這篇文章成為了打開C++對象模型內存布局的一個引子,引發了大家對C++對象的更深層次的討論。當然,我之前的文章還有很多方面沒有涉及,從我個人感覺下來,在談論虛函數表裡,至少有以下這些內容沒有涉及:
1)有成員變量的情況。
2)有重復繼承的情況。
3)有虛擬繼承的情況。
4)有鑽石型虛擬繼承的情況。
這些都是我本篇文章需要向大家說明的東西。所以,這篇文章將會是《C++虛函數表解析》的一個續篇,也是一篇高級進階的文章。我希望大家在讀這篇文章之前對C++有一定的基礎和了解,並能先讀我的上一篇文章。因為這篇文章的深度可能會比較深,而且會比較雜亂,我希望你在讀本篇文章時不會有大腦思維紊亂導致大腦死機的情況。;-)
簡而言之,我們一個類可能會有如下的影響因素:
1)成員變量
2)虛函數(產生虛函數表)
3)單一繼承(只繼承於一個類)
4)多重繼承(繼承多個類)
5)重復繼承(繼承的多個父類中其父類有相同的超類)
6)虛擬繼承(使用virtual方式繼承,為了保證繼承後父類的內存布局只會存在一份)
上述的東西通常是C++這門語言在語義方面對對象內部的影響因素,當然,還會有編譯器的影響(比如優化),還有字節對齊的影響。在這裡我們都不討論,我們只討論C++語言上的影響。
本篇文章著重討論下述幾個情況下的C++對象的內存布局情況。
1)單一的一般繼承(帶成員變量、虛函數、虛函數覆蓋)
2)單一的虛擬繼承(帶成員變量、虛函數、虛函數覆蓋)
3)多重繼承(帶成員變量、虛函數、虛函數覆蓋)
4)重復多重繼承(帶成員變量、虛函數、虛函數覆蓋)
5)鑽石型的虛擬多重繼承(帶成員變量、虛函數、虛函數覆蓋)
我們的目標就是,讓事情越來越復雜。
我們簡單地復習一下,我們可以通過對象的地址來取得虛函數表的地址,如:
typedef void(*Fun)(void); Base b; Fun pFun = NULL; cout << "虛函數表地址:" << (int*)(&b) << endl; cout << "虛函數表 — 第一個函數地址:" << (int*)*(int*)(&b) << endl; // Invoke the first virtual function pFun = (Fun)*((int*)*(int*)(&b)); pFun();
我們同樣可以用這種方式來取得整個對象實例的內存布局。因為這些東西在內存中都是連續分布的,我們只需要使用適當的地址偏移量,我們就可以獲得整個內存對象的布局。
本篇文章中的例程或內存布局主要使用如下編譯器和系統:
1)Windows XP 和 VC++ 2003
2)Cygwin 和 G++ 3.4.4
下面,我們假設有如下所示的一個繼承關系:
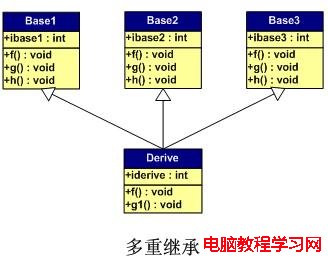
請注意,在這個繼承關系中,父類,子類,孫子類都有自己的一個成員變量。而了類覆蓋了父類的f()方法,孫子類覆蓋了子類的g_child()及其超類的f()。
我們的源程序如下所示:
class Parent {
public:
int iparent;
Parent ():iparent (10) {}
virtual void f() { cout << " Parent::f()" << endl; }
virtual void g() { cout << " Parent::g()" << endl; }
virtual void h() { cout << " Parent::h()" << endl; }
};
class Child : public Parent {
public:
int ichild;
Child():ichild(100) {}
virtual void f() { cout << "Child::f()" << endl; }
virtual void g_child() { cout << "Child::g_child()" << endl; }
virtual void h_child() { cout << "Child::h_child()" << endl; }
};
class GrandChild : public Child{
public:
int igrandchild;
GrandChild():igrandchild(1000) {}
virtual void f() { cout << "GrandChild::f()" << endl; }
virtual void g_child() { cout << "GrandChild::g_child()" << endl; }
virtual void h_grandchild() { cout << "GrandChild::h_grandchild()" << endl; }
};
