C++對象模型可以概括為以下2部分:
1. 語言中直接支持面向對象程序設計的部分
2. 對於各種支持的底層實現機制
語言中直接支持面向對象程序設計的部分,如構造函數、析構函數、虛函數、繼承(單繼承、多繼承、虛繼承)、多態等等,這也是組裡其他同學之前分享過的內容。第一部分這裡我簡單過一下,重點在底層實現機制。
在c語言中,“數據”和“處理數據的操作(函數)”是分開來聲明的,也就是說,語言本身並沒有支持“數據和函數”之間的關聯性。在c++中,通過抽象數據類型(abstract data type,ADT),在類中定義數據和函數,來實現數據和函數直接的綁定。
概括來說,在C++類中有兩種成員數據:static、nonstatic;三種成員函數:static、nonstatic、virtual。

如下面的Base類定義:
#pragma once
#include<iostream>
using namespace std;
class Base
{
public:
Base(int);
virtual ~Base(void);
int getIBase() const;
static int instanceCount();
virtual void print() const;
protected:
int iBase;
static int count;
};
Base類在機器中我們如何構建出各種成員數據和成員函數的呢?
在介紹C++使用的對象模型之前,介紹2種對象模型:簡單對象模型(a simple object model)、表格驅動對象模型(a table-driven object model)。
簡單對象模型(a simple object model)

所有的成員占用相同的空間(跟成員類型無關),對象只是維護了一個包含成員指針的一個表。表中放的是成員的地址,無論上成員變量還是函數,都是這樣處理。對象並沒有直接保存成員而是保存了成員的指針。
表格對象模型(a table-driven object model)
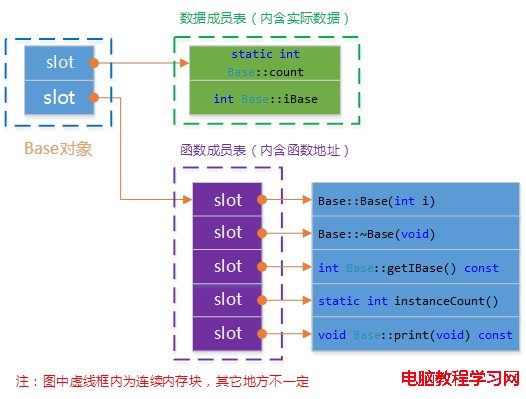
這個模型在簡單對象的基礎上又添加了一個間接層。將成員分成函數和數據,並且用兩個表格保存,然後對象只保存了兩個指向表格的指針。這個模型可以保證所有的對象具有相同的大小,比如簡單對象模型還與成員的個數相關。其中數據成員表中包含實際數據;函數成員表中包含的實際函數的地址(與數據成員相比,多一次尋址)。
C++對象模型
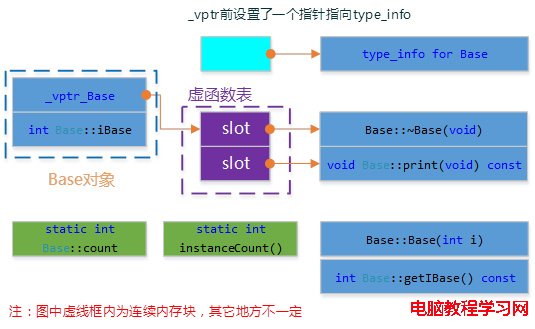
這個模型從結合上面2中模型的特點,並對內存存取和空間進行了優化。在此模型中,non static 數據成員被放置到對象內部,static數據成員, static and nonstatic 函數成員均被放到對象之外。對於虛函數的支持則分兩步完成:
1. 每一個class產生一堆指向虛函數的指針,放在表格之中。這個表格稱之為虛函數表(virtual table,vtbl)。
2. 每一個對象被添加了一個指針,指向相關的虛函數表vtbl。通常這個指針被稱為vptr。vptr的設定(setting)和重置(resetting)都由每一個class的構造函數,析構函數和拷貝賦值運算符自動完成。
另外,虛函數表地址的前面設置了一個指向type_info的指針,RTTI(Run Time Type Identification)運行時類型識別是有編譯器在編譯器生成的特殊類型信息,包括對象繼承關系,對象本身的描述,RTTI是為多態而生成的信息,所以只有具有虛函數的對象在會生成。
這個模型的優點在於它的空間和存取時間的效率;缺點如下:如果應用程序本身未改變,但當所使用的類的non static數據成員添加刪除或修改時,需要重新編譯。
模型驗證測試
為了驗證上述C++對象模型,我們編寫如下測試代碼。
void test_base_model()
{
Base b1(1000);
cout << "對象b1的起始內存地址:" << &b1 << endl;
cout << "type_info信息:" << ((int*)*(int*)(&b1) - 1) << endl;
RTTICompleteObjectLocator str=
*((RTTICompleteObjectLocator*)*((int*)*(int*)(&b1) - 1));
//abstract class name from RTTI
string classname(str.pTypeDescriptor->name);
