C++完成廣度優先搜刮實例。本站提示廣大學習愛好者:(C++完成廣度優先搜刮實例)文章只能為提供參考,不一定能成為您想要的結果。以下是C++完成廣度優先搜刮實例正文
本文重要論述了圖的遍歷算法中的廣度優先搜刮(Breadth-First-Search)算法,長短常經典的算法,可供C++法式員參考自創之用。詳細以下:
起首,圖的遍歷是指從圖中的某一個極點動身,依照某種搜刮辦法沿著圖中的邊對圖中的一切極點拜訪一次且僅拜訪一次。留意到樹是一種特別的圖,所以樹的遍歷現實上也能夠看做是一種特別的圖的遍歷。圖的遍歷重要有兩種算法:廣度優先搜刮(Breadth-First-Search)和深度優先搜刮(Depth-First-Search)。
1、廣度優先搜刮(BFS)的算法思惟
廣度優先搜刮相似於二叉樹的層序遍歷,它的根本思惟就是:起首拜訪肇端極點v,接著由v動身,順次拜訪v的各個未拜訪過的鄰接極點w1,w2,…,wi,然後再順次拜訪w1,w2,…,wi的一切未被拜訪過的鄰接極點;再從這些拜訪過的極點動身,再拜訪它們一切未被拜訪過的鄰接極點……順次類推,直到圖中一切極點都被拜訪過為止。
廣度優先搜刮是一種分層的查找進程,每向前走一步能夠拜訪一批極點,不像深度優先搜刮那樣有往回退的情形,是以它不是一個遞歸的算法。為了完成逐層的拜訪,算法必需借助一個幫助隊列,以記載正在拜訪的極點的下一層極點。
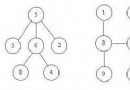
如上圖所示,為一個有向圖,從極點2開端廣度優先遍歷全部圖,可知成果為2,0,3,1。
2、BFS算法完成
與樹比擬,圖的分歧的地方在於它存在回路/環,是以在遍用時一個極點能夠被拜訪屢次。為了避免這類情形湧現,我們應用一個拜訪標志數組visited[]來標志極點能否曾經被拜訪過。
在廣度優先搜刮一個圖之前,我們起首要結構一個圖,圖的存儲方法重要有兩種:鄰接矩陣、鄰接表。這裡我們應用鄰接表來存儲圖:
簡略起見,我們先假定從肇端極點可以到達其他一切極點。以有向圖為例,C++代碼完成:
/*************************************************************************
> File Name: BFS.cpp
> Author: SongLee
************************************************************************/
#include<iostream>
#include<list>
using namespace std;
/* 鄰接表存儲有向圖 */
class Graph
{
int V; // 極點的數目
list<int> *adj; // 鄰接表
void BFSUtil(int v, bool visited[]);
public:
Graph(int V); // 結構函數
void addEdge(int v, int w); // 向圖中添加一條邊
void BFS(int v); // BFS遍歷
};
/***** 結構函數 *****/
Graph::Graph(int V)
{
this->V = V;
adj = new list<int>[V]; // 初始化V條鏈表
}
/* 添加邊,結構鄰接表 */
void Graph::addEdge(int v, int w)
{
adj[v].push_back(w); // 將w加到v的list
}
/* 從極點v動身廣度優先搜刮 */
void Graph::BFSUtil(int v, bool visited[])
{
// BFS幫助隊列
list<int> queue;
// 將以後極點標志為已拜訪並壓入隊列
visited[v] = true;
queue.push_back(v);
list<int>::iterator i;
while(!queue.empty())
{
// 出隊
v = queue.front();
cout << v << " ";
queue.pop_front();
// 檢測已出隊的極點s的一切鄰接極點
// 若存在還沒有拜訪的鄰接點,拜訪它並壓入隊列
for(i = adj[v].begin(); i!=adj[v].end(); ++i)
{
if(!visited[*i])
{
visited[*i] = true;
queue.push_back(*i);
}
}
}
}
/** 廣度優先搜刮 **/
void Graph::BFS(int v)
{
// 初始化拜訪標志數組
bool *visited = new bool[V];
for(int i=0; i<V; ++i)
visited[i] = false;
// 假定從給定極點可以達到圖的一切極點
BFSUtil(v, visited);
}
/* 測試 */
int main()
{
// 創立圖
Graph g(4);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(1, 2);
g.addEdge(2, 0);
g.addEdge(2, 3);
g.addEdge(3, 3);
cout << "Following is BFS Traversal (starting from vertex 2) \n";
g.BFS(2);
cout << endl;
return 0;
}
下面是假定從肇端極點開端可以或許拜訪到圖的一切極點。假如不克不及達到一切極點,即存在多個連通重量呢?那末我們就要對每一個連通重量都停止一次廣度優先搜刮。
偽代碼以下:
bool visited[MAX_VERTEXT_NUM]; // 拜訪標志數組
void BFS(Graph G) // 設拜訪函數為visit()
{
for(i=0; i<G.vexnum; ++i)
visited[i] = false; // 初始化
for(i=0; i<G.vexnum; ++i) // 從0號極點開端遍歷
if(!visited[i]) // 對每一個連通重量挪用一次BFS
BFS(G,i); // Vi未拜訪過,從Vi開端BFS
}
void BFSUtil(Graph G, int v)
{
visit(v); // 拜訪初始極點
visited[v] = true; // v已拜訪
Enqueue(Q, v); // 極點v入隊列
while(!isEmpty(Q))
{
Dequeue(Q, v); // 極點v出隊列
for(w=FirstNeighbor(G,v); w>=0; w=NextNeighbor(G,v))
if(!visited[w]) // 檢測v的一切鄰接點
{
visit(w); // 若w未拜訪,拜訪之
visited[w]=true; // 標志
Enqueue(Q, w); // 極點w入隊列
}
}
}
依據偽代碼,信任不難寫出關於多個連通重量的圖的廣度優先搜刮。我們只須要修正BFS()函數部門:
void Graph::BFS()
{
// 初始化拜訪標志數組
bool *visited = new bool[V];
for(int i=0; i<V; ++i)
visited[i] = false;
// 對每一個連通重量挪用一次BFSUtil(),從0號極點開端遍歷
for(int i=0; i<V; ++i)
if(!visited[i])
BFSUtil(i, visited);
}
關於無向圖的廣度優先搜刮,只是鄰接表紛歧樣,其他的都是一樣的。我們只須要修正addEdge(v, w)函數:
void Graph::addEdge(int v, int w)
{
adj[v].push_back(w); // 將w加到v的list
adj[w].push_back(v);
}
3、BFS算法機能剖析
1 . 空間龐雜度
不管是鄰接表照樣鄰接矩陣的存儲方法,BFS算法都須要借助一個幫助隊列Q,n個極點都須要入隊一次,在最壞的情形下,空間龐雜度為O(|V|)。
2 . 時光龐雜度
當采取鄰接表存儲時,每一個極點均需搜刮一次,故時光龐雜度為O(|V|),在搜刮任一極點的鄰接點時,每條邊至多拜訪一次,故時光龐雜度為O(|E|),算法總的時光龐雜度為O(|V|+|E|)。
當采取鄰接矩陣存儲時,查找每一個極點的鄰接點所需的時光為O(|V|),故算法總的時光龐雜度為O(|V|^2)。
注:廣度優先搜刮(BFS)算法思惟有許多運用,好比Dijkstra單源最短途徑算法和Prim最小生成樹算法。