我們使用以下程序作為測試程序:(下面程序中,我使用了一個int** pVtab 來作為遍歷對象內存布局的指針,這樣,我就可以方便地像使用數組一樣來遍歷所有的成員包括其虛函數表了,在後面的程序中,我也是用這樣的方法的,請不必感到奇怪,)
typedef void(*Fun)(void);
GrandChild gc;
int** pVtab = (int**)&gc;
cout << "[0] GrandChild::_vptr->" << endl;
for (int i=0; (Fun)pVtab[0][i]!=NULL; i++){
pFun = (Fun)pVtab[0][i];
cout << " ["<<i<<"] ";
pFun();
}
cout << "[1] Parent.iparent = " << (int)pVtab[1] << endl;
cout << "[2] Child.ichild = " << (int)pVtab[2] << endl;
cout << "[3] GrandChild.igrandchild = " << (int)pVtab[3] << endl;
其運行結果如下所示:(在VC++ 2003和G++ 3.4.4下)
[0] GrandChild::_vptr->
<pre> [0] GrandChild::f()
[1] Parent::g()
[2] Parent::h()
[3] GrandChild::g_child()
[4] Child::h1()
[5] GrandChild::h_grandchild()
[1] Parent.iparent = 10
[2] Child.ichild = 100
[3] GrandChild.igrandchild = 1000
使用圖片表示如下:
可見以下幾個方面:
1)虛函數表在最前面的位置。
2)成員變量根據其繼承和聲明順序依次放在後面。
3)在單一的繼承中,被overwrite的虛函數在虛函數表中得到了更新。
下面,再讓我們來看看多重繼承中的情況,假設有下面這樣一個類的繼承關系。注意:子類只overwrite了父類的f()函數,而還有一個是自己的函數(我們這樣做的目的是為了用g1()作為一個標記來標明子類的虛函數表)。而且每個類中都有一個自己的成員變量:
我們的類繼承的源代碼如下所示:父類的成員初始為10,20,30,子類的為100
class Base1 {
public:
int ibase1;
Base1():ibase1(10) {}
virtual void f() { cout << "Base1::f()" << endl; }
virtual void g() { cout << "Base1::g()" << endl; }
virtual void h() { cout << "Base1::h()" << endl; }
};
class Base2 {
public:
int ibase2;
Base2():ibase2(20) {}
virtual void f() { cout << "Base2::f()" << endl; }
virtual void g() { cout << "Base2::g()" << endl; }
virtual void h() { cout << "Base2::h()" << endl; }
};
class Base3 {
public:
int ibase3;
Base3():ibase3(30) {}
virtual void f() { cout << "Base3::f()" << endl; }
virtual void g() { cout << "Base3::g()" << endl; }
virtual void h() { cout << "Base3::h()" << endl; }
};
class Derive : public Base1, public Base2, public Base3 {
public:
int iderive;
Derive():iderive(100) {}
virtual void f() { cout << "Derive::f()" << endl; }
virtual void g1() { cout << "Derive::g1()" << endl; }
};
我們通過下面的程序來查看子類實例的內存布局:下面程序中,注意我使用了一個s變量,其中用到了sizof(Base)來找下一個類的偏移量。(因為我聲明的是int成員,所以是4個字節,所以沒有對齊問題。關於內存的對齊問題,大家可以自行試驗,我在這裡就不多說了)
