VC中完成GB2312、BIG5、Unicode編碼轉換的辦法。本站提示廣大學習愛好者:(VC中完成GB2312、BIG5、Unicode編碼轉換的辦法)文章只能為提供參考,不一定能成為您想要的結果。以下是VC中完成GB2312、BIG5、Unicode編碼轉換的辦法正文
本文重要以實例情勢評論辯論了VC編譯情況下,完成字符串和文件編碼方法轉換的辦法,在linux下請應用Strconv來完成。詳細辦法以下:
1、文件編碼格局轉換
//GB2312 編碼文件轉換成 Unicode:
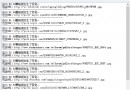
if((file_handle = fopen(filenam,"rb")) != NULL)
{
//從GB2312源文件以二進制的方法讀取buffer
numread = fread(str_buf_pool,sizeof(char),POOL_BUFF_SIZE,file_handle);
fclose(file_handle);
//GB2312文件buffer轉換成UNICODE
nLen =MultiByteToWideChar(CP_ACP,0,str_buf_pool,-1,NULL,0);
MultiByteToWideChar(CP_ACP,0,str_buf_pool,-1,(LPWSTR)str_unicode_buf_pool,nLen);
//組裝UNICODE Little Endian編碼文件文件頭標示符"0xFF 0xFE"
//備注:UNICODE Big Endian編碼文件文件頭標示符"0xFF 0xFE"
//Little Endian與Big Endian編碼差別此處不胪陳
unicode_little_file_header[0]=0xFF;
unicode_little_file_header[1]=0xFE;
//存儲目的文件
if((file_handle=fopen(filenewname,"wb+")) != NULL)
{
fwrite(unicode_little_file_header,sizeof(char),2,file_handle);
numwrite = fwrite(str_unicode_buf_pool,sizeof(LPWSTR),nLen,file_handle);
fclose(file_handle);
}
}
2、字符串編碼格局轉換
//GB2312 轉換成 Unicode:
wchar_t* GB2312ToUnicode(const char* szGBString)
{
UINT nCodePage = 936; //GB2312
int nLength=MultiByteToWideChar(nCodePage,0,szGBString,-1,NULL,0);
wchar_t* pBuffer = new wchar_t[nLength+1];
MultiByteToWideChar(nCodePage,0,szGBString,-1,pBuffer,nLength);
pBuffer[nLength]=0;
return pBuffer;
}
//BIG5 轉換成 Unicode:
wchar_t* BIG5ToUnicode(const char* szBIG5String)
{
UINT nCodePage = 950; //BIG5
int nLength=MultiByteToWideChar(nCodePage,0,szBIG5String,-1,NULL,0);
wchar_t* pBuffer = new wchar_t[nLength+1];
MultiByteToWideChar(nCodePage,0,szBIG5String,-1,pBuffer,nLength);
pBuffer[nLength]=0;
return pBuffer;
}
//Unicode 轉換成 GB2312:
char* UnicodeToGB2312(const wchar_t* szUnicodeString)
{
UINT nCodePage = 936; //GB2312
int nLength=WideCharToMultiByte(nCodePage,0,szUnicodeString,-1,NULL,0,NULL,NULL);
char* pBuffer=new char[nLength+1];
WideCharToMultiByte(nCodePage,0,szUnicodeString,-1,pBuffer,nLength,NULL,NULL);
pBuffer[nLength]=0;
return pBuffer;
}
//Unicode 轉換成 BIG5:
char* UnicodeToBIG5(const wchar_t* szUnicodeString)
{
UINT nCodePage = 950; //BIG5
int nLength=WideCharToMultiByte(nCodePage,0,szUnicodeString,-1,NULL,0,NULL,NULL);
char* pBuffer=new char[nLength+1];
WideCharToMultiByte(nCodePage,0,szUnicodeString,-1,pBuffer,nLength,NULL,NULL);
pBuffer[nLength]=0;
return pBuffer;
}
//繁體中文BIG5 轉換成 簡體中文 GB2312
char* BIG5ToGB2312(const char* szBIG5String)
{
LCID lcid = MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_PRC);
wchar_t* szUnicodeBuff = BIG5ToUnicode(szBIG5String);
char* szGB2312Buff = UnicodeToGB2312(szUnicodeBuff);
int nLength = LCMapString(lcid,LCMAP_SIMPLIFIED_CHINESE, szGB2312Buff,-1,NULL,0);
char* pBuffer = new char[nLength + 1];
LCMapString(0x0804,LCMAP_SIMPLIFIED_CHINESE,szGB2312Buff,-1,pBuffer,nLength);
pBuffer[nLength] = 0;
delete[] szUnicodeBuff;
delete[] szGB2312Buff;
return pBuffer;
}
//簡體中文 GB2312 轉換成 繁體中文BIG5
char* GB2312ToBIG5(const char* szGBString)
{
LCID lcid = MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_PRC);
int nLength = LCMapString(lcid,LCMAP_TRADITIONAL_CHINESE,szGBString,-1,NULL,0);
char* pBuffer=new char[nLength+1];
LCMapString(lcid,LCMAP_TRADITIONAL_CHINESE,szGBString,-1,pBuffer,nLength);
pBuffer[nLength]=0;
wchar_t* pUnicodeBuff = GB2312ToUnicode(pBuffer);
char* pBIG5Buff = UnicodeToBIG5(pUnicodeBuff);
delete[] pBuffer;
delete[] pUnicodeBuff;
return pBIG5Buff;
}
3、API 函數:MultiByteToWideChar參數解釋
第一個參數為代碼頁, 用 GetLocaleInfo 函數獲得以後體系的代碼頁,936: 簡體中文, 950: 繁體中文
第二個參數為選項,普通用 0 便可以了
第三個參數為 ANSI 字符串的地址, 這個字符串是第一個參數指定的說話的 ANSI 字符串 (AnsiString)
第四個參數為 ANSI 字符串的長度,假如用 -1, 就表現是用 0 作為停止符的字符串
第五個參數為轉化生成的 unicode 字符串 (WideString) 的地址, 假如為 NULL, 就是代表盤算生成的字符串的長度
第六個參數為轉化生成的 unicode 字符串緩存的容量,也就是有若干個UNICODE字符。