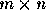C++變位詞成績剖析。本站提示廣大學習愛好者:(C++變位詞成績剖析)文章只能為提供參考,不一定能成為您想要的結果。以下是C++變位詞成績剖析正文
在《編程珠玑》一書的第二章提到了一個變位詞成績,變位詞指的是一個單詞可以經由過程轉變其他單詞中字母的次序來獲得,也叫做兄弟單詞,如army->mary。由變位詞可以引伸出幾個算法成績,包含字符串包括成績,比擬兩個字符串能否是變位詞,和找出字典中變位詞聚集的成績。
1、字符串包括成績
(1) 成績描寫:存在字符串1和字符串2,假定字符串2絕對較短,若何疾速地剖斷字符串2中的字符都存在於字符串1裡(假定字符串只包括字母)?
(2) 舉例:字符串1為ABCDEFGHIJK,字符串2為ABCDE,則字符串1包括字符串2,由於字符串2中包括的字母在字符串1中也都有。
(3) 處理計劃:
思緒一
最直接的思緒就是針對字符串2中的每一個字符,輪詢字符串1停止比擬,看能否在字符串1外面。很顯著這類的時光效力為O(n*m)。
/*************************************************************************
> File Name: test.cpp
> Author: SongLee
************************************************************************/
#include<iostream>
#include<string>
using namespace std;
void Compare(string long_str, string short_str)
{
int i,j;
for(i=0; i<short_str.size(); ++i)
{
for(j=0; j<long_str.size(); ++j)
{
if(long_str[j] == short_str[i])
{
break;
}
}
if(j == long_str.size())
{
cout << "false" << endl;
return;
}
}
cout << "true" << endl;
return;
}
int main()
{
string l = "ABCDEFGHIJK";
string s = "ABCDEF";
Compare(l, s);
return 0;
}
思緒二
這裡因為假定了字符串只包括字母,所以我們可以用一個額定的數組flag[26]作為26個字符標識位,先遍歷長字符串將對應的標識地位1,再遍歷短字符串,假如對應的標示位都是1,則包括;不然不包括。這類辦法的時光龐雜度為O(n+m),為了進步空間效力,這裡不應用數組而應用26個bit位來作為標示位(bitset容器)。
/*************************************************************************
> File Name: test1.cpp
> Author: SongLee
************************************************************************/
#include<iostream>
#include<bitset>
#include<string>
using namespace std;
bool Compare(string long_str, string short_str)
{
bitset<26> flag;
for(int i=0; i<long_str.size(); ++i)
{
// flag.set(n)置第n位為1
flag.set(long_str[i]-'A');
}
for(int i=0; i<short_str.size(); ++i)
{
// flag.test(n)斷定第n位能否為1
if(!flag.test(short_str[i]-'A'))
return false;
}
return true;
}
int main()
{
string l = "ABCDEFGHIJK";
string s = "ABCDEZ";
if(Compare(l, s))
cout << "true" << endl;
else
cout << "false" << endl;
return 0;
}
這類辦法還可以停止優化,例如假如長字串的前綴就為短字串,那末我們可以不須要n+m次,而只須要2m次。詳細完成請本身思慮。
思緒三
給每一個字母分派一個素數,從2開端到3,5,7...遍歷長字串,求得每一個字符對應素數的乘積。然後遍歷短字串,斷定該乘積可否被短字符串中的字符對應的素數整除,假如除的成果存在余數,則解釋有不婚配的字母;假如全部進程都沒不足數,則解釋短字串中的字母在長字串裡都有。這類辦法的時光龐雜度也是O(n+m),須要26個額定空間存素數,然則這類辦法有一個缺陷就是須要跟年夜整數打交道,由於乘積能夠異常年夜。(這裡我們應用<cstdint>頭文件中界說的int64_t和uint64_t)
/*************************************************************************
> File Name: test2.cpp
> Author: SongLee
************************************************************************/
#include<iostream>
#include<string>
#include<stdint.h>
//#include<cstdint> // C++11
using namespace std;
bool Compare(string long_str, string short_str)
{
unsigned int primeNum[26] = {2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,
53,59,61,67,71,73,79,83,89,97,101};
/* int64_t和uint64_t分離表現64位的有符號和無符號整形數 */
/* 在分歧位數機械的平台下通用,都是64位 */
uint64_t ch = 1;
for(int i=0; i<long_str.size(); ++i)
{
ch = ch*primeNum[long_str[i]-'A'];
}
for(int i=0; i<short_str.size(); ++i)
{
if(ch%primeNum[short_str[i]-'A'] != 0)
return false;
}
return true;
}
int main()
{
string l = "ABCDEFGHIJK";
string s = "ABCDEK";
if(Compare(l, s))
cout << "true" << endl;
else
cout << "false" << endl;
return 0;
}
2、比擬兩個字符串能否為變位詞
(1) 成績描寫:假如兩個字符串的字符一樣,然則次序紛歧樣,被以為是兄弟字符串,問若何在敏捷婚配兄弟字符串(如,bad和adb就是兄弟字符串)。
(2) 留意:第一點中評論辯論了字符串包括成績,然則不要認為兩個字符串相互包括就是(變位詞)兄弟字符串了,例如aabcde和edcba相互包括,但它們不是變位詞。
(3) 處理計劃:
思緒一
給每一個字母分派一個素數,可以經由過程斷定兩個字符串的素數乘積能否相等。跟上述素數法一樣,時光龐雜度也是O(n+m),須要跟年夜整數打交道。
/*************************************************************************
> File Name: test3.cpp
> Author: SongLee
************************************************************************/
#include<iostream>
#include<string>
#include<stdint.h>
//#include<cstdint> // C++11