typedef void(*Fun)(void); Derive d; int** pVtab = (int**)&d; cout << "[0] Base1::_vptr->" << endl; pFun = (Fun)pVtab[0][0]; cout << " [0] "; pFun(); pFun = (Fun)pVtab[0][1]; cout << " [1] ";pFun(); pFun = (Fun)pVtab[0][2]; cout << " [2] ";pFun(); pFun = (Fun)pVtab[0][3]; cout << " [3] "; pFun(); pFun = (Fun)pVtab[0][4]; cout << " [4] "; cout<<pFun<<endl; cout << "[1] Base1.ibase1 = " << (int)pVtab[1] << endl; int s = sizeof(Base1)/4; cout << "[" << s << "] Base2::_vptr->"<<endl; pFun = (Fun)pVtab[s][0]; cout << " [0] "; pFun(); Fun = (Fun)pVtab[s][1]; cout << " [1] "; pFun(); pFun = (Fun)pVtab[s][2]; cout << " [2] "; pFun(); pFun = (Fun)pVtab[s][3]; out << " [3] "; cout<<pFun<<endl; cout << "["<< s+1 <<"] Base2.ibase2 = " << (int)pVtab[s+1] << endl; s = s + sizeof(Base2)/4; cout << "[" << s << "] Base3::_vptr->"<<endl; pFun = (Fun)pVtab[s][0]; cout << " [0] "; pFun(); pFun = (Fun)pVtab[s][1]; cout << " [1] "; pFun(); pFun = (Fun)pVtab[s][2]; cout << " [2] "; pFun(); pFun = (Fun)pVtab[s][3]; cout << " [3] "; cout<<pFun<<endl; s++; cout << "["<< s <<"] Base3.ibase3 = " << (int)pVtab[s] << endl; s++; cout << "["<< s <<"] Derive.iderive = " << (int)pVtab[s] << endl;
其運行結果如下所示:(在VC++ 2003和G++ 3.4.4下)
[0] Base1::_vptr->
[0] Derive::f()
[1] Base1::g()
[2] Base1::h()
[3] Driver::g1()
[4] 00000000 <== 注意:在GCC下,這裡是1
[1] Base1.ibase1 = 10
[2] Base2::_vptr->
[0] Derive::f()
[1] Base2::g()
[2] Base2::h()
[3] 00000000 <== 注意:在GCC下,這裡是1
[3] Base2.ibase2 = 20
[4] Base3::_vptr->
[0] Derive::f()
[1] Base3::g()
[2] Base3::h()
[3] 00000000
[5] Base3.ibase3 = 30
[6] Derive.iderive = 100
使用圖片表示是下面這個樣子:
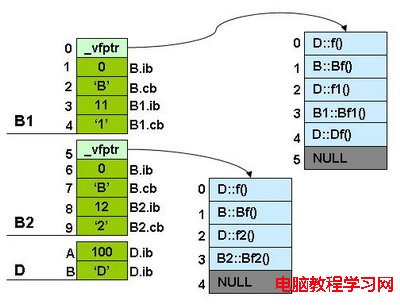
我們可以看到:
1) 每個父類都有自己的虛表。
2) 子類的成員函數被放到了第一個父類的表中。
3) 內存布局中,其父類布局依次按聲明順序排列。
4) 每個父類的虛表中的f()函數都被overwrite成了子類的f()。這樣做就是為了解決不同的父類類型的指針指向同一個子類實例,而能夠調用到實際的函數。
下面我們再來看看,發生重復繼承的情況。所謂重復繼承,也就是某個基類被間接地重復繼承了多次。
下圖是一個繼承圖,我們重載了父類的f()函數。
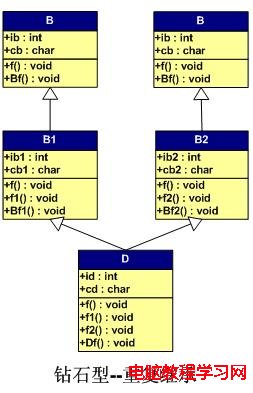
其類繼承的源代碼如下所示。其中,每個類都有兩個變量,一個是整形(4字節),一個是字符(1字節),而且還有自己的虛函數,自己overwrite父類的虛函數。如子類D中,f()覆蓋了超類的函數, f1() 和f2() 覆蓋了其父類的虛函數,Df()為自己的虛函數。
class B
{
public:
int ib;
char cb;
public:
B():ib(0),cb('B') {}
virtual void f() { cout << "B::f()" << endl;}
virtual void Bf() { cout << "B::Bf()" << endl;}