classname = classname.substr(4,classname.find("@@")-4);
cout << classname <<endl;
cout << "虛函數表地址:\t\t\t" << (int*)(&b1) << endl;
cout << "虛函數表 — 第1個函數地址:\t" << (int*)*(int*)(&b1) << "\t即析構函數地址:" << (int*)*((int*)*(int*)(&b1)) << endl;
cout << "虛函數表 — 第2個函數地址:\t" << ((int*)*(int*)(&b1) + 1) << "\t";
typedef void(*Fun)(void);
Fun pFun = (Fun)*(((int*)*(int*)(&b1)) + 1);
pFun();
b1.print();
cout << endl;
cout << "推測數據成員iBase地址:\t\t" << ((int*)(&b1) +1) << "\t通過地址取值iBase的值:" << *((int*)(&b1) +1) << endl;
cout << "Base::getIBase(): " << b1.getIBase() << endl;
b1.instanceCount();
cout << "靜態函數instanceCount地址: " << b1.instanceCount << endl;
}
根據C++對象模型,實例化對象b1的起始內存地址,即虛函數表地址。
下面是測試代碼輸出:(從下面2個圖驗證了,上面的觀點。)
注意:本測試代碼及後面的測試代碼中寫的函數地址,是對應虛函數表項的地址,不是實際的函數地址。
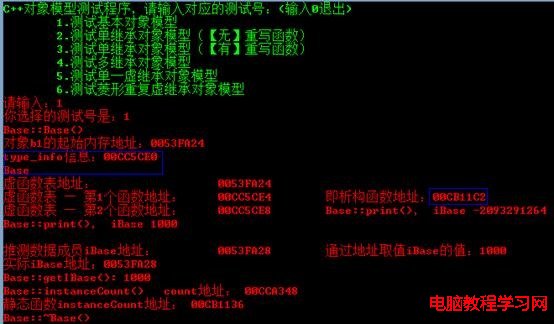
圖:測試代碼輸出結果

圖:vs斷點觀察(注意看虛函數表中第一個函數的地址,名稱與測試代碼輸出一致)
上面介紹並驗證了基本的C++對象模型,引入繼承之後,C++對象模型又是怎樣的?
不管是單繼承、多繼承,還是虛繼承,如果基於“簡單對象模型”,每一個基類都可以被派生類中的一個slot指出,該slot內包含基類對象的地址。這個機制的主要缺點是,因為間接性而導致空間和存取時間上的額外負擔;優點則是派生類對象的大小不會因其基類的改變而受影響。
如果基於“表格驅動模型”,派生類中有一個slot指向基類表,表格中的每一個slot含一個相關的基類地址(這個很像虛函數表,內含每一個虛函數的地址)。這樣每個派生類對象汗一個bptr,它會被初始化,指向其基類表。這種策略的主要缺點是由於間接性而導致的空間和存取時間上的額外負擔;優點則是在每一個派生類對象中對繼承都有一致的表現方式,每一個派生類對象都應該在某個固定位置上放置一個基類表指針,與基類的大小或數量無關。第二個優點是,不需要改變派生類對象本身,就可以放大,縮小、或更改基類表。
不管上述哪一種機制,“間接性”的級數都將因為集成的深度而增加。C++實際模型是,對於一般繼承是擴充已有存在的虛函數表;對於虛繼承添加一個虛函數表指針。
無重寫的單繼承
無重寫,即派生類中沒有於基類同名的虛函數。
#pragma once
#include "base.h"
class Derived :
public Base
{
public:
Derived(int);
virtual ~Derived(void);
virtual void derived_print(void);
protected:
int iDerived;
};
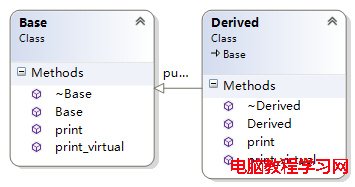
Base、Derived的類圖如下所示:

Base的模型跟上面的一樣,不受繼承的影響。Derived不是虛繼承,所以是擴充已存在的虛函數表,所以結構如下圖所示:
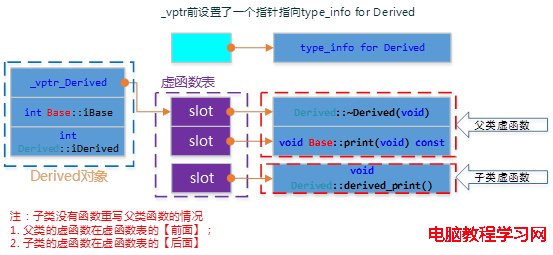
為了驗證上述C++對象模型,我們編寫如下測試代碼。
void test_single_inherit_norewrite()
{
Derived d(9999);
cout << "對象d的起始內存地址:" << &d << endl;
cout << "type_info信息:" << ((int*)*(int*)(&d) - 1) << endl;
RTTICompleteObjectLocator str=
*((RTTICompleteObjectLocator*)*((int*)*(int*)(&d) - 1));
//abstract class name from RTTI