using namespace std;
bool Compare(string s1, string s2)
{
unsigned int primeNum[26] = {2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,
53,59,61,67,71,73,79,83,89,97,101};
uint64_t ch = 1;
for(int i=0; i<s1.size(); ++i)
{
ch = ch*primeNum[s1[i]-'a'];
}
for(int i=0; i<s2.size(); ++i)
{
ch = ch/primeNum[s2[i]-'a'];
}
if(ch == 1)
return true;
else
return false;
}
int main()
{
string s1 = "abandon";
string s2 = "banadon";
if(Compare(s1, s2))
cout << "They are brother words!" << endl;
else
cout << "They aren't brother words!" << endl;
return 0;
}
思緒二
將兩個字符串依照字母表次序排序,看排序後的字符串能否相等,假如相等則是兄弟字符串(變位詞)。這類辦法的時光效力依據你應用的排序算法分歧而分歧。固然,你可以本身寫排序算法,這裡我們應用C++的STL中的sort()函數對字符串停止排序。
/*************************************************************************
> File Name: test4.cpp
> Author: SongLee
************************************************************************/
#include<iostream>
#include<algorithm>
#include<string>
using namespace std;
// 自界說序函數(二元謂詞)
bool myfunction(char i, char j)
{
return i > j;
}
bool Compare(string s1, string s2)
{
// 采取泛型算法對s1,s2排序,sort()采取的是疾速排序算法
sort(s1.begin(), s1.end(), myfunction);
sort(s2.begin(), s2.end(), myfunction);
if(!s1.compare(s2)) // 相等前往0
return true;
else
return false;
}
int main()
{
string s1 = "abandon";
string s2 = "banadon";
if(Compare(s1, s2))
cout << "They are brother words!" << endl;
else
cout << "They aren't brother words!" << endl;
return 0;
}
3、字典找出一切變位詞聚集(重點)
(1) 成績描寫:給定一個英語字典,找出個中的一切變位詞聚集。
(2) 處理計劃:
思緒一
關於這個成績,最快想到的最直接的辦法就是針對每個單詞跟字典中的其他單詞停止比擬。但是,假定一次比擬至多消費1微秒的時光,則具有二十萬單詞的字典將消費:200000單詞 x 200000比擬/單詞 x 1微秒/比擬 = 40000x10^6秒 = 40000秒 ≈ 11.1小時。比擬的次數太多了,招致效力低下,我們須要找出效力更高的辦法。
思緒二
標識字典中的每個單詞,使得在雷同變位詞類中的單詞具有雷同的的標識,然後集中具有雷同標識的單詞。將每一個單詞依照字母表排序,排序後獲得的字符串作為該單詞的標識。那末關於該成績的解題進程可以分為三步:第一步,讀入字典文件,對單詞停止排序獲得標識;第二步,將一切的單詞依照其標識的次序排序;第三步,將統一個變位詞類中的各個單詞放到統一行中。
這裡湧現了標識-單詞(key-value)對,我們很輕易想到C++中的聯系關系容器map,應用map的利益就是:
靜態治理內存,容器年夜小靜態轉變;
單詞與它的標識逐個對應,關於雷同標識(key)的單詞直接加在值(value)前面;
無需依據標識排序,由於map會主動按症結字有序(默許升序)。
所以,在將每一個單詞及其標識存入map今後,便可以直接遍歷輸入了,每個map元素就是一個變位詞聚集。
C++完成代碼以下:
/*************************************************************************
> File Name: test5.cpp
> Author: SongLee
************************************************************************/
#include<iostream>
#include<fstream> // file I/O
#include<map> // map
#include<string> // string
#include<algorithm> // sort
using namespace std;
/*
*map是C++中的聯系關系容器
* 按症結字有序
* 症結字弗成反復
*/
map<string, string> word;
/* 自界說比擬函數(用於排序) */
bool myfunction(char i, char j)
{
return i < j;
}
/*
*對每一個單詞排序
*排序後字符串作為症結字,原單詞作為值
*存入map中
*/
void sign_sort(const char* dic)
{
// 文件流
ifstream in(dic);
if(!in)
{
cout << "Couldn't open file: " + string(dic) << endl;
return;
}
string aword;
string asign;
while(in >> aword)
{
asign = aword;
sort(asign.begin(), asign.end(), myfunction);
// 若標識不存在,創立一個新map元素,若存在,加在值前面
word[asign] += aword + " ";
}
in.close();
}
/*
*寫入輸入文件
*/
void write_file(const char* file)
{
ofstream out(file);
if(!out)
{
cout << "Couldn't create file: " + string(file) << endl;
return;
}
map<string, string>::iterator begin = word.begin();
map<string, string>::iterator end = word.end();
while(begin != end)
{
out << begin->second << "\n";
++begin;
}
out.close();
}
int main()
{
string dic;
string outfile;
cout << "Please input dictionary name: ";
cin >> dic;
cout << "Please input output filename: ";
cin >> outfile;
sign_sort(dic.c_str());
write_file(outfile.c_str());
return 0;
}
附:(2012.5.6百度練習口試題)一個單詞交流字母地位,可得另外一個單詞,如army->mary,成為兄弟單詞。供給一個單詞,在字典中找到它的兄弟。描寫數據構造和查詢進程。
解題思緒:假如不許可停止預處置,那末我們只能次序遍歷全部字典,盤算每一個單詞的標識與給訂單詞的標識比擬。假如許可停止預處置,我們可以如上述思緒二將一切單詞參加一個map,然後輸入症結字(給訂單詞的標識)對應的值,值中就包括了該單詞的一切兄弟單詞。
信任本文所述實例有助於讀者更好的控制C++下數據構造與算法的完成技能。