};
class B1 : public B
{
public:
int ib1;
char cb1;
public:
B1():ib1(11),cb1('1') {}
virtual void f() { cout << "B1::f()" << endl;}
virtual void f1() { cout << "B1::f1()" << endl;}
virtual void Bf1() { cout << "B1::Bf1()" << endl;}
};
class B2: public B
{
public:
int ib2;
char cb2;
public:
B2():ib2(12),cb2('2') {}
virtual void f() { cout << "B2::f()" << endl;}
virtual void f2() { cout << "B2::f2()" << endl;}
virtual void Bf2() { cout << "B2::Bf2()" << endl;}
};
class D : public B1, public B2
{
public:
int id;
char cd;
public:
D():id(100),cd('D') {}
virtual void f() { cout << "D::f()" << endl;}
virtual void f1() { cout << "D::f1()" << endl;}
virtual void f2() { cout << "D::f2()" << endl;}
virtual void Df() { cout << "D::Df()" << endl;}
};
我們用來存取子類內存布局的代碼如下所示:(在VC++ 2003和G++ 3.4.4下)
typedef void(*Fun)(void); int** pVtab = NULL; Fun pFun = NULL; D d; pVtab = (int**)&d; cout << "[0] D::B1::_vptr->" << endl; pFun = (Fun)pVtab[0][0]; cout << " [0] "; pFun(); pFun = (Fun)pVtab[0][1]; cout << " [1] "; pFun(); pFun = (Fun)pVtab[0][2]; cout << " [2] "; pFun(); pFun = (Fun)pVtab[0][3]; cout << " [3] "; pFun(); pFun = (Fun)pVtab[0][4]; cout << " [4] "; pFun(); pFun = (Fun)pVtab[0][5]; cout << " [5] 0x" << pFun << endl; cout << "[1] B::ib = " << (int)pVtab[1] << endl; cout << "[2] B::cb = " << (char)pVtab[2] << endl; cout << "[3] B1::ib1 = " << (int)pVtab[3] << endl; cout << "[4] B1::cb1 = " << (char)pVtab[4] << endl; cout << "[5] D::B2::_vptr->" << endl; pFun = (Fun)pVtab[5][0]; cout << " [0] "; pFun(); pFun = (Fun)pVtab[5][1]; cout << " [1] "; pFun(); pFun = (Fun)pVtab[5][2]; cout << " [2] "; pFun(); pFun = (Fun)pVtab[5][3]; cout << " [3] "; pFun(); pFun = (Fun)pVtab[5][4]; cout << " [4] 0x" << pFun << endl; cout << "[6] B::ib = " << (int)pVtab[6] << endl; cout << "[7] B::cb = " << (char)pVtab[7] << endl; cout << "[8] B2::ib2 = " << (int)pVtab[8] << endl; cout << "[9] B2::cb2 = " << (char)pVtab[9] << endl; cout << "[10] D::id = " << (int)pVtab[10] << endl; cout << "[11] D::cd = " << (char)pVtab[11] << endl;
程序運行結果如下:
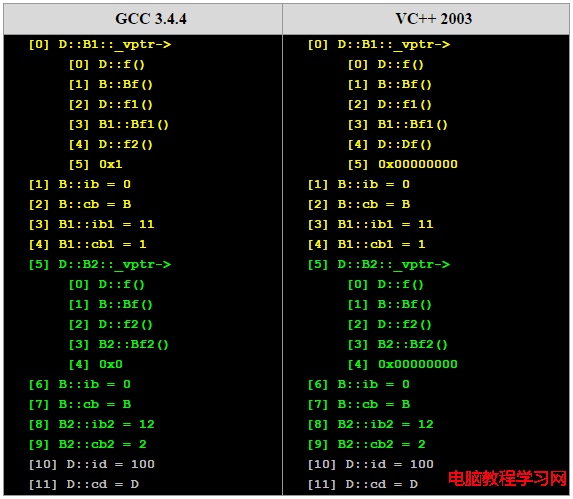