string classname(str.pTypeDescriptor->name);
classname = classname.substr(4,classname.find("@@")-4);
cout << classname <<endl;
cout << "虛函數表地址:\t\t\t" << (int*)(&d) << endl;
cout << "虛函數表 — 第1個函數地址:\t" << (int*)*(int*)(&d) << "\t即析構函數地址" << endl;
cout << "虛函數表 — 第2個函數地址:\t" << ((int*)*(int*)(&d) + 1) << "\t";
typedef void(*Fun)(void);
Fun pFun = (Fun)*(((int*)*(int*)(&d)) + 1);
pFun();
d.print();
cout << endl;
cout << "虛函數表 — 第3個函數地址:\t" << ((int*)*(int*)(&d) + 2) << "\t";
pFun = (Fun)*(((int*)*(int*)(&d)) + 2);
pFun();
d.derived_print();
cout << endl;
cout << "推測數據成員iBase地址:\t\t" << ((int*)(&d) +1) << "\t通過地址取得的值:" << *((int*)(&d) +1) << endl;
cout << "推測數據成員iDerived地址:\t" << ((int*)(&d) +2) << "\t通過地址取得的值:" << *((int*)(&d) +2) << endl;
}
輸出結果如下圖所示:
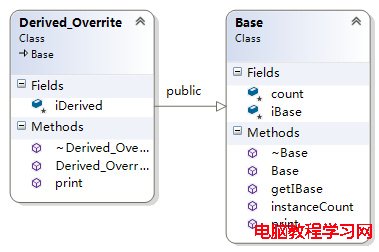
有重寫的單繼承
派生類中重寫了基類的print()函數。
#pragma once
#include "base.h"
class Derived_Overrite :
public Base
{
public:
Derived_Overrite(int);
virtual ~Derived_Overrite(void);
virtual void print(void) const;
protected:
int iDerived;
};
Base、Derived_Overwrite的類圖如下所示:
重寫print()函數在虛函數表中表現如下:
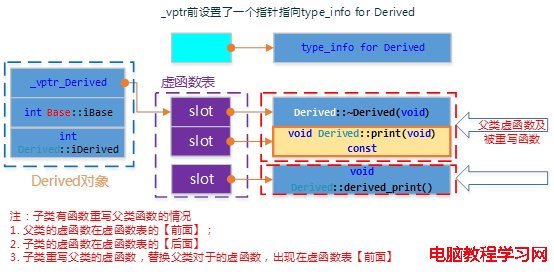
為了驗證上述C++對象模型,我們編寫如下測試代碼。
void test_single_inherit_rewrite()
{
Derived_Overrite d(111111);
cout << "對象d的起始內存地址:\t\t" << &d << endl;
cout << "虛函數表地址:\t\t\t" << (int*)(&d) << endl;
cout << "虛函數表 — 第1個函數地址:\t" << (int*)*(int*)(&d) << "\t即析構函數地址" << endl;
cout << "虛函數表 — 第2個函數地址:\t" << ((int*)*(int*)(&d) + 1) << "\t";
typedef void(*Fun)(void);
Fun pFun = (Fun)*(((int*)*(int*)(&d)) + 1);
pFun();
d.print();
cout << endl;
cout << "虛函數表 — 第3個函數地址:\t" << *((int*)*(int*)(&d) + 2) << "【結束】\t";
cout << endl;
cout << "推測數據成員iBase地址:\t\t" << ((int*)(&d) +1) << "\t通過地址取得的值:" << *((int*)(&d) +1) << endl;
cout << "推測數據成員iDerived地址:\t" << ((int*)(&d) +2) << "\t通過地址取得的值:" << *((int*)(&d) +2) << endl;
}
輸出結果如下圖所示:
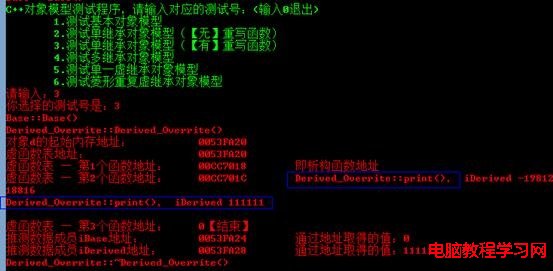
特別注意下,前面的模型虛函數表中最後一項沒有打印出來,本實例中共2個虛函數,打印虛函數表第3項為0。其實虛函數表以0×0000000結束,類似字符串以’’結束。
從單繼承可以知道,派生類中只是擴充了基類的虛函數表。如果是多繼承的話,又是如何擴充的?
