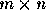經常使用排序算法的C說話版完成示例整頓。本站提示廣大學習愛好者:(經常使用排序算法的C說話版完成示例整頓)文章只能為提供參考,不一定能成為您想要的結果。以下是經常使用排序算法的C說話版完成示例整頓正文
所謂排序,就是要整頓文件中的記載,使之按症結字遞增(或遞加)順序分列起來。其確實界說以下:
輸出:n個記載R1,R2,…,Rn,其響應的症結字分離為K1,K2,…,Kn。
輸入:Ril,Ri2,…,Rin,使得Ki1≤Ki2≤…≤Kin。(或Ki1≥Ki2≥…≥Kin)。
排序的時光開支可用算法履行中的數據比擬次數與數據挪動次數來權衡。根本的排序算法有以下幾種:交流排序(冒泡排序、疾速排序)、選擇排序(直接選擇排序、堆排序)、拔出排序(直接拔出排序、希爾排序)、合並排序、分派排序(基數排序、箱排序、計數排序)。上面順次列出各類算法的代碼,並停止扼要剖析。分派排序算法的代碼沒有列出。
(1)疾速排序:疾速排序是C.R.A.Hoare於1962年提出的一種劃分交流排序。它采取了一種分治的戰略,平日稱其為分治法(Divide-and-ConquerMethod)。最好、均勻龐雜度都為O(nlogn),最壞為O(n^2)。
void quick_sort1(int a[],int l,int r)
{
if(l >= r)
return;
int i, j, p;
i = l-1, j = l,p = a[r];
while(j < r)
{
if(a[j] < p)
swap(a[++i], a[j]);
j++;
}
swap(a[++i], a[r]);
quick_sort1(a, l, i-1);
quick_sort1(a, i+1, r);
}
《算法導論》一書中,給出了這個法式的偽代碼。當數組元素相等、逆序、次序分列時,挪用這個法式會招致棧溢出。由於每次劃分都是最壞壞分。可以改良一下。上述法式每次選的劃分基准元素都是固定的,假如是隨機發生的,那末可以年夜年夜下降湧現最壞劃分的幾率。
void quick_sort2(int a[],int l,int r)
{
if(l >= r)
return;
int i,j,p;
i = l-1,j = l;
p=l + rand()%(r-l); //隨機發生[l,r)之間的數
swap(a[p], a[r]);
p = a[r];
while(j < r)
{
if(a[j] < p)
swap(a[++i], a[j]);
j++;
}
swap(a[++i], a[r]);
quick_sort2(a, l, i-1);
quick_sort2(a, i+1, r);
}
然則,當數組元素相等時,照樣湧現了棧溢出。可以做以下調劑。
void quick_sort3(int a[],int l,int r)
{
if(l >= r)
return;
int i,j,p;
i = l-1, j = r, p = a[r];
while(1)
{
do { i++; } while(a[i] < p && i < r);
do { j--; } while(a[j] > p && j > l);
if(i >= j)
break;
swap(a[i], a[j]);
}
swap(a[i],a[r]);
quick_sort3(a, l, i-1);
quick_sort3(a, i+1, r);
}
然則,當數組元素次序,逆序時,異樣湧現了棧溢出。若將二者聯合起來,便可以盡可能防止棧溢出。
void quick_sort4(int a[],int l,int r)
{
if(l >= r)
return;
int i,j,p;
i = l-1, j = r;
p = l + rand()%(r-l);
swap(a[p],a[r]);
p = a[r];
while(1)
{
do { i++; } while(a[i] < p && i < r);
do { j--; } while(a[j] > p && j > l);
if(i >= j)
break;
swap(a[i], a[j]);
}
swap(a[i], a[r]);
quick_sort4(a, l, i-1);
quick_sort4(a, i+1, r);
}
(2)冒泡排序:兩兩比擬待排序記載的症結字,發明兩個記載的順序相反時即停止交流,直到沒有反序的記載為止。
void bubble_sort1(int a[],int n)
{
int i,j;
for(i = 0; i < n-1; i++)
{
for(j = i+1; j < n; j++)
{
if(a[i] > a[j])
swap(a[i], a[j]);
}
}
}
可以稍作改良,當數組數元素次序時,時光龐雜度為O(n)。參加一個變量,假如在一遍掃描中,沒有湧現交流,那末停止排序,由於數組已排好序了。
void bubble_sort2(int a[],int n)
{
int i,j;
for(i = 0; i < n-1; i++)
{
bool exchange = false;
for(j = i+1; j < n; j++)
{
if(a[i] > a[j])
{
exchange = true;
swap(a[i], a[j]);
}
}
if(exchange == false)
break;
}
}
經網友指出,下面這個冒泡排序有成績,沒法獲得准確成果。上面引自網友的准確寫法:
void bubble_sort2(int a[],int n)
{
int i,j;
for(i = 0;i < n-1; i++)
{
bool exchange = false;
for(j = n-1;j > i; j--)
{
if(a[j-1] > a[j])
{
exchange = true;
swap(a[j-1], a[j]);
}
}
if(exchange == false)
break;
}
}
(3)直接選擇排序:每趟從待排序的記載當選出症結字最小的記載,次序放在已排好序的子文件的最初,直到全體記載排序終了。
void select_sort1(int a[],int n)
{
int i,j;
for(i = 0; i < n-1; i++)
{
int min = i;
for(j = i+1; j < n; j++)
{
if(a[j] < a[min])
min = j;
}
if(min != i)
swap(a[i], a[min]);
}
}
(4)堆排序:依據輸出數據,應用堆的調劑算法構成初始堆,然後交流根元素與尾元素,總的元素個數減1,然後從根往下調劑。堆排序的最好、最壞、均勻時光龐雜度都為O(nlogn)