下面是對於子類實例中的虛函數表的圖:
我們可以看見,最頂端的父類B其成員變量存在於B1和B2中,並被D給繼承下去了。而在D中,其有B1和B2的實例,於是B的成員在D的實例中存在兩份,一份是B1繼承而來的,另一份是B2繼承而來的。所以,如果我們使用以下語句,則會產生二義性編譯錯誤:
D d;
d.ib = 0; //二義性錯誤
d.B1::ib = 1; //正確
d.B2::ib = 2; //正確
注意,上面例程中的最後兩條語句存取的是兩個變量。雖然我們消除了二義性的編譯錯誤,但B類在D中還是有兩個實例,這種繼承造成了數據的重復,我們叫這種繼承為重復繼承。重復的基類數據成員可能並不是我們想要的。所以,C++引入了虛基類的概念。
虛擬繼承的出現就是為了解決重復繼承中多個間接父類的問題的。鑽石型的結構是其最經典的結構。也是我們在這裡要討論的結構:
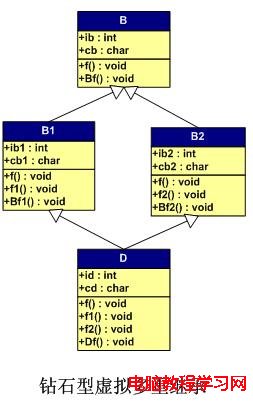
上述的“重復繼承”只需要把B1和B2繼承B的語法中加上virtual 關鍵,就成了虛擬繼承,其繼承圖如下所示:
上圖和前面的“重復繼承”中的類的內部數據和接口都是完全一樣的,只是我們采用了虛擬繼承:其省略後的源碼如下所示:
class B {……};
class B1 : virtual public B{……};
class B2: virtual public B{……};
class D : public B1, public B2{ …… };
在查看D之前,我們先看一看單一虛擬繼承的情況。下面是一段在VC++2003下的測試程序:(因為VC++和GCC的內存而局上有一些細節上的不同,所以這裡只給出VC++的程序,GCC下的程序大家可以根據我給出的程序自己仿照著寫一個去試一試):
int** pVtab = NULL; Fun pFun = NULL; B1 bb1; pVtab = (int**)&bb1; cout << "[0] B1::_vptr->" << endl; pFun = (Fun)pVtab[0][0]; cout << " [0] "; pFun(); //B1::f1(); cout << " [1] "; pFun = (Fun)pVtab[0][1]; pFun(); //B1::bf1(); cout << " [2] "; cout << pVtab[0][2] << endl; cout << "[1] = 0x"; cout << (int*)*((int*)(&bb1)+1) <<endl; //B1::ib1 cout << "[2] B1::ib1 = "; cout << (int)*((int*)(&bb1)+2) <<endl; //B1::ib1 cout << "[3] B1::cb1 = "; cout << (char)*((int*)(&bb1)+3) << endl; //B1::cb1 cout << "[4] = 0x"; cout << (int*)*((int*)(&bb1)+4) << endl; //NULL cout << "[5] B::_vptr->" << endl; pFun = (Fun)pVtab[5][0]; cout << " [0] "; pFun(); //B1::f(); pFun = (Fun)pVtab[5][1]; cout << " [1] "; pFun(); //B::Bf(); cout << " [2] "; cout << "0x" << (Fun)pVtab[5][2] << endl; cout << "[6] B::ib = "; cout << (int)*((int*)(&bb1)+6) <<endl; //B::ib cout << "[7] B::cb = ";
其運行結果如下(我結出了GCC的和VC++2003的對比):
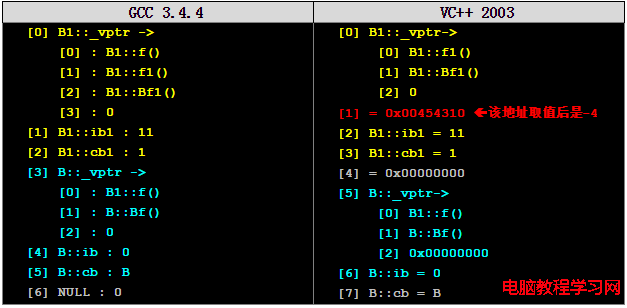
這裡,大家可以自己對比一下。關於細節上,我會在後面一並再說。
下面的測試程序是看子類D的內存布局,同樣是VC++ 2003的(因為VC++和GCC的內存布局上有一些細節上的不同,而VC++的相對要清楚很多,所以這裡只給出VC++的程序,GCC下的程序大家可以根據我給出的程序自己仿照著寫一個去試一試):