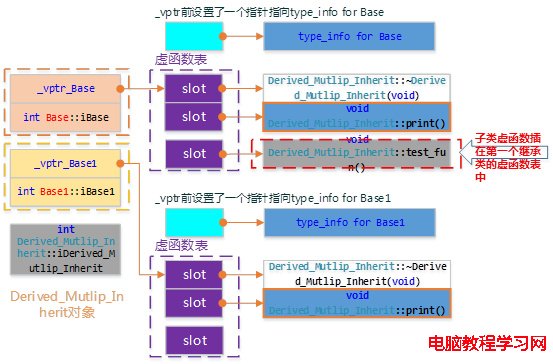
1) 每個基類都有自己的虛表。
2) 子類的成員函數被放到了第一個基類的表中。
3) 內存布局中,其父類布局依次按聲明順序排列。
4) 每個基類的虛表中的print()函數都被overwrite成了子類的print ()。這樣做就是為了解決不同的基類類型的指針指向同一個子類實例,而能夠調用到實際的函數。
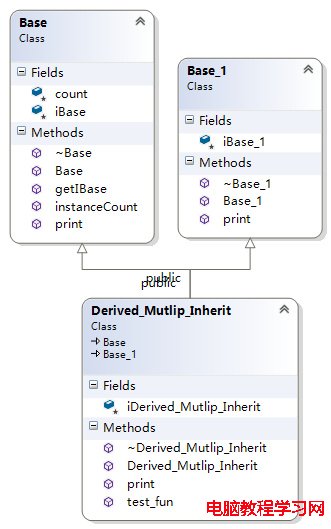
上面3個類,Derived_Mutlip_Inherit繼承自Base、Base_1兩個類,Derived_Mutlip_Inherit的結構如下所示:
為了驗證上述C++對象模型,我們編寫如下測試代碼。
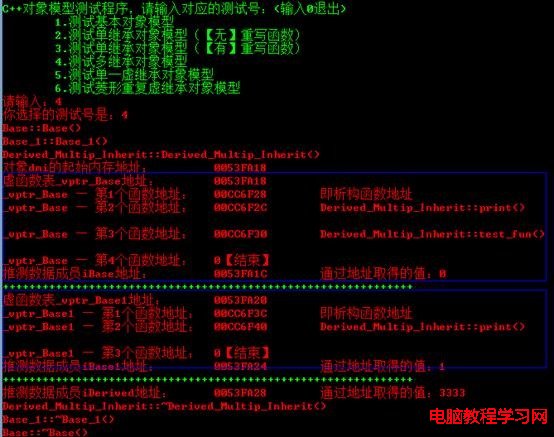
void test_multip_inherit()
{
Derived_Mutlip_Inherit dmi(3333);
cout << "對象dmi的起始內存地址:\t\t" << &dmi << endl;
cout << "虛函數表_vptr_Base地址:\t" << (int*)(&dmi) << endl;
cout << "_vptr_Base — 第1個函數地址:\t" << (int*)*(int*)(&dmi) << "\t即析構函數地址" << endl;
cout << "_vptr_Base — 第2個函數地址:\t" << ((int*)*(int*)(&dmi) + 1) << "\t";
typedef void(*Fun)(void);
Fun pFun = (Fun)*(((int*)*(int*)(&dmi)) + 1);
pFun();
cout << endl;
cout << "_vptr_Base — 第3個函數地址:\t" << ((int*)*(int*)(&dmi) + 2) << "\t";
pFun = (Fun)*(((int*)*(int*)(&dmi)) + 2);
pFun();
cout << endl;
cout << "_vptr_Base — 第4個函數地址:\t" << *((int*)*(int*)(&dmi) + 3) << "【結束】\t";
cout << endl;
cout << "推測數據成員iBase地址:\t\t" << ((int*)(&dmi) +1) << "\t通過地址取得的值:" << *((int*)(&dmi) +1) << endl;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY | FOREGROUND_GREEN);
cout << "++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++" << endl;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY | FOREGROUND_RED);
cout << "虛函數表_vptr_Base1地址:\t" << ((int*)(&dmi) +2) << endl;
cout << "_vptr_Base1 — 第1個函數地址:\t" << (int*)*((int*)(&dmi) +2) << "\t即析構函數地址" << endl;
cout << "_vptr_Base1 — 第2個函數地址:\t" << ((int*)*((int*)(&dmi) +2) + 1) << "\t";
typedef void(*Fun)(void);
pFun = (Fun)*((int*)*((int*)(&dmi) +2) + 1);
pFun();
cout << endl;
cout << "_vptr_Base1 — 第3個函數地址:\t" << *((int*)*(int*)((int*)(&dmi) +2) + 2) << "【結束】\t";
cout << endl;
