C++疾速排序的剖析與優化詳解。本站提示廣大學習愛好者:(C++疾速排序的剖析與優化詳解)文章只能為提供參考,不一定能成為您想要的結果。以下是C++疾速排序的剖析與優化詳解正文
信任學過數據構造與算法的同伙關於疾速排序應當其實不生疏,本文就以實例講述了C++疾速排序的剖析與優化,關於C++算法的設計有很好的自創價值。詳細剖析以下:
1、疾速排序的引見
疾速排序是一種排序算法,對包括n個數的輸出數組,最壞的情形運轉時光為Θ(n2)[Θ 讀作theta]。固然這個最壞情形的運轉時光比擬差,但疾速排序平日是用於排序的最好的適用選擇。這是由於其均勻情形下的機能相當好:希冀的運轉時光為 Θ(nlgn),且Θ(nlgn)記號中隱含的常數因子很小。別的,它還可以或許停止當場排序,在虛擬內存情況中也能很好的任務。
和合並排序一樣,疾速排序也是基於分治法(Divide and conquer):
分化:數組A[p..r]被劃分紅兩個(能夠為空)的子數組A[p..q-1]和A[q+1..r],使得A[p..q-1]中的每一個元素都小於等於A[q],A[q+1..r]中的每一個元素都年夜於等於A[q]。如許元素A[q]就位於其終究地位上了。
處理:經由過程遞歸挪用疾速排序,對子數組A[p..q-1]和A[q+1..r]排序。
歸並:由於兩個子數組是當場排序,不須要歸並,全部數組已有序。
偽代碼以下:
PARTITION(A, p, r)
x = A[p]
i = p
for j=p+1 to r
do if A[j] <= x
then i = i+1
exchange(A[i],A[j])
exchange(A[p], A[i])
return i
QUICKSORT(A, p, r)
if p < r
then q = PARTITION(A, p, r)
QUICKSORT(A, p, q-1)
QUICKSORT(A, q+1, r)
2、機能剖析
1、最壞情形
疾速排序的最壞情形產生在當數組曾經有序或許逆序排好的情形下。如許的話劃分進程發生的兩個區域中有一個沒有元素,另外一個包括n-1個元素。此時算法的運轉時光可以遞歸地表現為:T(n) = T(n-1)+T(0)+Θ(n),遞歸式的解為T(n)=Θ(n^2)。可以看出,疾速排序算法最壞情形運轉時光其實不比拔出排序的更好。
2、最好情形
假如我們足夠榮幸,在每次劃分操作中做到最均衡的劃分,行將數組劃分為n/2:n/2。此時獲得的遞歸式為T(n) = 2T(n/2)+Θ(n),依據主定理的情形二可得T(n)=Θ(nlgn)。
3、均勻情形
假定一:快排中的劃分點異常偏斜,好比每次都將數組劃分為1/10 : 9/10的兩個子區域,這類情形下運轉時光是若干呢?運轉時光遞歸式為T(n) = T(n/10)+T(9n/10)+Θ(n),應用遞歸樹解得T(n)=Θ(nlgn)。可以看出,當劃分點異常偏斜的時刻,運轉時光依然是Θ(nlgn)。
假定二:Partition所發生的劃分既有“好的”,也有“差的”,它們瓜代湧現。這類均勻情形下運轉時光又是若干呢?這時候的遞歸式為(G表現Good,B表現Bad):
G(n) = 2B(n/2) + Θ(n)
B(n) = G(n-1) + Θ(n)
解:G(n) = 2(G(n/2-1) + Θ(n/2)) + Θ(n) = 2G(n/2-1) + Θ(n) = Θ(nlgn)
可以看出,當好、差劃分瓜代湧現時,快排的運轉時光就如滿是好的劃分一樣,依然是Θ(nlgn) 。
3、快排的優化
經由下面的剖析可以曉得,在輸出有序或逆序時疾速排序很慢,在其他情形則表示優越。假如輸出自己已被排序,那末就糟了。那末我們若何確保關於一切輸 入,它均可以或許取得較好的均勻情形機能呢?後面的疾速排序我們默許應用數組中第一個元素作為主元。假定隨機選擇數組中的元素作為主元,則快排的運轉時光將不 依附於輸出序列的次序。我們把隨機選擇主元的疾速排序叫做Randomized Quicksort。
在隨機化的疾速排序中,我們不是一直選擇第一個元素作為主元,而是從數組A[p…r]中隨機選擇一個元素,然後將其與第一個元故舊換。因為主元元素是隨機選擇的,我們希冀在均勻情形下,對輸出數組的劃分可以或許比擬對稱。
偽代碼以下:
RANDOMIZED-PARTITION(A, p, r)
i = RANDOM(p, r)
exchange(A[p], A[i])
return PARTITION(A, p, r)
RANDOMIZED-QUICKSORT(A, p, r)
if p < r
then q = RANDOMIZED-PARTITION(A, p, r)
RANDOMIZED-QUICKSORT(A, p, q-1)
RANDOMIZED-QUICKSORT(A, q+1, r)
我們對3萬個元素的有序序列分離停止傳統的疾速排序 和 隨機化的疾速排序,並比擬它們的運轉時光:
/*************************************************************************
