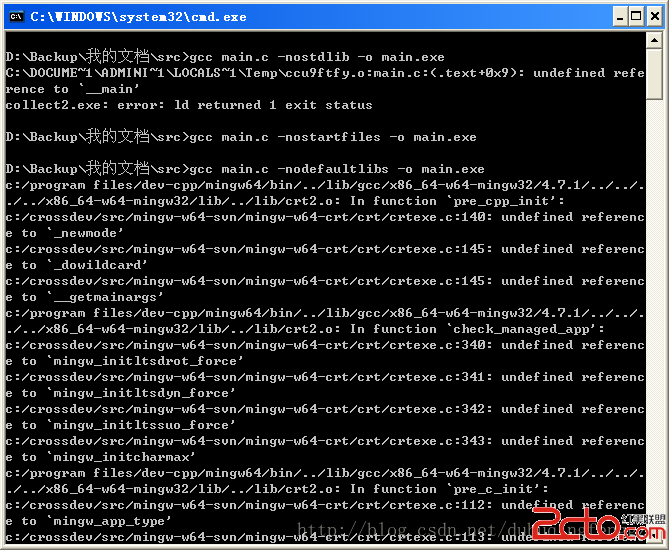
在解決Permutation問題時直接沒有思路,原因是對stl算法不了解。stl中有標准算法next_permutation(下一個排序)::在標准庫算法中,next_permutation應用在數列操作上比較廣泛.這個函數可以計算一組數據的全排列.但是怎麼用,原理如何,我做了簡單的剖析.首先查看stl中相關信息.函數原型:template<class BidirectionalIterator> bool next_permutation( BidirectionalIterator _First, BidirectionalIterator _Last );template<class BidirectionalIterator, class BinaryPredicate> bool next_permutation( BidirectionalIterator _First, BidirectionalIterator _Last, BinaryPredicate _Comp );兩個重載函數,第二個帶謂詞參數_Comp,其中只帶兩個參數的版本,默認謂詞函數為"小於".返回值:bool類型分析next_permutation函數執行過程:假設數列 d1,d2,d3,d4……范圍由[first,last)標記,調用next_permutation使數列逐次增大,這個遞增過程按照字典序。例如,在字母表中,abcd的下一單詞排列為abdc,但是,有一關鍵點,如何確定這個下一排列為字典序中的next,而不是next->next->next……若當前調用排列到達最大字典序,比如dcba,就返回false,同時重新設置該排列為最小字典序。返回為true表示生成下一排列成功。下面著重分析此過程:根據標記從後往前比較相鄰兩數據,若前者小於(默認為小於)後者,標志前者為X1(位置PX)表示將被替換,再次重後往前搜索第一個不小於X1的數據,標記為X2。交換X1,X2,然後把[PX+1,last)標記范圍置逆。完成。要點:為什麼這樣就可以保證得到的為最小遞增。(重點看的)從位置first開始原數列與新數列不同的數據位置是PX,並且新數據為X2。[PX+1,last)總是遞減的,[first,PX)沒有改變,因為X2>X1,所以不管X2後面怎樣排列都比原數列大,反轉[PX+1,last)使此子數列(遞增)為最小。從而保證的新數列為原數列的字典序排列next。明白了這個原理後,看下面例子:int main(){ int a[] = {3,1,2};do{ cout << a[0] << " " << a[1] << " " << a[2] << endl;} while (next_permutation(a,a+3)); return 0;}輸出:312/321 因為原數列不是從最小字典排列開始。所以要想得到所有全排列 int a[] = {3,1,2}; change to int a[] = {1,2,3}; 另外,庫中另一函數prev_permutation與next_permutation相反,由原排列得到字典序中上一次最近排列。所以int main(){ int a[] = {3,2,1};do{ cout << a[0] << " " << a[1] << " " << a[2] << endl;} while (prev_permutation(a,a+3)); return 0;}才能得到123的所有排列。+++++++++++++總結:1 2 3 4 依次列出下一排列後。找下一個排列的方法是如上原理。一句話重點看看吧。