cout << "推測數據成員iBase1地址:\t" << ((int*)(&dmi) +3) << "\t通過地址取得的值:" << *((int*)(&dmi) +3) << endl;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY | FOREGROUND_GREEN);
cout << "++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++" << endl;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY | FOREGROUND_RED);
cout << "推測數據成員iDerived地址:\t" << ((int*)(&dmi) +4) << "\t通過地址取得的值:" << *((int*)(&dmi) +4) << endl;
}
輸出結果如下圖所示:
虛繼承是為了解決重復繼承中多個間接父類的問題的,所以不能使用上面簡單的擴充並為每個虛基類提供一個虛函數指針(這樣會導致重復繼承的基類會有多個虛函數表)形式。
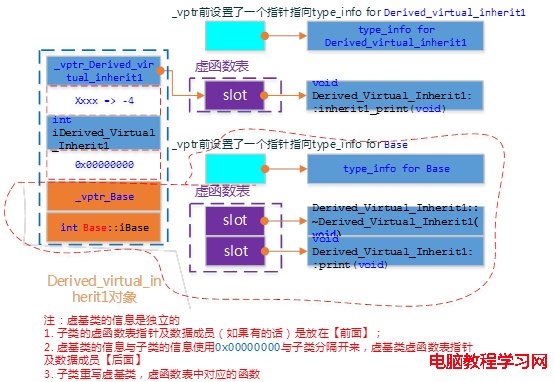
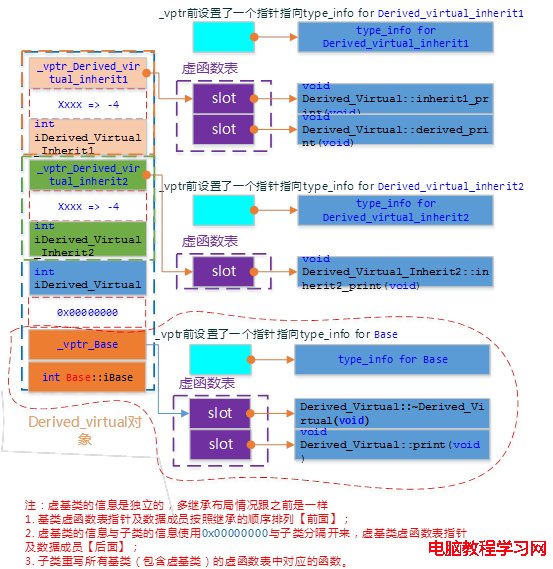
虛繼承的派生類的內存結構,和普通繼承完全不同。虛繼承的子類,有單獨的虛函數表,另外也單獨保存一份父類的虛函數表,兩部分之間用一個四個字節的0×00000000來作為分界。派生類的內存中,首先是自己的虛函數表,然後是派生類的數據成員,然後是0×0,之後就是基類的虛函數表,之後是基類的數據成員。
如果派生類沒有自己的虛函數,那麼派生類就不會有虛函數表,但是派生類數據和基類數據之間,還是需要0×0來間隔。
因此,在虛繼承中,派生類和基類的數據,是完全間隔的,先存放派生類自己的虛函數表和數據,中間以0x分界,最後保存基類的虛函數和數據。如果派生類重載了父類的虛函數,那麼則將派生類內存中基類虛函數表的相應函數替換。
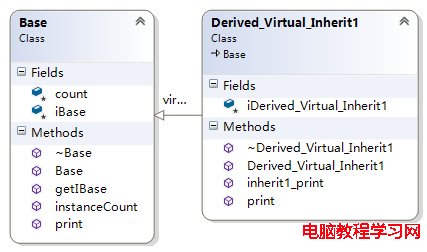
簡單虛繼承(無重復繼承情況)
簡單虛繼承的2個類Base、Derived_Virtual_Inherit1的關系如下所示:
Derived_Virtual_Inherit1的對象模型如下圖:
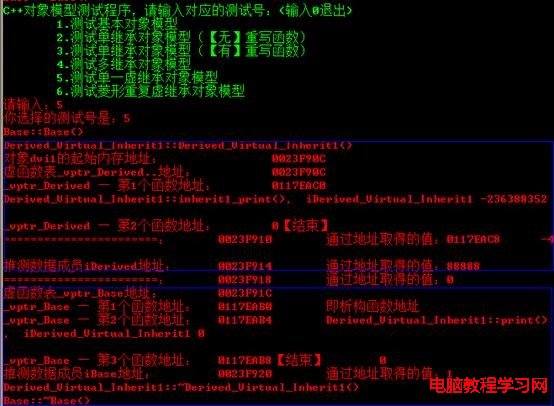
為了驗證上述C++對象模型,我們編寫如下測試代碼。
void test_single_vitrual_inherit()
{
Derived_Virtual_Inherit1 dvi1(88888);
cout << "對象dvi1的起始內存地址:\t\t" << &dvi1 << endl;
cout << "虛函數表_vptr_Derived..地址:\t\t" << (int*)(&dvi1) << endl;
cout << "_vptr_Derived — 第1個函數地址:\t" << (int*)*(int*)(&dvi1) << endl;
typedef void(*Fun)(void);
Fun pFun = (Fun)*((int*)*(int*)(&dvi1));
pFun();
cout << endl;
cout << "_vptr_Derived — 第2個函數地址:\t" << *((int*)*(int*)(&dvi1) + 1) << "【結束】\t";
cout << endl;
cout << "=======================:\t" << ((int*)(&dvi1) +1) << "\t通過地址取得的值:" << (int*)*((int*)(&dvi1) +1) << "\t" <<*(int*)*((int*)(&dvi1) +1) << endl;
cout << "推測數據成員iDerived地址:\t" << ((int*)(&dvi1) +2) << "\t通過地址取得的值:" << *((int*)(&dvi1) +2) << endl;
