假設我們寫了一個C代碼文件 code.c包含下面代碼:
int accum = 0;
int sum(int x, int y)
{
int t = x + y;
accum += t;
return t;
}
這是用echo命令輸入源碼的效果,簡單的就是最好的:)
 一、查看GCC生成的匯編代碼
一、查看GCC生成的匯編代碼
在命令行上用“-S”選項,就能看到C編譯器產生的匯編代碼:
#gcc -S code.c
注意:這裡是大寫的-S,如果用小寫gcc會說找不到main函數
會在當前目錄下生成code.s文件,直接打開即可
這段匯編代碼沒有經過優化:
.file "code.c"
.globl _accum
.bss
.align 4
_accum:
.space 4
.text
.globl _sum
.def _sum; .scl 2; .type 32; .endef
_sum:
pushl %ebp
movl %esp, %ebp
subl $4, %esp # 為局部變量t在棧幀上分配空間
movl 12(%ebp), %eax # %eax <- y
addl 8(%ebp), %eax # %eax <- x + y
movl %eax, -4(%ebp) # t <- x +y
movl -4(%ebp), %eax # %eax <- t
addl %eax, _accum # _accum <- t + _accum
movl -4(%ebp), %eax # %eax <- t
leave # 平衡堆棧: %esp <- %ebp , popl %ebp
ret
下面是使用“-O2”選項開啟二級優化的效果:
#gcc -O2 -S code.c
.file "code.c"
.globl _accum
.bss
.align 4
_accum:
.space 4
.text
.p2align 4,,15 # 使下一條指令的地址從16的倍數處開始,
.globl _sum # 最多浪費15個字節
.def _sum; .scl 2; .type 32; .endef
_sum:
pushl %ebp # 保存原%ebp
movl %esp, %ebp
movl 12(%ebp), %eax # %eax <- y
movl 8(%ebp), %edx # %edx <- x
popl %ebp # 恢復原%ebp
addl %edx, %eax # %eax <- x + y
addl %eax, _accum # _accum <- _accum + x + y
ret
GCC產生的匯編代碼有點難讀,它包含一些我們不關心的信息。所有以 "." 開頭的行都是指導匯編器和鏈接器的命令,稱為“匯編器命令”。
代碼中已經除去了所有關於局部變量名或數據類型的信息,但我們還是看到了一個對全局變量_accum的引用,這是因為編譯器還不能確定這個變量會放在存儲中的哪個位置。
二、用GDB查看目標文件的字節表示
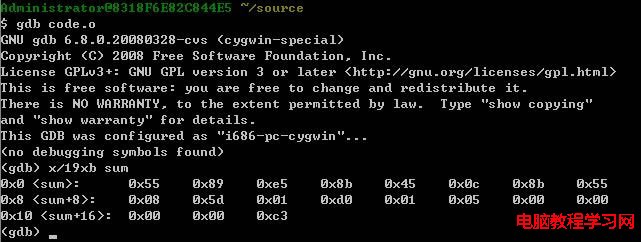
首先,我們用反匯編器來確定函數sum的代碼長度是19字節。然後我們在文件code.o上運行GNU調試工具GDB,輸入命令:
(gdb) x/19xb sum
這條命令告訴GDB檢查(簡寫為"x")19個以十六進制格式表示的字節。
 三、反匯編目標文件
三、反匯編目標文件
在Linux系統中,帶 "-d" 命令行選項調用OBJDUMP可以完成這個任務:
#objdump -d code.o
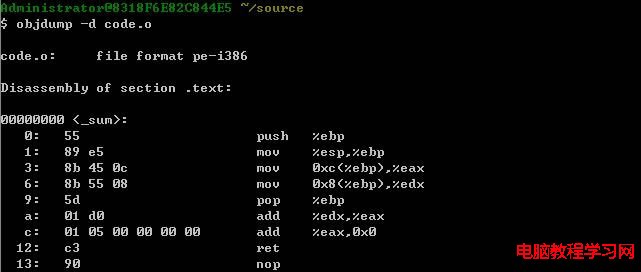
從這裡可以看出函數sum的代碼長度正好是19字節。
四、生成實際可執行的代碼
這需要對一組目標文件運行鏈接器,而這一組目標代碼文件中必須包含有一個Main函數。在 main.c 中有這樣的函數:
int main()
{
return sum(1,2);
}
然後,我們用如下方法生成可執行文件:
#gcc -O2 -o prog code.o main.c
再反匯編:
objdump -d prog
00401050 <_sum>:
401050: 55 push %ebp
401051: 89 e5 mov %esp,%ebp
401053: 8b 45 0c mov 0xc(%ebp),%eax
401056: 8b 55 08 mov 0x8(%ebp),%edx
401059: 5d pop %ebp
40105a: 01 d0 add %edx,%eax
40105c: 01 05 10 20 40 00 add %eax,0x402010
401062: c3 ret
這段代碼與code.c反匯編產生的代碼幾乎完全一樣。一個主要的區別是左邊列出的地址不同。第二個不同之處在於鏈接器終於確定了存貯全局變量accum的地址。地址由原來的0x0變成了現在的0x402010