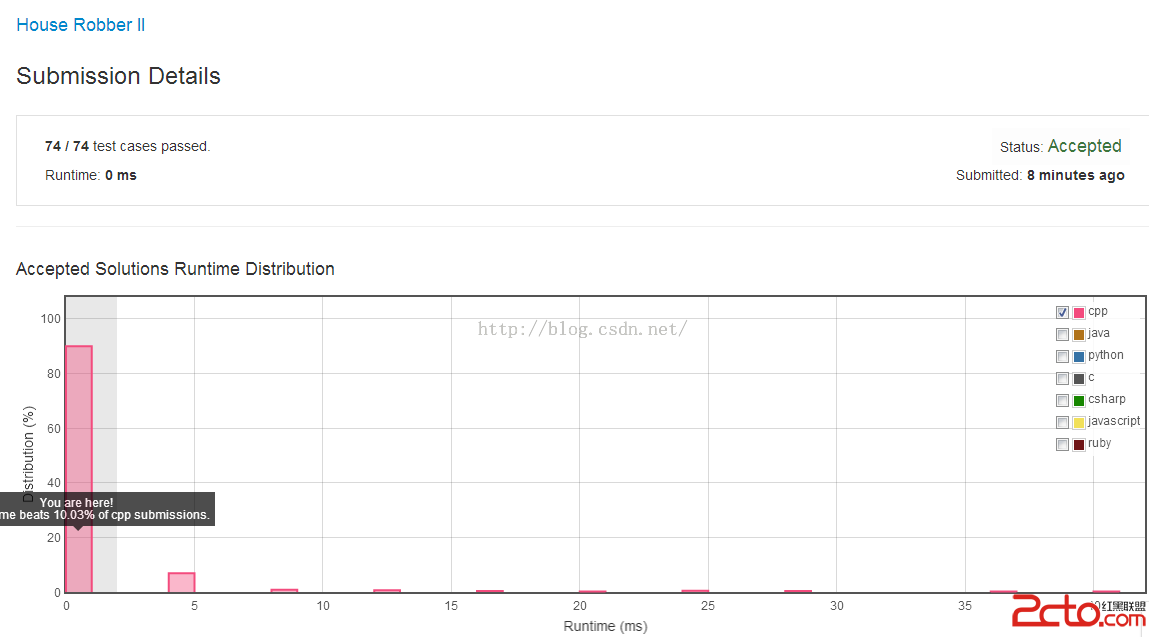
數據構造之堆詳解。本站提示廣大學習愛好者:(數據構造之堆詳解)文章只能為提供參考,不一定能成為您想要的結果。以下是數據構造之堆詳解正文
1. 概述
堆(也叫優先隊列),是一棵完整二叉樹,它的特色是父節點的值年夜於(小於)兩個子節點的值(分離稱為年夜頂堆和小頂堆)。它經常使用於治理算法履行進程中的信息,運用場景包含堆排序,優先隊列等。
2. 堆的根本操作
堆是一棵完整二叉樹,高度為O(lg n),其根本操作至少與樹的高度成反比。在引見堆的根本操作之前,先引見幾個根本術語:
A:用於表現堆的數組,下標從1開端,一向到n
PARENT(t):節點t的父節點,即floor(t/2)
RIGHT(t):節點t的左孩子節點,即:2*t
LEFT(t):節點t的右孩子節點,即:2*t+1
HEAP_SIZE(A):堆A以後的元素數量
上面給出其重要的四個操作(以年夜頂堆為例):
2.1 Heapify(A,n,t)
該操作重要用於保持堆的根本性質。假定以RIGHT(t)和LEFT(t)為根的子樹都曾經是堆,然後調劑以t為根的子樹,使之成為堆。
void Heapify(int A[], int n, int t)
{
int left = LEFT(t);
int right = RIGHT(t);
int max = t;
if(left <= n) max = A[left] > A[max] ? left : max;
if(right <= n) max = A[right] > A[max] ? right : max;
if(max != A[t])
{
swap(A, max, t);
Heapify(A, n, max);
}
}
2.2 BuildHeap(A,n)
該操作重要是將數組A轉化成一個年夜頂堆。思惟是,先找到堆的最初一個非葉子節點(即為第n/2個節點),然後從該節點開端,從後往前逐一調劑每一個子樹,使之稱為堆,終究全部數組就是一個堆。
void BuildHeap(int A[], int n)
{
int i;
for(i = n/2; i<=n; i++)
Heapify(A, n, i);
}
2.3 GetMaximum(A,n)
該操作重要是獲得堆中最年夜的元素,同時堅持堆的根本性質。堆的最年夜元素即為第一個元素,將其保留上去,同時將最初一個元素放到A[1]地位,以後從上往下調劑A,使之成為一個堆。
void GetMaximum(int A[], int n)
{
int max = A[1];
A[1] = A[n];
n--;
Heapify(A, n, 1);
return max;
}
2.4 Insert(A, n, t)
向堆中添加一個元素t,同時堅持堆的性質。算法思惟是,將t放到A的最初,然後從該元素開端,自下向上調劑,直至A成為一個年夜頂堆。
void Insert(int A[], int n, int t)
{
n++;
A[n] = t;
int p = n;
while(p >1 && A[PARENT(p)] < t)
{
A[p] = A[PARENT(p)];
p = PARENT(p);
}
A[p] = t;
return max;
}
3. 堆的運用
3.1 堆排序
堆的最多見運用是堆排序,時光龐雜度為O(N lg N)。假如是從小到年夜排序,用年夜頂堆;從年夜到小排序,用小頂堆。
3.2 在O(n lg k)時光內,將k個排序表歸並成一個排序表,n為一切有序表中元素個數。
【解析】取前100 萬個整數,結構成了一棵數組方法存儲的具有小頂堆,然後接著順次取下一個整數,假如它年夜於最小元素亦即堆頂元素,則將其付與堆頂元素,然後用Heapify調劑全部堆,如斯下去,則最初留在堆中的100萬個整數即為所求 100萬個數字。該辦法可年夜年夜勤儉內存。
3.3 一個文件中包括了1億個隨機整數,若何疾速的找到最年夜(小)的100萬個數字?(時光龐雜度:O(n lg k))
4. 總結
堆是一種異常基本但很適用的數據構造,許多龐雜算法或許數據構造的基本就是堆,因此,懂得和控制堆這類數據構造顯得尤其主要。
5. 參考材料
(1)經典算法教程《算法導論》