cout << "=======================:\t" << ((int*)(&dvi1) +3) << "\t通過地址取得的值:" << *((int*)(&dvi1) +3) << endl;
cout << "虛函數表_vptr_Base地址:\t" << ((int*)(&dvi1) +4) << endl;
cout << "_vptr_Base — 第1個函數地址:\t" << (int*)*((int*)(&dvi1) +4) << "\t即析構函數地址" << endl;
cout << "_vptr_Base — 第2個函數地址:\t" << ((int*)*((int*)(&dvi1) +4) +1) << "\t";
pFun = (Fun)*((int*)*((int*)(&dvi1) +4) +1);
pFun();
cout << endl;
cout << "_vptr_Base — 第3個函數地址:\t" << ((int*)*((int*)(&dvi1) +4) +2) << "【結束】\t" << *((int*)*((int*)(&dvi1) +4) +2);
cout << endl;
cout << "推測數據成員iBase地址:\t\t" << ((int*)(&dvi1) +5) << "\t通過地址取得的值:" << *((int*)(&dvi1) +5) << endl;
}
輸出結果如下圖所示:
菱形繼承(含重復繼承、多繼承情況)
菱形繼承關系如下圖:
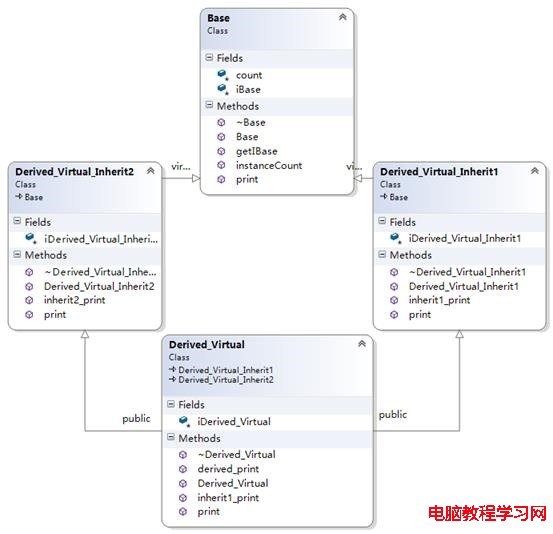
Derived_Virtual的對象模型如下圖:
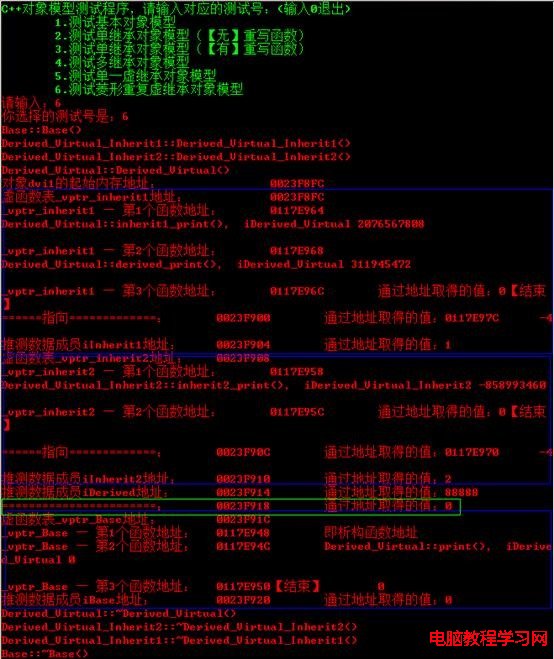
為了驗證上述C++對象模型,我們編寫如下測試代碼。
void test_multip_vitrual_inherit()
{
Derived_Virtual dvi1(88888);
cout << "對象dvi1的起始內存地址:\t\t" << &dvi1 << endl;
cout << "虛函數表_vptr_inherit1地址:\t\t" << (int*)(&dvi1) << endl;
cout << "_vptr_inherit1 — 第1個函數地址:\t" << (int*)*(int*)(&dvi1) << endl;
typedef void(*Fun)(void);
Fun pFun = (Fun)*((int*)*(int*)(&dvi1));
pFun();
cout << endl;
cout << "_vptr_inherit1 — 第2個函數地址:\t" << ((int*)*(int*)(&dvi1) + 1) << endl;
pFun = (Fun)*((int*)*(int*)(&dvi1) + 1);
pFun();
cout << endl;
cout << "_vptr_inherit1 — 第3個函數地址:\t" << ((int*)*(int*)(&dvi1) + 2) << "\t通過地址取得的值:" << *((int*)*(int*)(&dvi1) + 2) << "【結束】\t";
cout << endl;
cout << "======指向=============:\t" << ((int*)(&dvi1) +1) << "\t通過地址取得的值:" << (int*)*((int*)(&dvi1) +1)<< "\t" <<*(int*)*((int*)(&dvi1) +1) << endl;
cout << "推測數據成員iInherit1地址:\t" << ((int*)(&dvi1) +2) << "\t通過地址取得的值:" << *((int*)(&dvi1) +2) << endl;
//
cout << "虛函數表_vptr_inherit2地址:\t" << ((int*)(&dvi1) +3) << endl;