void heap_siftdown(int a[],int n,int p) //調劑算法
{
int i = p,j = i*2+1;
int tmp = a[i];
while(j < n)
{
if(j+1 < n && a[j] < a[j+1])
j++;
if(a[j] <= tmp)
break;
else
{
a[i] = a[j];
i = j;j = j*2+1;
}
}
a[i] = tmp;
}
void heap_sort1(int a[],int n)
{
int i;
for(i = (n-1)/2; i >= 0;i--)
heap_siftdown(a, n, i);
for(i = n-1;i >= 0; i--)
{
swap(a[i], a[0]);
heap_siftdown(a, i, 0);
}
}
(5)直接拔出排序:每次將一個待排序的記載,按其症結字年夜小拔出到後面曾經排好序的子文件中的恰當地位,直到全體記載拔出完成為止。當數組曾經排好序,直接拔出排序的時光龐雜度為O(n)
void insert_sort1(int a[],int n)
{
int i,j;
for(i = 1; i < n; i++)
{
for(j = i; j > 0 && a[j]<a[j-1]; j--)
swap(a[j-1], a[j]);
}
}
假如將交流函數睜開,可以加速排序的速度。
void insert_sort2(int a[],int n)
{
int i,j;
for(i = 1; i < n; i++)
{
for(j = i; j > 0 && a[j] < a[j-1]; j--)
{
int t = a[j-1];
a[j-1] = a[j];
a[j] = t;
}
}
}
可以進一步改良,insert_sort2的算法赓續給t賦值,可以將賦值語句移到輪回裡面。
void insert_sort3(int a[],int n)
{
int i,j;
for(i = 1;i < n; i++)
{
int t = a[i];
for(j = i; j > 0 && a[j-1] > t; j--)
a[j] = a[j-1];
a[j] = t;
}
}
(6)希爾排序:先取一個小於n的整數d1作為第一個增量,把文件的全體記載分紅d1個組。一切間隔為dl的倍數的記載放在統一個組中。先在各組內停止直接插人排序;然後,取第二個增量d2<d1反復上述的分組和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即一切記載放在統一組中停止直接拔出排序為止。
最初一遍的增量必需是1,實際上是就是挪用直接拔出排序算法。
void shell_sort1(int a[],int n)
{
int i = n;
do{
i = i/3 + 1;
shell_pass1(a, n, i);
}while(i > 1);
}
void shell_pass1(int a[],int n,int inc) //inc為1時,其實就是直接拔出排序
{
int i,j;
for(i = inc; i < n; i++)
{
int t=a[i];
for(j = i;j >= inc && a[j-inc] > t; j-= inc)
a[j] = a[j-inc];
a[j] = t;
}
}
(7)合並排序:應用"合並"技巧來停止排序。合並是指將若干個已排序的子文件歸並成一個有序的文件。可以用於外排序。
void merge_sort1(int a[],int b[],int l,int r)
{
if(l >= r)
return;
int m = (l+r)/2;
merge_sort1(a, b, l, m);
merge_sort1(a, b, m+1, r);
merge1(a, b, l, m, r);
}
void merge1(int a[],int b[],int l,int m,int r)
{
int i,j,k;
for(i = l; i <= r; i++)
b[i] = a[i];
i = l; j = m+1; k = l;
while(i <= m && j <= r)
{
if(b[i] <= b[j]) a[k++] = b[i++];
else a[k++] = b[j++];
}
while(i <= m) a[k++] = b[i++];
while(j <= r) a[k++] = b[j++];
}
給出上述算法的法式的測試驅動法式及兩個幫助法式。要測試某種排序算法,只需將正文去失落便可。
#include <iostream>
#include <ctime>
using namespace std;
const int N = 100;
int a[N];
int b[N];
int main()
{
int i;
srand(time(0));
//for(i=0;i<N;i++)
// a[i]= N-i;
for(i = 0;i < N; i++)
a[i]=rand()%N;
long start,end;
start = clock();
//quick_sort1(a,0,N-1);
//quick_sort2(a,0,N-1);
//quick_sort3(a,0,N-1);
//quick_sort4(a,0,N-1);
//bubble_sort1(a,N);
//bubble_sort2(a,N);
//merge_sort1(a,b,0,N-1);
//heap_sort1(a,N);
//shell_sort1(a,N);
//select_sort1(a,N);
//insert_sort1(a,N);
//insert_sort2(a,N);
//insert_sort3(a,N);
end = clock();
print_array(a, N);
cout<<"total time is : "<<(end-start)/1000.0<<'s'<<endl;
return 0;
}
void swap(int a[],int i,int j) //交流元素
{
int t = a[i];
a[i] = a[j];
a[j] = t;
}
void print_array(int a[],int n) //打印元素值
{
for(int i = 0; i < n; i++)
{
cout<<a[i]<<' ';
if(i%10==0 && i!=0)
cout<<endl;
}
cout<<endl;
}