D d; pVtab = (int**)&d; cout << "[0] D::B1::_vptr->" << endl; pFun = (Fun)pVtab[0][0]; cout << " [0] "; pFun(); //D::f1(); pFun = (Fun)pVtab[0][1]; cout << " [1] "; pFun(); //B1::Bf1(); pFun = (Fun)pVtab[0][2]; cout << " [2] "; pFun(); //D::Df(); pFun = (Fun)pVtab[0][3]; cout << " [3] "; cout << pFun << endl; //cout << pVtab[4][2] << endl; cout << "[1] = 0x"; cout << (int*)((&dd)+1) <<endl; //???? cout << "[2] B1::ib1 = "; cout << *((int*)(&dd)+2) <<endl; //B1::ib1 cout << "[3] B1::cb1 = "; cout << (char)*((int*)(&dd)+3) << endl; //B1::cb1 //--------------------- cout << "[4] D::B2::_vptr->" << endl; pFun = (Fun)pVtab[4][0]; cout << " [0] "; pFun(); //D::f2(); pFun = (Fun)pVtab[4][1]; cout << " [1] "; pFun(); //B2::Bf2(); pFun = (Fun)pVtab[4][2]; cout << " [2] "; cout << pFun << endl; cout << "[5] = 0x"; cout << *((int*)(&dd)+5) << endl; // ??? cout << "[6] B2::ib2 = "; cout << (int)*((int*)(&dd)+6) <<endl; //B2::ib2 cout << "[7] B2::cb2 = "; cout << (char)*((int*)(&dd)+7) << endl; //B2::cb2 cout << "[8] D::id = "; cout << *((int*)(&dd)+8) << endl; //D::id cout << "[9] D::cd = "; cout << (char)*((int*)(&dd)+9) << endl;//D::cd cout << "[10] = 0x"; cout << (int*)*((int*)(&dd)+10) << endl; //--------------------- cout << "[11] D::B::_vptr->" << endl; pFun = (Fun)pVtab[11][0]; cout << " [0] "; pFun(); //D::f(); pFun = (Fun)pVtab[11][1]; cout << " [1] "; pFun(); //B::Bf(); pFun = (Fun)pVtab[11][2]; cout << " [2] "; cout << pFun << endl; cout << "[12] B::ib = "; cout << *((int*)(&dd)+12) << endl; //B::ib cout << "[13] B::cb = "; cout << (char)*((int*)(&dd)+13) <<endl;//B::cb
下面給出運行後的結果(分VC++和GCC兩部份)
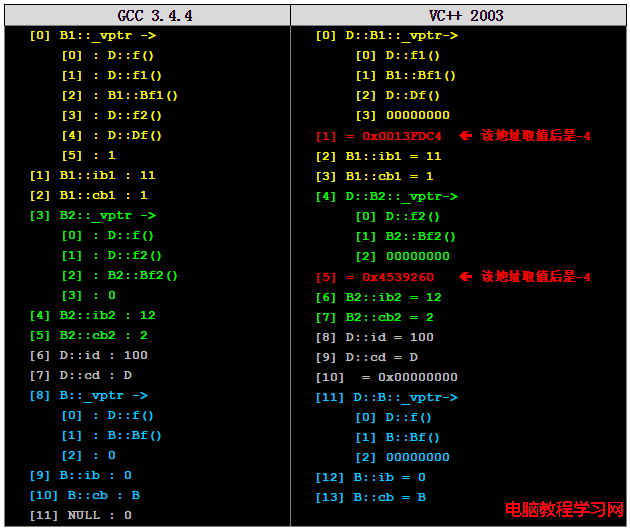
關於虛擬繼承的運行結果我就不畫圖了(前面的作圖已經讓我產生了很嚴重的厭倦感,所以就偷個懶了,大家見諒了)
在上面的輸出結果中,我用不同的顏色做了一些標明。我們可以看到如下的幾點:
1)無論是GCC還是VC++,除了一些細節上的不同,其大體上的對象布局是一樣的。也就是說,先是B1(黃色),然後是B2(綠色),接著是D(灰色),而B這個超類(青藍色)的實例都放在最後的位置。
2)關於虛函數表,尤其是第一個虛表,GCC和VC++有很重大的不一樣。但仔細看下來,還是VC++的虛表比較清晰和有邏輯性。
3)VC++和GCC都把B這個超類放到了最後,而VC++有一個NULL分隔符把B和B1和B2的布局分開。GCC則沒有。
4)VC++中的內存布局有兩個地址我有些不是很明白,在其中我用紅色標出了。取其內容是-4。接道理來說,這個指針應該是指向B類實例的內存地址(這個做法就是為了保證重復的父類只有一個實例的技術)。但取值後卻不是。這點我目前還並不太清楚,還向大家請教。
5)GCC的內存布局中在B1和B2中則沒有指向B的指針。這點可以理解,編譯器可以通過計算B1和B2的size而得出B的偏移量。
C++這門語言是一門比較復雜的語言,對於程序員來說,我們似乎永遠摸不清楚這門語言背著我們在干了什麼。需要熟悉這門語言,我們就必需要了解C++裡面的那些東西,需要我們去了解他後面的內存對象。這樣我們才能真正的了解C++,從而能夠更好的使用C++這門最難的編程語言。