];
}
msort1(array, tmp, 0, n-1);
free(tmp);
}
//遞歸的挪用此函數,完成折半劃分,只完成劃分,不完成排序,終究前往array[]數組有序
static void msort1(int array[], int tmp[], int left, int right)
{
assert(array!=NULL && tmp!=NULL);
if (left == right)
return;
int center = (left + right) / 2;
msort1(tmp, array, left, center);
msort1(tmp, array, center+1, right);
merge(tmp, array, left, center+1, right);
}
完成辦法二:
void merge(int array[],int tmp[],int lpos,int rpos,int rend)
{
int i,leftend,num,tmppos;
leftend = rpos - 1;
num = rend - lpos + 1;
tmppos = lpos;
while(lpos <= leftend && rpos <= rend){
if(array[lpos] <= array[rpos])
tmp[tmppos++] = array[lpos++];
else
tmp[tmppos++] = array[rpos++];
}
while(lpos <= leftend)
tmp[tmppos++] = array[lpos++];
while(rpos <= rend)
tmp[tmppos++] = array[rpos++];
for(i = 0;i < num;i++,rend--)
array[rend] = tmp[rend];
}
合並排序:將一個無序數組歸並成一個有序數組
有兩種完成辦法:自底向上和自頂向下
1、 自底向上的辦法(自底向上的合並排序算法固然效力較高,但可讀性較差。)
(1) 自底向上的根本思惟:
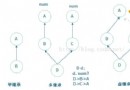
自底向上的根本思惟是:第1趟合並排序時,將待排序的文件R[1..n]看做是n個長度為1的有序子文件,將這些子文件兩兩合並,若n為偶數,則獲得n/2個長度為2的有序子文件;若n為奇數,則最初一個子文件輪空(不介入合並)。故本趟合並完成後,前logn個有序子文件長度為2,但最初一個子文件長度仍為1;第2趟合並則是將第1趟合並所獲得的logn個有序的子文件兩兩合並,如斯重復,直到最初獲得一個長度為n的有敘文件為止。
上述的每次合並操作,均是將兩個有序的子文件歸並成一個有序的子文件,故稱其為"二路合並排序"。相似地有k(k>2)路合並排序。
(2) 一趟合並算法
剖析:
在某趟合並中,設各子文件長度為length(最初一個子文件的長度能夠小於length),則合並前R[1..n]中共有 個有序的子文件:R[1..length],R[length+1..2length],…
留意:
挪用合並操作將相鄰的一對子文件停止合並時,必需對子文件的個數能夠是奇數、和最初一個子文件的長度小於length這兩種特別情形停止特別處置:
① 若子文件個數為奇數,則最初一個子文件不必和其它子文件合並(即本趟輪空);
② 若子文件個數為偶數,則要留意最初一對子文件中後一子文件的區間上界是n。
詳細算法以下:
/*自底向上,這裡就不寫真實的代碼了,從網上copy了*/
void MergePass(SeqList R,int length)
{ //對R[1..n]做一趟合並排序
int i;
for(i=1;i+2*length-1<=n;i=i+2*length)
Merge(R,i,i+length-1,i+2*length-1);
//合並長度為length的兩個相鄰子文件
if(i+length-1<n) //另有兩個子文件,個中後一個長度小於length
Merge(R,i,i+length-1,n); //合並最初兩個子文件
//留意:若i≤n且i+length-1≥n時,則殘剩一個子文件輪空,不必合並
} //MergePass
void MergeSort(SeqList R)
{//采取自底向上的辦法,對R[1..n]停止二路合並排序
int length;
for(1ength=1;length<n;length*=2) //做 趟合並
MergePass(R,length); //有序段長度≥n時終止
}
2、自頂向下的辦法
采取分治法停止自頂向下的算法設計,情勢更加簡練。
(1)分治法的三個步調
設合並排序確當前區間是R[low..high],分治法的三個步調是:
①分化:將以後區間一分為二,即求決裂點:mid = (low+high)/2;
②求解:遞歸地對兩個子區間R[low..mid]和R[mid+1..high]停止合並排序;
③組合:將已排序的兩個子區間R[low..mid]和R[mid+1..high]合並為一個有序的區間R[low..high]。
遞歸的終結前提:子區間長度為1(一個記載天然有序)。
詳細算法:
void MSort(int arr[],int low,int high)
{
if(low < high){
int mid = (low+high)/2;
MSort(arr,low,mid); //左半區排序
MSort(arr,mid+1,high); //右半區排序
Merge(arr,low,mid,high);//閣下半區歸並
}
}
三:剖析
1、穩固性
合並排序是一種穩固的排序。
2、存儲構造請求
可用次序存儲構造。也易於在鏈表上完成。
3、時光龐雜度
對長度為n的文件,需停止lgn趟二路合並,每趟合並的時光為O(n),故當時間龐雜度不管是在最好情形下照樣在最壞情形下均是O(nlgn)。
4、空間龐雜度
須要一個幫助向量來暫存兩有序子文件合並的成果,故其幫助空間龐雜度為O(n),明顯它不是當場排序。
留意:
若用單鏈表做存儲構造,很輕易給出當場的合並排序。