cout << "_vptr_inherit2 — 第1個函數地址:\t" << (int*)*((int*)(&dvi1) +3) << endl;
pFun = (Fun)*((int*)*((int*)(&dvi1) +3));
pFun();
cout << endl;
cout << "_vptr_inherit2 — 第2個函數地址:\t" << (int*)*((int*)(&dvi1) +3) + 1 <<"\t通過地址取得的值:" << *((int*)*((int*)(&dvi1) +3) + 1) << "【結束】\t" << endl;
cout << endl;
cout << "======指向=============:\t" << ((int*)(&dvi1) +4) << "\t通過地址取得的值:" << (int*)*((int*)(&dvi1) +4) << "\t" <<*(int*)*((int*)(&dvi1) +4)<< endl;
cout << "推測數據成員iInherit2地址:\t" << ((int*)(&dvi1) +5) << "\t通過地址取得的值:" << *((int*)(&dvi1) +5) << endl;
cout << "推測數據成員iDerived地址:\t" << ((int*)(&dvi1) +6) << "\t通過地址取得的值:" << *((int*)(&dvi1) +6) << endl;
cout << "=======================:\t" << ((int*)(&dvi1) +7) << "\t通過地址取得的值:" << *((int*)(&dvi1) +7) << endl;
//
cout << "虛函數表_vptr_Base地址:\t" << ((int*)(&dvi1) +8) << endl;
cout << "_vptr_Base — 第1個函數地址:\t" << (int*)*((int*)(&dvi1) +8) << "\t即析構函數地址" << endl;
cout << "_vptr_Base — 第2個函數地址:\t" << ((int*)*((int*)(&dvi1) +8) +1) << "\t";
pFun = (Fun)*((int*)*((int*)(&dvi1) +8) +1);
pFun();
cout << endl;
cout << "_vptr_Base — 第3個函數地址:\t" << ((int*)*((int*)(&dvi1) +8) +2) << "【結束】\t" << *((int*)*((int*)(&dvi1) +8) +2);
cout << endl;
cout << "推測數據成員iBase地址:\t\t" << ((int*)(&dvi1) +9) << "\t通過地址取得的值:" << *((int*)(&dvi1) +9) << endl;
}
輸出結果如下圖所示:
至此,C++對象模型介紹的差不多了,清楚了C++對象模型之後,很多疑問就能迎刃而解了。下面結合模型介紹一些典型問題。
前面介紹了C++對象模型,下面介紹C++對象模型的對訪問成員的影響。其實清楚了C++對象模型,就清楚了成員訪問機制。下面分別針對數據成員和函數成員是如何訪問到的,給出一個大致介紹。
對象大小問題
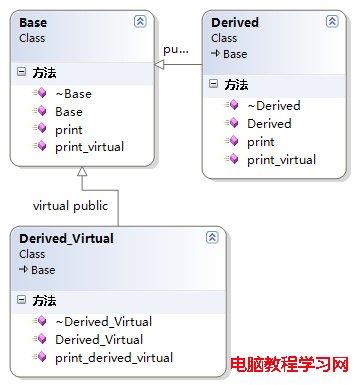
其中:3個類中的函數都是虛函數
void test_size()
{
Base b;
Derived d;
Derived_Virtual dv;
cout << "sizeof(b):\t" << sizeof(b) << endl;
cout << "sizeof(d):\t" << sizeof(d) << endl;
cout << "sizeof(dv):\t" << sizeof(dv) << endl;
}
輸出如下:
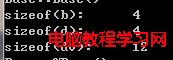
