詳解C++中StringBuilder類的完成及其機能優化。本站提示廣大學習愛好者:(詳解C++中StringBuilder類的完成及其機能優化)文章只能為提供參考,不一定能成為您想要的結果。以下是詳解C++中StringBuilder類的完成及其機能優化正文
引見
常常湧現客戶端打德律風埋怨說:你們的法式慢如蝸牛。你開端檢討能夠的疑點:文件IO,數據庫拜訪速度,乃至檢查web辦事。 然則這些能夠的疑點都很正常,一點成績都沒有。
你應用最隨手的機能剖析對象剖析,發明瓶頸在於一個小函數,這個函數的感化是將一個長的字符串鏈表寫到一文件中。
你對這個函數做了以下優化:將一切的小字符串聯接成一個長的字符串,履行一次文件寫入操作,防止不計其數次的小字符串寫文件操作。
這個優化只做對了一半。
你先測試年夜字符串寫文件的速度,發明快如閃電。然後你再測試一切字符串拼接的速度。
好幾年。
怎樣回事?你會怎樣戰勝這個成績呢?
你也許曉得.net法式員可使用StringBuilder來處理此成績。這也是本文的終點。
配景
假如谷歌一下“C++ StringBuilder”,你會獲得很多謎底。有些會建議(你)應用std::accumulate,這可以完成簡直一切你要完成的:
#include <iostream>// for std::cout, std::endl
#include <string> // for std::string
#include <vector> // for std::vector
#include <numeric> // for std::accumulate
int main()
{
using namespace std;
vector<string> vec = { "hello", " ", "world" };
string s = accumulate(vec.begin(), vec.end(), s);
cout << s << endl; // prints 'hello world' to standard output.
return 0;
}
今朝為止一切都好:當你有跨越幾個字符串聯接時,成績就湧現了,而且內存再分派也開端積聚。
std::string在函數reserver()中為處理計劃供給基本。這也恰是我們的意圖地點:一次分派,隨便銜接。
字符串聯接能夠會由於沉重、緩慢的對象而嚴重影響機能。因為前次存在的隱患,這個特別的怪胎給我制作費事,我便廢棄了Indigo(我想測驗考試一些C++11裡的使人線人一新的特征),並寫了一個StringBuilder類的部門完成:
// Subset of http://msdn.microsoft.com/en-us/library/system.text.stringbuilder.aspx
template <typename chr>
class StringBuilder {
typedef std::basic_string<chr> string_t;
typedef std::list<string_t> container_t; // Reasons not to use vector below.
typedef typename string_t::size_type size_type; // Reuse the size type in the string.
container_t m_Data;
size_type m_totalSize;
void append(const string_t &src) {
m_Data.push_back(src);
m_totalSize += src.size();
}
// No copy constructor, no assignement.
StringBuilder(const StringBuilder &);
StringBuilder & operator = (const StringBuilder &);
public:
StringBuilder(const string_t &src) {
if (!src.empty()) {
m_Data.push_back(src);
}
m_totalSize = src.size();
}
StringBuilder() {
m_totalSize = 0;
}
// TODO: Constructor that takes an array of strings.
StringBuilder & Append(const string_t &src) {
append(src);
return *this; // allow chaining.
}
// This one lets you add any STL container to the string builder.
template<class inputIterator>
StringBuilder & Add(const inputIterator &first, const inputIterator &afterLast) {
// std::for_each and a lambda look like overkill here.
// <b>Not</b> using std::copy, since we want to update m_totalSize too.
for (inputIterator f = first; f != afterLast; ++f) {
append(*f);
}
return *this; // allow chaining.
}
StringBuilder & AppendLine(const string_t &src) {
static chr lineFeed[] { 10, 0 }; // C++ 11. Feel the love!
m_Data.push_back(src + lineFeed);
m_totalSize += 1 + src.size();
return *this; // allow chaining.
}
StringBuilder & AppendLine() {
static chr lineFeed[] { 10, 0 };
m_Data.push_back(lineFeed);
++m_totalSize;
return *this; // allow chaining.
}
// TODO: AppendFormat implementation. Not relevant for the article.
// Like C# StringBuilder.ToString()
// Note the use of reserve() to avoid reallocations.
string_t ToString() const {
string_t result;
// The whole point of the exercise!
// If the container has a lot of strings, reallocation (each time the result grows) will take a serious toll,
// both in performance and chances of failure.
// I measured (in code I cannot publish) fractions of a second using 'reserve', and almost two minutes using +=.
result.reserve(m_totalSize + 1);
// result = std::accumulate(m_Data.begin(), m_Data.end(), result); // This would lose the advantage of 'reserve'
for (auto iter = m_Data.begin(); iter != m_Data.end(); ++iter) {
result += *iter;
}
return result;
}
// like javascript Array.join()
string_t Join(const string_t &delim) const {
if (delim.empty()) {
return ToString();
}
string_t result;
if (m_Data.empty()) {
return result;
}
// Hope we don't overflow the size type.
size_type st = (delim.size() * (m_Data.size() - 1)) + m_totalSize + 1;
result.reserve(st);
// If you need reasons to love C++11, here is one.
struct adder {
string_t m_Joiner;
adder(const string_t &s): m_Joiner(s) {
// This constructor is NOT empty.
}
// This functor runs under accumulate() without reallocations, if 'l' has reserved enough memory.
string_t operator()(string_t &l, const string_t &r) {
l += m_Joiner;
l += r;
return l;
}
} adr(delim);
auto iter = m_Data.begin();
// Skip the delimiter before the first element in the container.
result += *iter;
return std::accumulate(++iter, m_Data.end(), result, adr);
}
}; // class StringBuilder
函數ToString()應用std::string::reserve()來完成最小化再分派。上面你可以看到一特性能測試的成果。
函數join()應用std::accumulate(),和一個曾經為首個操作數預留內存的自界說函數。
你能夠會問,為何StringBuilder::m_Data用std::list而不是std::vector?除非你有一個用其他容器的好來由,平日都是應用std::vector。
好吧,我(如許做)有兩個緣由:
1. 字符串老是會附加到一個容器的末尾。std::list許可在不須要內存再分派的情形下如許做;由於vector是應用一個持續的內存塊完成的,每用一個便可能招致內存再分派。
2. std::list對次序存取相當有益,並且在m_Data上所做的獨一存取操作也是次序的。
你可以建議同時測試這兩種完成的機能和內存占用情形,然後選擇個中一個。
機能評價
為了測試機能,我從Wikipedia獲得一個網頁,並將個中一部門內容寫逝世到一個string的vector中。
隨後,我編寫兩個測試函數,第一個在兩個輪回中應用尺度函數clock()並挪用std::accumulate()和StringBuilder::ToString(),然後打印成果。
void TestPerformance(const StringBuilder<wchar_t> &tested, const std::vector<std::wstring> &tested2) {
const int loops = 500;
clock_t start = clock(); // Give up some accuracy in exchange for platform independence.
for (int i = 0; i < loops; ++i) {
std::wstring accumulator;
std::accumulate(tested2.begin(), tested2.end(), accumulator);
}
double secsAccumulate = (double) (clock() - start) / CLOCKS_PER_SEC;
start = clock();
for (int i = 0; i < loops; ++i) {
std::wstring result2 = tested.ToString();
}
double secsBuilder = (double) (clock() - start) / CLOCKS_PER_SEC;
using std::cout;
using std::endl;
cout << "Accumulate took " << secsAccumulate << " seconds, and ToString() took " << secsBuilder << " seconds."
<< " The relative speed improvement was " << ((secsAccumulate / secsBuilder) - 1) * 100 << "%"
<< endl;
}
第二個則應用更准確的Posix函數clock_gettime(),並測試StringBuilder::Join()。
#ifdef __USE_POSIX199309
// Thanks to <a href="http://www.guyrutenberg.com/2007/09/22/profiling-code-using-clock_gettime/">Guy Rutenberg</a>.
timespec diff(timespec start, timespec end)
{
timespec temp;
if ((end.tv_nsec-start.tv_nsec)<0) {
temp.tv_sec = end.tv_sec-start.tv_sec-1;
temp.tv_nsec = 1000000000+end.tv_nsec-start.tv_nsec;
} else {
temp.tv_sec = end.tv_sec-start.tv_sec;
temp.tv_nsec = end.tv_nsec-start.tv_nsec;
}
return temp;
}
void AccurateTestPerformance(const StringBuilder<wchar_t> &tested, const std::vector<std::wstring> &tested2) {
const int loops = 500;
timespec time1, time2;
// Don't forget to add -lrt to the g++ linker command line.