> File Name: QuickSort.cpp
> Author: SongLee
************************************************************************/
#include<iostream>
#include<cstdlib> // srand rand
#include<ctime> // clock_t clock
using namespace std;
void swap(int &a, int &b)
{
int tmp = a;
a = b;
b = tmp;
}
// 傳統劃分操作
int Partition(int A[], int low, int high)
{
int pivot = A[low];
int i = low;
for(int j=low+1; j<=high; ++j)
{
if(A[j] <= pivot)
{
++i;
swap(A[i], A[j]);
}
}
swap(A[i], A[low]);
return i;
}
// 隨機化劃分操作,隨機選擇pivot
int Partition_Random(int A[], int low, int high)
{
srand(time(NULL));
int i = rand() % (high+1);
swap(A[low], A[i]);
return Partition(A, low, high);
}
// 傳統快排
void QuickSort(int A[], int low, int high)
{
if(low < high)
{
int pos = Partition(A, low, high);
QuickSort(A, low, pos-1);
QuickSort(A, pos+1, high);
}
}
// 隨機化疾速排序
void QuickSort_Random(int A[], int low, int high)
{
if(low < high)
{
int pos = Partition_Random(A, low, high);
QuickSort_Random(A, low, pos-1);
QuickSort_Random(A, pos+1, high);
}
}
int main()
{
clock_t t1, t2;
// 初始化數組
int A[30000];
for(int i=0; i<30000; ++i)
A[i] = i+1;
t1 = clock();
QuickSort(A, 0, 30000-1);
t1 = clock() - t1;
cout << "Traditional quicksort took "<< t1 << " clicks(about " << ((float)t1)/CLOCKS_PER_SEC << " seconds)." << endl;
t2 = clock();
QuickSort_Random(A, 0, 30000-1);
t2 = clock() - t2;
cout << "Randomized quicksort took "<< t2 << " clicks(about " << ((float)t2)/CLOCKS_PER_SEC << " seconds)." << endl;
return 0;
}
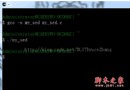
運轉成果以下:
[songlee@localhost ~]$ ./QuickSort Traditional quicksort took 1210309 clicks(about 1.21031 seconds). Randomized quicksort took 457573 clicks(about 0.457573 seconds). [songlee@localhost ~]$ ./QuickSort Traditional quicksort took 1208038 clicks(about 1.20804 seconds). Randomized quicksort took 644950 clicks(about 0.64495 seconds).
從運轉成果可以看出,關於有序的輸出,隨機化版本的疾速排序的效力會高許多。
成績記載:
我們曉得交流兩個變量的值有以下三種辦法:
int tmp = a; // 辦法一 a = b; b = tmp a = a+b; // 辦法二 b = a-b; a = a-b; a = a^b; // 辦法三 b = a^b; a = a^b;
然則你會發明在本法式中,假如swap函數應用前面兩種辦法會失足。因為辦法二和辦法三沒有應用中央變量,它們交流值的道理是直接對變量的內存單位停止操作。假如兩個變量對應的統一內存單位,則經由兩次加減或異或操作,內存單位的值曾經變成了0,因此不克不及完成變量值交流。所以當須要交流值的變量能夠是統一變量時,必需應用第三變量完成交流,不然會對變量清零。