因為Base中包含虛函數表指針,所有size為4;Derived繼承Base,只是擴充基類的虛函數表,不會新增虛函數表指針,所以size也是4;Derived_Virtual虛繼承Base,根據前面的模型知道,派生類有自己的虛函數表及指針,並且有分隔符(0×00000000),然後才是虛基類的虛函數表等信息,故大小為4+4+4=12。
#pragma once
class Empty
{
public:
Empty(void);
~Empty(void);
};
Empty p,sizeof(p)的大小是多少?事實上並不是空的,它有一個隱晦的1byte,那是被編譯器安插進去的一個char。這將使得這個class的兩個對象得以在內中有獨一無二的地址。
數據成員如何訪問(直接取址)
跟實際對象模型相關聯,根據對象起始地址+偏移量取得。
靜態綁定與動態綁定
程序調用函數時,將使用那個可執行代碼塊呢?編譯器負責回答這個問題。將源代碼中的函數調用解析為執行特定的函數代碼塊被稱為函數名綁定(binding,又稱聯編)。在C語言中,這非常簡單,因為每個函數名都對應一個不同的額函數。在C++中,由於函數重載的緣故,這項任務更復雜。編譯器必須查看函數參數以及函數名才能確定使用哪個函數。然而編譯器可以再編譯過程中完成這種綁定,這稱為靜態綁定(static binding),又稱為早期綁定(early binding)。
然而虛函數是這項工作變得更加困難。使用哪一個函數不是能在編譯階段時確定的,因為編譯器不知道用戶將選擇哪種類型。所以,編譯器必須能夠在程序運行時選擇正確的虛函數的代碼,這被稱為動態綁定(dynamic binding),又稱為晚期綁定(late binding)。
使用虛函數是有代價的,在內存和執行速度方面是有一定成本的,包括:
雖然非虛函數比虛函數效率稍高,單不具備動態聯編能力。
函數成員如何訪問(間接取址)
跟實際對象模型相關聯,普通函數(nonstatic、static)根據編譯、鏈接的結果直接獲取函數地址;如果是虛函數根據對象模型,取出對於虛函數地址,然後在虛函數表中查找函數地址。
多態的實現
多態(Polymorphisn)在C++中是通過虛函數實現的。通過前面的模型【參見“有重寫的單繼承”】知道,如果類中有虛函數,編譯器就會自動生成一個虛函數表,對象中包含一個指向虛函數表的指針。能夠實現多態的關鍵在於:虛函數是允許被派生類重寫的,在虛函數表中,派生類函數對覆蓋(override)基類函數。除此之外,還必須通過指針或引用調用方法才行,將派生類對象賦給基類對象。
上面2個類,基類Base、派生類Derived中都包含下面2個方法:
這個2個方法的區別就在於一個是普通成員函數,一個是虛函數。編寫測試代碼如下:
void test_polmorphisn()
{
Base b;
Derived d;
b = d;
b.print();
b.print_virtual();
Base *p;
p = &d;
p->print();
p->print_virtual();
}
根據模型推測只有p->print_virtual()才實現了動態,其他3調用都是調用基類的方法。原因如下:
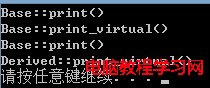
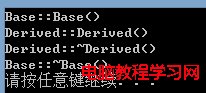
為什麼析構函數設為虛函數是必要的
析構函數應當都是虛函數,除非明確該類不做基類(不被其他類繼承)。基類的析構函數聲明為虛函數,這樣做是為了確保釋放派生對象時,按照正確的順序調用析構函數。
從前面介紹的C++對象模型可以知道,如果析構函數不定義為虛函數,那麼派生類就不會重寫基類的析構函數,在有多態行為的時候,派生類的析構函數不會被調用到(有內存洩漏的風險!)。
例如,通過new一個派生類對象,賦給基類指針,然後delete基類指針。
void test_vitual_destructor()
{
Base *p = new Derived();
delete p;
}
如果基類的析構函數不是析構函數:
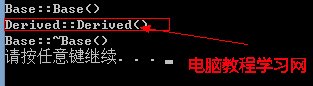
注意,缺少了派生類的析構函數調用。把析構函數聲明為虛函數,調用就正常了: