應用C說話處理字符串全分列成績。本站提示廣大學習愛好者:(應用C說話處理字符串全分列成績)文章只能為提供參考,不一定能成為您想要的結果。以下是應用C說話處理字符串全分列成績正文
成績
輸出一個字符串,打印出該字符串中字符的一切分列。例如輸出字符串abc,則輸入由字符a,b,c所能分列出來的一切字符串abc,acb,bac,bca,cab和cba
思緒
這是典范的遞歸求解成績,遞歸算法有四個特征:
關於字符串的分列成績:
假如能生成n-1個元素的全分列,就可以生成n個元素的全分列。關於只要一個元素的聚集,可以直接生玉成分列。所以全分列的遞歸終止前提很明白,只要一個元素時。我們可以剖析一下全分列的進程:
上面這張圖很清晰的給出了遞歸的進程:
根本處理辦法
辦法1:順次從字符串中掏出一個字符作為終究分列的第一個字符,對殘剩字符構成的字符串生玉成分列,終究成果為掏出的字符和殘剩子串全分列的組合。
#include <iostream>
#include <string>
using namespace std;
void permute1(string prefix, string str)
{
if(str.length() == 0)
cout << prefix << endl;
else
{
for(int i = 0; i < str.length(); i++)
permute1(prefix+str[i], str.substr(0,i)+str.substr(i+1,str.length()));
}
}
void permute1(string s)
{
permute1("",s);
}
int main()
{
//method1, unable to remove duplicate permutations.
cout << "method1" << endl;
permute1("ABA");
}
長處:該辦法易於懂得,但沒法移除反復的分列,如:s="ABA",會生成兩個“AAB”。
辦法2:應用交流的思惟,詳細見實例,但該辦法不如辦法1輕易懂得。
#include <iostream>
#include <string>
#include <cstdio>
using namespace std;
void swap(char* x, char* y)
{
char tmp;
tmp = *x;
*x = *y;
*y = tmp;
}
/* Function to print permutations of string
This function takes three parameters:
1. String
2. Starting index of the string
3. Ending index of the string. */
void permute(char *a, int i, int n)
{
int j;
if (i == n)
printf("%s\n", a);
else
{
for (j = i; j <= n; j++)
{
if(a[i] == a[j] && j != i) //為防止生成反復分列,當分歧地位的字符雷同時不再交流
continue;
swap((a+i), (a+j));
permute(a, i+1, n);
swap((a+i), (a+j)); //backtrack
}
}
}
int main()
{
//method2
cout << "method2" << endl;
char a[] = "ABA";
permute(a,0,2);
return 0;
}
兩種辦法的生成成果:
method1 ABA AAB BAA BAA AAB ABA method2 ABA AAB BAA
上面來看ACM標題實例
示例標題
標題描寫
標題描寫:
給定一個由分歧的小寫字母構成的字符串,輸入這個字符串的一切全分列。
我們假定關於小寫字母有'a' < 'b' < ... < 'y' < 'z',並且給定的字符串中的字母曾經依照從小到年夜的次序分列。
輸出:
輸出只要一行,是一個由分歧的小寫字母構成的字符串,已知字符串的長度在1到6之間。
輸入:
輸入這個字符串的一切分列方法,每行一個分列。請求字母序比擬小的分列在後面。字母序以下界說:
已知S = s1s2...sk , T = t1t2...tk,則S < T 等價於,存在p (1 <= p <= k),使得
s1 = t1, s2 = t2, ..., sp - 1 = tp - 1, sp < tp成立。
樣例輸出:
abc
樣例輸入:
abc
acb
bac
bca
cab
cba
提醒:
每組樣例輸入停止後要再輸入一個回車。
ac代碼
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct seq
{
char str[7];
};
struct seq seqs[721];
int count;
void swap(char *str, int a, int b)
{
char temp;
temp = str[a];
str[a] = str[b];
str[b] = temp;
}
void permutation_process(char *name, int begin, int end) {
int k;
if (begin == end - 1) {
strcpy(seqs[count].str, name);
count ++;
}else {
for (k = begin; k < end; k ++) {
swap(name, k, begin);
permutation_process(name, begin + 1, end);
swap(name, k, begin);
}
}
}
int compare(const void *p, const void *q)
{
const char *a = p;
const char *b = q;
return strcmp(a, b);
}
int main()
{
char name[7];
int i, len;
while (scanf("%s", name) != EOF) {
count = 0;
len = strlen(name);
permutation_process(name, 0, len);
qsort(seqs, count, sizeof(seqs[0]), compare);
for (i = 0; i < count; i ++) {
printf("%s\n", seqs[i].str);
}
printf("\n");
}
return 0;
}
/**************************************************************
Problem: 1120
User: wangzhengyi
Language: C
Result: Accepted
Time:710 ms
Memory:920 kb
****************************************************************/
去失落反復的全分列
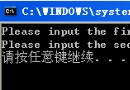
上述代碼有個缺點,就是會形成反復數據的輸入,例如abb這類字符串,上述法式跑結束果如圖:
因為全分列就是從第一個數字起,每一個數分離與它前面的數字交流,我們先測驗考試加個如許的斷定——假如一個數與前面的數字雷同那末這兩個數就不交流了。例如abb,第一個數與前面兩個數交流得bab,bba。然後abb中第二個數和第三個數雷同,就不消交流了。然則對bab,第二個數和第三個數分歧,則須要交流,獲得bba。因為這裡的bba和開端第一個數與第三個數交流的成果雷同了,是以這個辦法不可。
換種思想,對abb,第一個數a與第二個數b交流獲得bab,然後斟酌第一個數與第三個數交流,此時因為第三個數等於第二個數,所以第一個數就不再用與第三個數交流了。再斟酌bab,它的第二個數與第三個數交流可以處理bba。此時全分列生成終了!
如許,我們獲得在全分列中去失落反復的規矩:
去重的全分列就是從第一個數字起,每一個數分離與它前面非反復湧現的數字交流。
貼出下面ac代碼的去再版本:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct seq
{
char str[7];
};
struct seq seqs[721];
int count;
int is_swap(char *str, int begin, int k)
{
int i, flag;
for (i = begin, flag = 1; i < k; i ++) {
if (str[i] == str[k]) {
flag = 0;
break;
}
}
return flag;
}
void swap(char *str, int a, int b)
{
char temp;
temp = str[a];
str[a] = str[b];
str[b] = temp;
}
void permutation_process(char *name, int begin, int end) {
int k;
if (begin == end - 1) {
strcpy(seqs[count].str, name);
count ++;
}else {
for (k = begin; k < end; k ++) {
if (is_swap(name, begin, k)) {
swap(name, k, begin);
permutation_process(name, begin + 1, end);
swap(name, k, begin);
}
}
}
}
int compare(const void *p, const void *q)
{
const char *a = p;
const char *b = q;
return strcmp(a, b);
}
int main()
{
char name[7];
int i, len;
while (scanf("%s", name) != EOF) {
count = 0;
len = strlen(name);
permutation_process(name, 0, len);
qsort(seqs, count, sizeof(seqs[0]), compare);
for (i = 0; i < count; i ++) {
printf("%s\n", seqs[i].str);
}
printf("\n");
}
return 0;
}