////////////////
// Test std::accumulate()
////////////////
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time1);
for (int i = 0; i < loops; ++i) {
std::wstring accumulator;
std::accumulate(tested2.begin(), tested2.end(), accumulator);
}
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time2);
using std::cout;
using std::endl;
timespec tsAccumulate =diff(time1,time2);
cout << tsAccumulate.tv_sec << ":" << tsAccumulate.tv_nsec << endl;
////////////////
// Test ToString()
////////////////
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time1);
for (int i = 0; i < loops; ++i) {
std::wstring result2 = tested.ToString();
}
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time2);
timespec tsToString =diff(time1,time2);
cout << tsToString.tv_sec << ":" << tsToString.tv_nsec << endl;
////////////////
// Test join()
////////////////
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time1);
for (int i = 0; i < loops; ++i) {
std::wstring result3 = tested.Join(L",");
}
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time2);
timespec tsJoin =diff(time1,time2);
cout << tsJoin.tv_sec << ":" << tsJoin.tv_nsec << endl;
////////////////
// Show results
////////////////
double secsAccumulate = tsAccumulate.tv_sec + tsAccumulate.tv_nsec / 1000000000.0;
double secsBuilder = tsToString.tv_sec + tsToString.tv_nsec / 1000000000.0;
double secsJoin = tsJoin.tv_sec + tsJoin.tv_nsec / 1000000000.0;
cout << "Accurate performance test:" << endl << " Accumulate took " << secsAccumulate << " seconds, and ToString() took " << secsBuilder << " seconds." << endl
<< " The relative speed improvement was " << ((secsAccumulate / secsBuilder) - 1) * 100 << "%" << endl <<
" Join took " << secsJoin << " seconds."
<< endl;
}
#endif // def __USE_POSIX199309
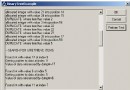
最初,經由過程一個main函數挪用以上完成的兩個函數,將成果顯示在掌握台,然後履行機能測試:一個用於調試設置裝備擺設。
另外一個用於刊行版本:
看到這百分比沒?渣滓郵件的發送量都不克不及到達這個級別!
代碼應用
在應用這段代碼前, 斟酌應用ostring流。正如你鄙人面看到Jeff師長教師評論的一樣,它比這篇文章中的代碼更快些。
你能夠想應用這段代碼,假如:
你正在編寫由具有C#經歷的法式員保護的代碼,而且你想供給一個他們所熟習接口的代碼。
你正在編寫未來會轉換成.net的、你想指出一個能夠途徑的代碼。
因為某些緣由,你不想包括<sstream>。幾年以後,一些流的IO完成變得很繁瑣,並且如今的代碼依然不克不及完整解脫他們的攪擾。
要應用這段代碼,只要依照main函數完成的那樣便可以了:創立一個StringBuilder的實例,用Append()、AppendLine()和Add()給它賦值,然後挪用ToString函數檢索成果。
就像上面如許:
int main() {
////////////////////////////////////
// 8-bit characters (ANSI)
////////////////////////////////////
StringBuilder<char> ansi;
ansi.Append("Hello").Append(" ").AppendLine("World");
std::cout << ansi.ToString();
////////////////////////////////////
// Wide characters (Unicode)
////////////////////////////////////
// http://en.wikipedia.org/wiki/Cargo_cult
std::vector<std::wstring> cargoCult
{
L"A", L" cargo", L" cult", L" is", L" a", L" kind", L" of", L" Melanesian", L" millenarian", L" movement",
// many more lines here...
L" applied", L" retroactively", L" to", L" movements", L" in", L" a", L" much", L" earlier", L" era.\n"
};
StringBuilder<wchar_t> wide;
wide.Add(cargoCult.begin(), cargoCult.end()).AppendLine();
// use ToString(), just like .net
std::wcout << wide.ToString() << std::endl;
// javascript-like join.
std::wcout << wide.Join(L" _\n") << std::endl;
////////////////////////////////////
// Performance tests
////////////////////////////////////
TestPerformance(wide, cargoCult);
#ifdef __USE_POSIX199309
AccurateTestPerformance(wide, cargoCult);
#endif // def __USE_POSIX199309
return 0;
}
任何情形下,當銜接跨越幾個字符串時,小心std::accumulate函數。
如今稍等一下!
你能夠會問:你是在試著壓服我們提早優化嗎?
不是的。我贊成提早優化是蹩腳的。這類優化其實不是提早的:是實時的。這是基於經歷的優化:我發明本身曩昔一向在和這類特別的怪胎格斗。基於經歷的優化(不在統一個處所摔倒兩次)其實不是提早優化。